Amazon Web Services ブログ

【寄稿】SIEMからデータ基盤へ – 三井物産デジタルアセットマネジメントのAWS Security Lake活用事例
こんにちは。ソリューションアーキテクトの松本 敢大です。三井物産デジタル・アセットマネジメント株式会社(以下、 […]

ポスト量子 TLS を Python で実装・検証する方法
このブログでは、Python アプリケーションでポスト量子 TLS をテストする方法を紹介します。OpenSSL 3.5 をインストールした Dockerfile を使用して、boto3、requests、Python の socket/ssl モジュールによるポスト量子ハイブリッド TLS 接続をテストする手順を解説します。また、Wireshark を使用した TLS ハンドシェイクの確認方法も説明し、ポスト量子ハイブリッド TLS 移行に備えたネットワーク検証の開始を支援します。
AWS KMS、ACM、Secrets Manager で ML-KEM ポスト量子 TLS をサポート開始
AWS Key Management Service (AWS KMS)、AWS Certificate Manager、AWS Secrets Manager で ML-KEM ベースのハイブリッドポスト量子鍵合意のサポートが開始されました。量子コンピューティングの進歩による「harvest now, decrypt later (今収集して、後で復号)」攻撃の脅威に備え、TLS 接続のセキュリティを強化します。AWS SDK for Java v2 でのベンチマーク結果では、TLS 接続の再利用を有効にした場合、パフォーマンスへの影響はわずか 0.05% にとどまります。CRYSTALS-Kyber から ML-KEM への移行方法と、今後の AWS 全体でのポスト量子暗号展開計画について解説します。
ポスト量子暗号への移行におけるセキュアな TLS 接続の仕組みとクライアント設定ガイド
AWS はポスト量子暗号への移行を進めており、TLS 1.3 などのプロトコルにポスト量子ハイブリッドキー交換を導入しています。このブログでは、AWS の責任共有モデルにおけるお客様の役割と、耐量子アルゴリズムを有効にする方法を解説します。AWS サービスは、クライアントが耐量子アルゴリズムのサポートをアドバタイズしている場合、多少の遅延が発生してもポスト量子ハイブリッドキー交換を優先します。AWS Key Management Service (AWS KMS)、AWS Certificate Manager、AWS Secrets Manager、AWS Transfer Family での具体的な検証方法も紹介します。

Amazon RDS for SQL Server で CPU を最適化する設定
この投稿では、新規および既存の Amazon RDS インスタンスの両方において、パフォーマンスを維持しながらライセンス費用を削減する可能性がある CPU 最適化機能の実装方法を、パフォーマンスベンチマーク結果とコストへの影響とともに説明します。
Amazon RDS for SQL Server インスタンスのデータベース名の可視性制御
この投稿では、可視性レベルでのテナント分離を実装し、各テナントが自身のリソースにはアクセスできる一方で、他の顧客のデータベース名は参照できないようにする方法を紹介します。

エンタープライズにおける AI エージェント: Amazon Bedrock AgentCore を活用したベストプラクティス
本記事では、Amazon Bedrock AgentCore を活用してエンタープライズ向け AI エージェントを構築するための 9 つのベストプラクティスを紹介します。Amazon Bedrock AgentCore は、AI エージェントの作成、デプロイ、管理を大規模に行うために必要なサービスを提供するエージェンティックプラットフォームです。初期のスコーピングから組織全体へのスケーリングまで、すぐに実践できるガイダンスを幅広くカバーしています。

月刊 AWS 製造 2026年2月号
みなさん、こんにちは。AWS のインダストリーソリューションアーキテクトの山本です。 このブログでは開催予定の […]

Amazon Connect アップデート まとめ – 2026年1月
こんにちは、Amazon Connect ソリューションアーキテクトの梅田です。2025 年 11 月・ 12 […]
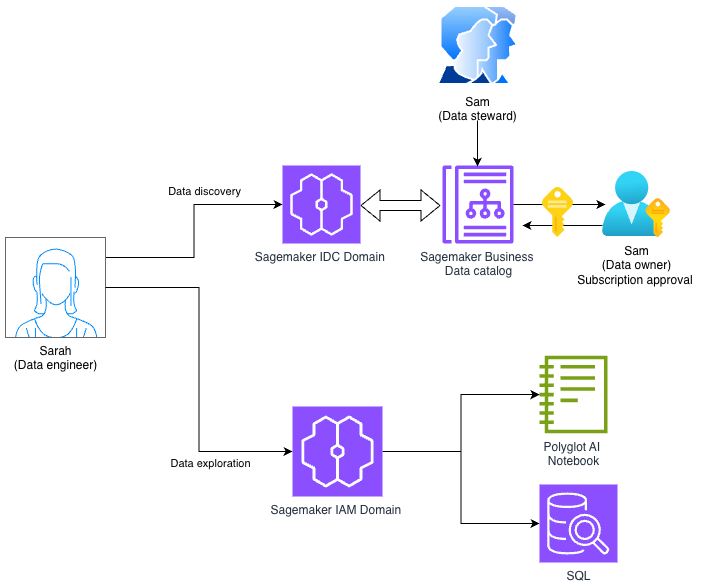
Amazon SageMaker Unified Studio の Identity Center (IDC) ベースドメインと IAM ベースドメインを併用する
Amazon SageMaker Unified Studio で、IDC ベースドメインと IAM ベースドメインの 2 種類のドメイン構成が利用可能になりました。本記事では、IAM ロールの再利用と属性ベースのアクセス制御 (ABAC) を使って、IDC ベースドメインの既存のガバナンスフレームワークを維持しながら、IAM ベースドメインの最新開発ツールを活用する方法を紹介します。