Amazon Web Services ブログ

AWS Lambda と Amazon DynamoDB を使用したクロスアカウントストリーム処理の簡素化
本記事は 2026 年 02 月 09 日 に公開された “Simplify cross-acco […]
Terraform の新機能: Amazon DynamoDB のグローバルセカンダリインデックスのドリフトを管理する
Amazon DynamoDB のグローバルセカンダリインデックス (GSI) のキャパシティを Terraf […]

週刊AWS – 2026/2/2週
CloudFront が相互 TLS サポート開始、Multi-party approval で OTP 認証が必須に、STS が外部 IdP の詳細クレーム検証に対応、Lightsail でメモリ最適化インスタンス提供開始、SageMaker JumpStart で DeepSeek OCR など 3 モデル追加、IAM Identity Center が複数リージョン対応、Management Console でアカウント名表示が可能に、DynamoDB グローバルテーブルが複数アカウント間レプリケーション対応、EC2 と VPC でセキュリティグループの関連リソース表示、Bedrock で構造化出力が利用可能に、Claude Opus 4.6 が Bedrock で利用可能に、WorkSpaces が Graphics G6/Gr6/G6f バンドル開始、Network Firewall が新たな料金削減を発表、Bedrock AgentCore Browser がブラウザプロファイルをサポート開始等
【寄稿】CO2 排出量可視・削減サービス「e-dash」を支えるサーバーレスアーキテクチャと IaC 戦略
こんにちは、AWS ソリューションアーキテクトの松本 敢大です。 本日は、三井物産発の環境系スタートアップである e-dash 株式会社様が提供する CO2 排出量可視化・削減サービスプラットフォーム「e-dash」のシステム構築事例をご紹介します。e-dash 株式会社 プロダクト開発部部長の佐藤様、プロダクト開発部の伊藤様、竹内様に、AWS を活用したモダンなアプリケーション開発の取り組みについてお話を伺いました。

週刊生成AI with AWS – 2026/2/2 週
週刊生成AI with AWS、AI-DLCと実用化事例が充実の2026年2月3日週号 – 11社合同AI-DLC Unicorn Gymの開催報告、熊本中央病院様の生成AI環境構築事例を紹介。また、KiroでのOpus 4.6対応、AIを活用したゲーム制作、AWS DevOps Agent開発の教訓、オブザーバビリティエージェント、フィジカルAI、鉄道技術展出展報告などのブログ記事も。サービスアップデートではClaude Opus 4.6のBedrock対応、Structured Outputs、Browser Profiles、SageMaker JumpStartでの新モデル追加をはじめとする8件のアップデートを紹介。

Amazon、Nova モデル強化に向けプライベート AI バグバウンティプログラムを開始
Amazon は、Amazon Nova 基盤モデルを含む AI モデルおよびアプリケーションを対象としたプライベート AI バグバウンティプログラムを開始しました。このプログラムでは、セキュリティ研究者やパートナー大学の専門家と連携し、プロンプトインジェクションやジェイルブレイク、CBRN 関連の脅威の検出など重要な領域でモデルをテストします。参加者は有効な脆弱性の報告に対して 200 ドル から 25,000 ドル の報奨金を獲得でき、次世代の AI セキュリティ研究者の育成も目指しています。

AWS Transform custom: AI 駆動 Java モダナイゼーションで技術的負債を削減
今日の急速に進化するソフトウェア環境において、Java アプリケーションの保守とモダナイゼーションは、多くの組織が直面する重要な課題です。新しい Java バージョンがリリースされ、ベストプラクティスが進化するにつれて、効率的なコード変換の必要性がますます重要になっています。この記事では、Java アップグレード用の AWS Transform custom のすぐに使える変換を活用する方法について説明します。この記事の最後までに、変換プロセスを完全に制御しながら、これらの標準化された変換を使用して Java アプリケーションを効率的にモダナイズする方法を理解できるようになります。

AI を活用したゲーム制作: 静的なコンセプトからインタラクティブなプロトタイプへ
AI を活用することで、ゲーム開発の初期段階でコンセプトをインタラクティブにし、数分でプレイ可能なプロトタイプを作成できます。AWS re:Invent 2025 で紹介する Agentic Arcade は、マルチエージェントオーケストレーション、プログラマティックアセット生成、セマンティック検索を組み合わせ、開発サイクルの早い段階で創造的な方向性を探索し検証する方法を示します。

VAMS における NVIDIA Isaac Lab を使用した GPU アクセラレーション型ロボットシミュレーショントレーニング
オープンソースの Visual Asset Management System (VAMS) が NVIDIA Isaac Lab との統合により、ロボットアセット向けの GPU アクセラレーション強化学習に対応しました。このパイプラインでアセット管理ワークフローから直接 RL ポリシーのトレーニングと評価ができ、AWS Batch でスケーラブルな GPU コンピューティングを活用できます。
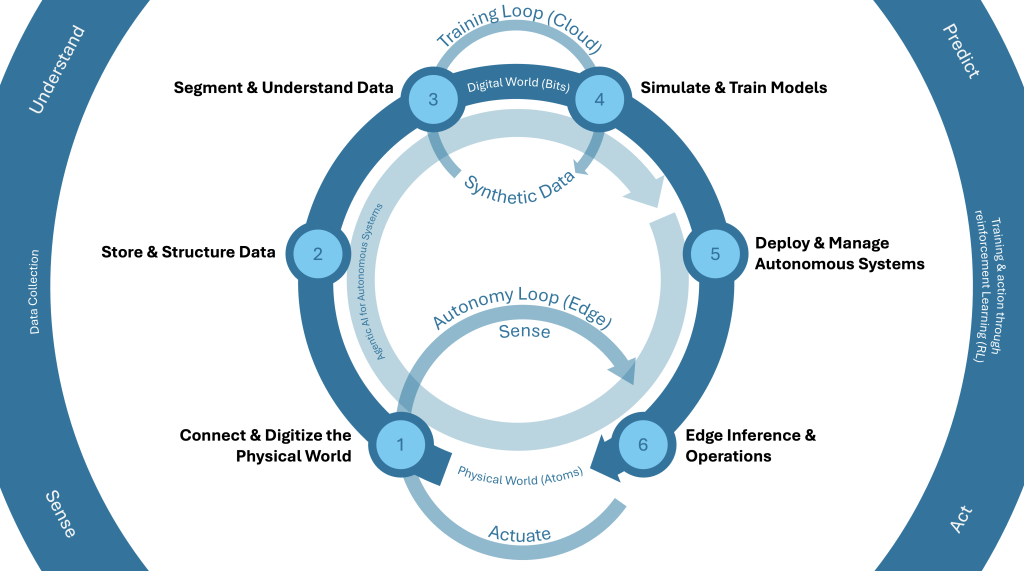
フィジカル AI: 自律型インテリジェンスに向けた次なる基盤を築く
AWS の Physical AI フレームワークは、デジタル世界と物理世界を橋渡しする自律システムを構築するための包括的なアプローチです。物理世界の接続とデジタル化、データの保存と構造化、データのセグメント化と理解、シミュレーションとトレーニング、デプロイと管理、エッジ推論と運用の 6 つの相互接続された機能を通じて、継続的な学習サイクルを作り出し、自律型経済への移行を支援します。