Amazon Web Services ブログ

Amazon FSx for OpenZFS がデータ移動不要の Amazon S3 アクセスをサポート
6 月 25 日より、Amazon S3 Access Points を Amazon FSx for Ope […]

AWS re:Inforce 2025 で 3 つの主要セキュリティ機能を発表、お客様のセキュリティ対策の簡素化とスケーリングを支援
AWS re:Inforce で発表された 3 つの主要セキュリティ機能について紹介します。AWS Security Hub は重要なセキュリティ問題の一元管理を実現し、AWS Shield は事前にネットワークセキュリティの弱点を発見して保護します。また Amazon GuardDuty は拡張脅威検出機能を EKS コンテナ環境にも拡大し、複雑な攻撃パターンを特定できるようになりました。これらの機能により、お客様は生成 AI 時代の新たな脅威に対応しながら、セキュリティ管理を簡素化し、より包括的な保護を実現できます。
【開催報告】ハイテク製造・ヘルスケア・ライフサイエンス業界向けセキュリティインシデント疑似体験 GameDay
はじめに みなさんこんにちは。ソリューションアーキテクトの光吉です。2025 年 5 月 20 日にヘルスケア […]

【開催報告 & 資料公開】Apache Iceberg on AWS ミートアップ開催報告
2025 年 5 月 14 日に「Apache Iceberg on AWS ミートアップ ~話題のIcebergをAWSで徹底活用~」と題したイベントを開催しました。ご参加いただきました皆様には、改めて御礼申し上げます。
本セミナーでは、AWS における Iceberg の活用についてさまざまな角度からご紹介しました。Iceberg 活用の全体像に加えて、マネージドな Iceberg のストレージである Amazon S3 Tables Bucket、既存データレイクからの移行における考え方、リアルタイムデータ処理を実現するストリーミングワークロードの実装方法、更には機械学習における活用まで、幅広いトピックをご紹介しました。本ブログでは、その内容を簡単にご紹介しつつ、発表資料を公開致します。
すでに Iceberg を活用されている方も、これからはじめる方も是非ご確認下さい!

【開催報告】 消費財業界向け Amazon Q in QuickSight ワークショップ ~生成 AI で加速するインテリジェントデータ分析~
2025 年 6 月 9 日、AWS 目黒オフィスにて消費財業界向け Amazon Q in QuickSig […]

Amazon Q Developer から Claude Sonnet 4 がアクセス可能に
Amazon Q Developer が CLI で Claude Sonnet 4 のサポートを開始し、追加コストなしで高度なコーディングと推論機能を開発プロセスに導入できるようになりました。この最新モデルは、SWE-bench でのエージェント型コーディングにおいて最先端の 72.7% のスコアを記録しており、コーディングにおいて優れた性能を発揮しています(詳細については Claude 4 の発表 をご覧ください)。強化されたコーディングと推論機能により、複雑なコードの分析、日常的な開発タスクの最適化、バグ修正の実装、bash コマンドの実行、新機能の開発を、高速なフィードバックループとより正確な応答で支援します。
Amazon Nova 理解モデルにおけるパフォーマンスの最適化
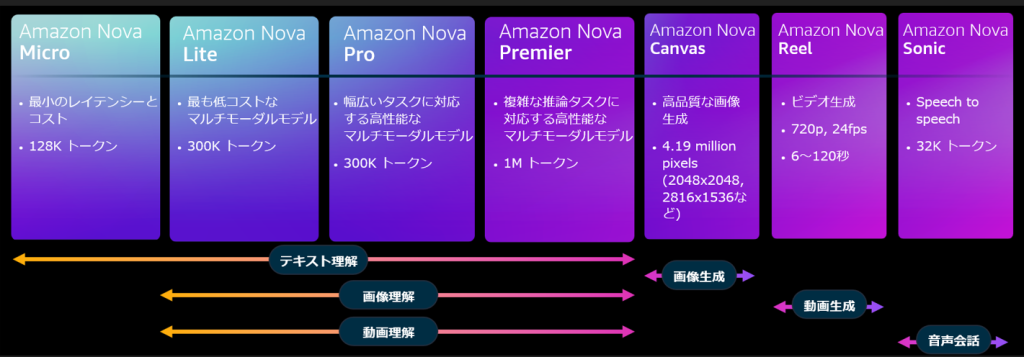
Amazon Nova は、Amazon Bedrock で利用できる、最先端のインテリジェンスと業界をリードするコストパフォーマンスを実現する新世代の基盤モデルで、4 つの理解モデル、2 つのクリエイティブコンテンツ生成モデル、1 つの Speech-to-Speech モデルが含まれます。Amazon Nova 理解モデルは、テキスト、画像、動画入力を受け入れてテキスト出力を生成するモデルで、機能、品質、スピード、コストについて幅広い選択肢を提供します。この記事では、Amazon Nova 理解モデルのプロンプトエンジニアリングのベストプラクティスに従って、パフォーマンスを最適化する方法を紹介します。

Amazon Connect Global Resiliency で実現するマルチリージョン高可用性
AWS は2025年6月30日、Amazon Connect の可用性を高める機能「Amazon Connect Global Resiliency (ACGR)」を日本で一般公開しました。これにより、アジアパシフィック (東京) リージョンで Amazon Connect インスタンスをご利用されているお客様が、AWS アジアパシフィック (大阪) リージョンのインスタンスに設定を同期することで、地域的な災害や障害が発生した場合のダウンタイムを最小限に抑えることができます。また、コンタクトセンターの可用性を高める場合もデータを日本国内に保持することができます。
本ブログでは Amazon Connect が備えている信頼性について改めて解説した上で、ACGR の機能概要と利用にあたりお客様にご理解いただきたい事項、さらに日本で利用可能な ACGR の機能についてご紹介します。

週刊AWS – 2025/6/23週
Amazon WorkSpaces Core マネージドインスタンスによる VDI 移行の簡素化を発表、カスタマーカーボンフットプリントツールに地域ベースの排出量データが追加、Amazon SageMaker で Git から S3 への自動同期がサポート、Amazon Braket が IQM Garnet で動的な回路機能を追加、Amazon Q の Java 開発者向けアップグレード変換 CLI が一般提供開始など

【GENIAC】グローバル生成AIモデルプロバイダ訪米記録
2025年5月12日〜16日、経済産業省が推進するプログラム『Generative AI Accelerato […]