AWS Partner Network (APN) Blog
Accelerate Your Life Sciences Data Journey with Accenture Intelligent Data Foundation on AWS
By Nayanjyoti A. Paul, Sr. Manager, Applied Intelligence – Accenture
By Atish Ray, MD, Applied Intelligence – Accenture
By Nada Reinprecht, Partner Solutions Architect – AWS
By Sachin Thakkar, Partner Solutions Architect – AWS
 |
| Accenture |
 |
Increasing penetration of analytics in the life sciences industry—primarily using predictive and prescriptive analysis to estimate future trends and outcomes—is expected to drive significant growth for businesses in the coming years.
The impact of social media is being used to drive awareness and source data, which further enhances patient engagement. This, too, is expected to drive the demand for analytical solutions in the market.
In addition, the growing demand for improving patient outcomes while simultaneously reducing healthcare expenditure using analytical solutions is boosting market growth across the globe.
In this post, we describe the life sciences data and analytics accelerator which enables customers to respond to these challenges and use data for their competitive advantage. Particular focus is given to the commercial domain and use of analytics to increase customer engagement and optimize sales and marketing.
Intelligent Data Foundation (IDF) is a proven asset within Accenture, an AWS Premier Consulting Partner and leading, global professional services company. IDF was developed with the idea of making data and analytics pipelines automated, reusable, and repeatable. It has been deployed successfully over the years in financial, retail, healthcare, and other verticals.
Accenture has collaborated on multiple projects associated with life sciences over the past 12 months; IDF was involved in most of the projects to help implement the foundational data and analytics platform.
When it came to providing life sciences-specific solutions (domain-specific on top of the foundational layer), Accenture found its teams repeating the same work across multiple customers. This post focuses on how Accenture has evolved IDF to include a life sciences domain-specific repeatable module that helps Amazon Web Services (AWS) customers with sustainable, packaged, and validated solutions.
Why Do We Need Accelerator?
Many life sciences organizations find it challenging to move forward with their data and analytics journey. They can spend on average several months to a year building production-scale enterprise data lakes and even longer to activate life sciences-specific use cases.
There is a need to reuse the gained experiences across these projects and provide an accelerator to the life sciences industry so they can innovate and build faster.
The pandemic has further stressed the necessity of life sciences organizations to improve sales through digital channels such as email, SMS, voice, and mobile experiences like push. These efforts are supported by intelligence created from a variety of available data, including insurance claims, agent notes, and deidentified patients’ health records.
This intelligence is empowered by pre-built machine learning models such as the model for customers’ segmentation or targeting, to determine the best and most productive marketing communication with customers. This is important as even 1% of increased sales can correspond to millions of improvements in revenue.
Accenture’s Intelligent Data Foundation for Life Sciences (IDF for LS) is an industrialized version of the Intelligent Data Foundation with pre-built components developed based on years of experience solving similar challenges.
The pre-built components include a centralized user interface (UI), dedicated connectors, sophisticated and configurable data pipeline, and analytics module for a 360-degree view of Health Care Professional (HCP). This module supports a variety of HCP use cases such as segmentation, targeting, penetration and productivity, self-service, and marketing analytics. IDF for LS also includes the content processing engine pre-built component for processing of text, audio, video, and other data formats.
One of the pre-built components is the integration with Amazon HealthLake that allows for more data types to be ingested into HealthLake and obtain enriched data for downstream analytics. There is also a pre-built component for Amazon Kendra, allowing for sophisticated natural language processing (NLP)-based search.
The IDF for LS accelerator is not an independent entity but an extension of the core Intelligent Data Foundation product for Accenture’s life sciences customers. It’s available as an add-on to provide better and quicker delivery of life science use cases.
Key Benefits of IDF for Life Sciences
Key benefits from this accelerator include:
- Provides a jump-start for building end-to-end data solutions by re-using the pre-built data pipeline, artificial intelligence (AI) and machine learning (ML), and visualization components.
- Enables data-driven decision making such as driving an effective customer outreach, as IDF for LS is powered by multiple pre-built life sciences use cases.
- Offers processing of unstructured data (videos, audios, images, hand writing, and others) and extraction of content for medical domain-specific use cases by built-in sophisticated content processing engine.
- Adds power of Amazon HealthLake analytics by integration using built-in adapters.
- Reduces cost and time of development, as well as development risk using pre-built components which are based on experience with multiple previous implementations.
What is IDF from Accenture?
Intelligent Data Foundation is a proven and patented asset from Accenture that provides a one-stop solution to build, deploy, create, and automate data engineering pipelines in AWS data strategy projects.
IDF provides best-of-breed capabilities of AWS technology and Accenture experience in delivering similar projects across domains. The following diagram provides insight into the IDF ecosystem.
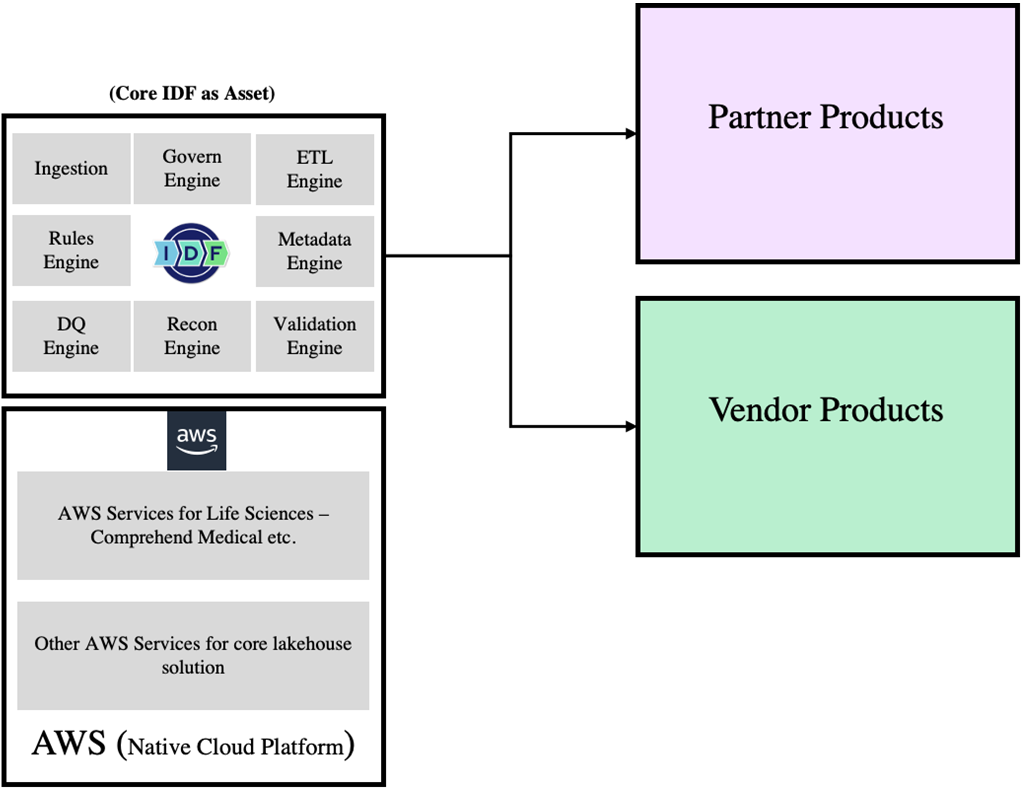
Figure 1 – How IDF sits on AWS and collaborates with other ecosystem tools.
What is IDF for Life Sciences?
IDF has been around for a while, and Accenture has implemented more than 25 end-to-end data strategy projects (greenfield) based on IDF alone.
However, as the team at Accenture has matured, so have the life sciences customers. With IDF delivering the “foundational” capabilities, customers are asking for domain-specific solutions. It was a natural and logical progression for IDF to introduce IDF for LS.
The diagram in Figure 2 provides an overview of the IDF for LS architecture blueprint. The guiding principle of this architecture is the integration with AWS-native services and how it uses the power of AI/ML to make it cutting edge.
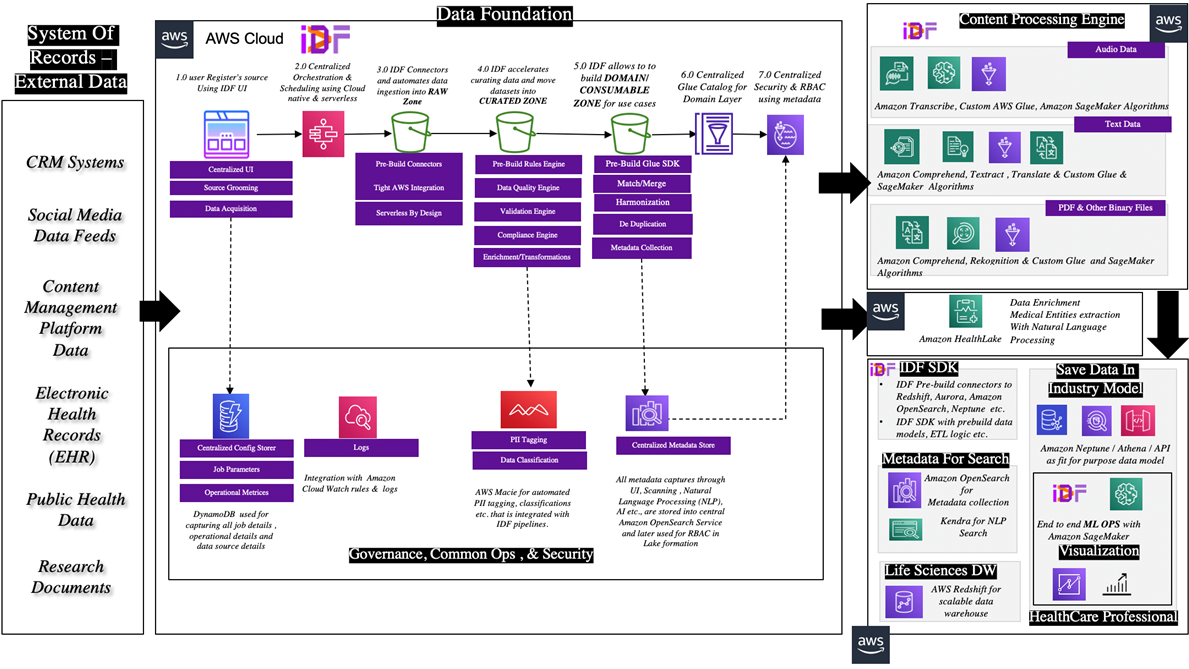
Figure 2 – IDF for life sciences solution blueprint.
In this blueprint, the whole lakehouse is divided into three major chunks.
- First is the data foundation that remains agnostic of domain. IDF’s core pieces help in building the data plumbing through a series of engines that process, validate, enrich, and standardize the incoming data by using AWS services.
- The second piece is the content processing engine that provides a framework that processes unstructured data and contextualizes the life sciences solution.
- Lastly, the business section (purpose-driven) provides the business value through templates for HCP 360, ML models, and others.
As a strategy to introduce IDF for LS as an add-on, Accenture provides these capabilities:
- Content processing engine for life sciences to address unstructured data (using AI/ML).
- Fast Health Interoperability Resources (FIHR) and Health Level Seven International (HL7) data parser for integration with Amazon HealthLake.
- Extract, transform, load (ETL) and ML blueprints around HCP 360 using Amazon SageMaker models on segmentation.
- NLP-based combined search catalog.
Content Processing Engine
Content Processing Engine (CPE) is a framework Accenture has designed specifically for life sciences projects to work with unstructured data from various sources such as scan images, prescriptions, and handwritten notes.
The core of the CPE module is to extract meaningful entities from the datasets and organize them in a ready to consume and searchable way.

Figure 3 – Content Processing Engine high-level architecture.
Amazon HealthLake Integration
Amazon HealthLake is a HIPAA-eligible service that enables healthcare providers, health insurance companies, and pharmaceutical companies to store, transform, query, and analyze health data at petabyte scale.
Integrated medical NLP then helps customers transform the raw medical text data using specialized ML models that have been trained to understand and extract meaningful information from unstructured healthcare data.
With integrated medical NLP, you can automatically extract entities (medical procedures and medications), entity relationships (medication and its dosage), entity traits (positive or negative test result, time of procedure), and protected health information (PHI) data from your medical text.
IDF for LS and the HealthLake integration module provides the pre-built FIHR and HL7 data parsers, enabling a wider range of data sources to be ingested and processed by HealthLake advanced analytics services.
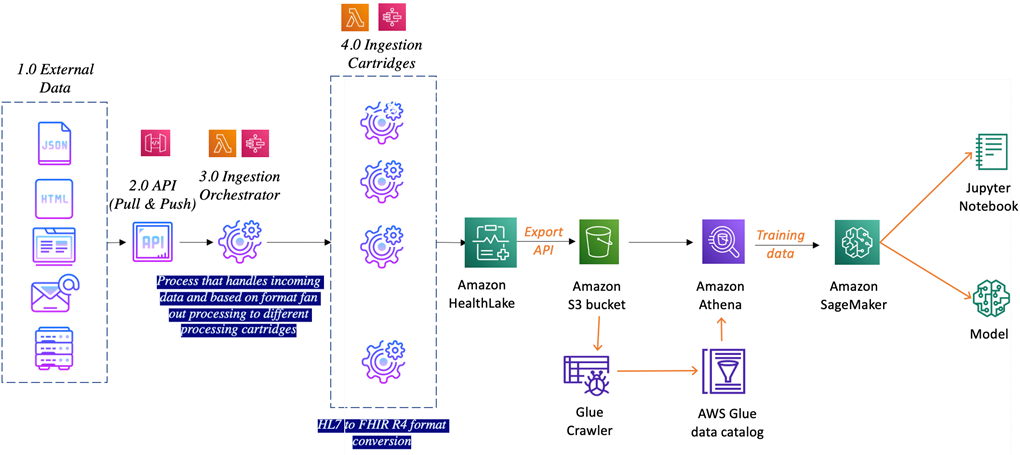
Figure 4 – Amazon HealthLake integration high-level architecture.
HCP 360 Use Cases and Implementation
HCP 360 is used to measure drug-related performance in terms of how many practitioners have been targeted and how many are prescribing the drug.
Typical use cases of HCP 360 are:
- Penetration: It helps the pharma brand manager or Regional Business Director (RBD) assess how many HCPs are writing their respective drug and intervention in the market. The intervention is measured through penetration across geography.
- Productivity: This helps the pharma brand manager or RBD assess how many prescriptions (Rx) per HCP of their respective drug has been prescribed in the market. The rate of Rx per HCP is measured through penetration across geography.
By leveraging HCP 360, attributes from different data sources are accessed in one place, so pharma companies can leverage the attributes of Rx, calls, and marketing tactics to develop HCP segments using K-Means methodology.
The segments will help to identify which of their HCPs are:
- Early adopters who starts prescribing as soon as a brand is launched or extended.
- Shruggers who are indifferent to the brand and reluctant to prescribe.
- Innovators who are always ready to experiment with different options of treatment.
- Loyalists who are always loyal to brand they have been prescribing for a particular treatment.
Segments are important for any pharma company to look upon their prospective HCPs. Refining the segments by using and quickly accessing different attributes from different sources helps build robust segments so pharmaceutical companies can optimize their targeting strategy.
The section below provides a glimpse of the IDF for LS templates and features that are available out of the box. We took some real-world examples of datasets and executed analytical pipelines and models to understand the segmentation and penetration based on a common HCP 360 model. The images below are taken from the outcome of the models to showcase how IDF provides the segmentation and analysis overview.
For this example, we took five third-party data sources and executed pre-defined pipelines to build a common 360 model. From the common model, we executed Amazon SageMaker templates to understand how total Rx are sold by region, total units sold by product category, and total count of units sold by division and by territory.
These insights provide an understanding of how drugs are sold; these are also used as attributes by other pipeline models to provide a breakdown of segments by provider, payer, driver, practitioner, and more. The idea is to provide an “art of possible” to showcase how some pre-built pipelines and models can help customers understand the life sciences space and jump-start a data strategy project.
Here are snapshots of an analytics dashboard executed on a 360-domain model to provide a summary of Rx sold by different regions and Product IDs.

Figure 5 – Summary of prescription (Rx) sold by different regions and Product IDs.
Next, you can see snapshots of an analytics dashboard executed on a 360-domain model to provide a summery of total sales by division and region.
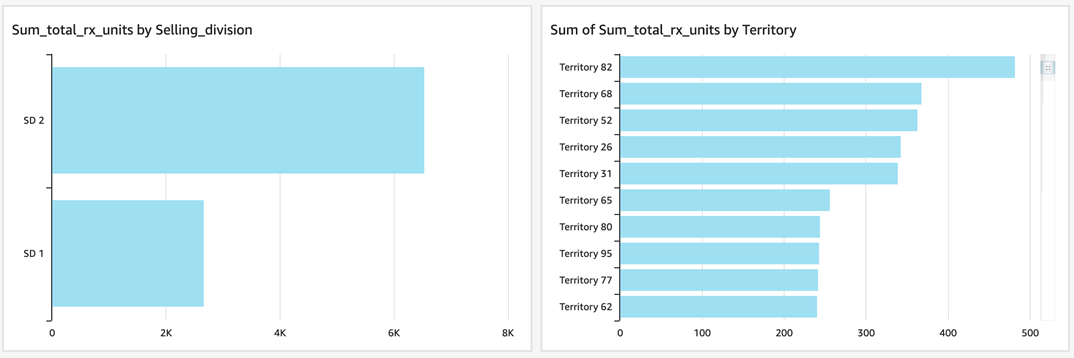
Figure 6 – Summary of total sales by division and region.
Finally, here’s are snapshots of analytics segmentation information and key decision points based on IDF for LS pre-build ML model.

Figure 7 – Analytics segmentation and key decision points based on IDF for LS pre-build ML model.
NLP-Based Combined Search Catalog
Apart from building the CPE from the ground up using AWS services and custom code, Accenture integrated Amazon Kendra into IDF for LS for semantic search. This refers to searching for information by meaning, using natural language understanding (NLU) and various predefined ML models.
In a world of unstructured content, semantic search has a major advantage in search accuracy and relevancy. Using Amazon Kendra, life sciences companies can efficiently search through large corpus of documents, such as scientific papers or internal research documents stored in a data lake.
Pharma manufacturers can quickly find and access the standard operating procedures (SOP) to improve compliance, safety, and success of continuous manufacturing facilities, where existing methods can take hours to track down and run through the required SOP.
This increase employees’ productivity and simplifies compliance, thus reducing the costs and risks associated with manual processes.
Conclusion
Accenture’s Intelligent Data Foundation for Life Sciences (IDF for LS) is an industry data accelerator with pre-built components that allows building and enhancing customer data solutions faster.
It includes a readily available and industry-wide Health Care Professional (HCP) 360 model template which supports HCP-related commercial use cases. Another module of IDF for LS is the Content Processing Engine (CPE) which empowers customers to process life sciences structured and unstructured data (audio, video and document) such as agent notes, patient data and others, and extract content for domain-specific use cases.
The IDF for LS also utilizes the rich intelligence of the Amazon HealthLake analytics against the data in IDF and offers semantic search capabilities.
IDF for LS is an industrialized version of Intelligent Data Foundation. You can learn more about Accenture data lake accelerators, including the generic version of IDF, in this APN Blog post.
.

.
Accenture – AWS Partner Spotlight
Accenture is an AWS Premier Consulting Partner and MSP. A global professional services company that provides an end-to-end solution to migrate to and manage operations on AWS, Accenture’s staff of 569,000+ people includes more than 20,000 AWS-trained technologists with more than 12,000 AWS Certifications.
Contact Accenture | Partner Overview
*Already worked with Accenture? Rate the Partner
*To review an AWS Partner, you must be a customer that has worked with them directly on a project.