AWS Partner Network (APN) Blog
How Accenture Accelerates Building and Monetizing Production-Scale Data Lakes Natively on AWS
By Soonam Jose, Sr. Partner Solutions Architect – AWS
By Jon Steinert, Daniel Grube, and Steven Cox, ARTEMIS – Accenture
By Nayanjyoti Paul, Intelligent Data Foundation – Accenture
 |
| Accenture |
 |
The total amount of data created, captured, copied, and consumed globally has been increasing at an unprecedented rate.
Global data creation is projected to grow to more than 180 zettabytes by 2025, and a lot of that data still lives in silos that make it cost-prohibitive and inefficient for businesses to perform analytics at scale.
To overcome these challenges, organizations are looking for a highly scalable, available, secure, and flexible data store, or a data lake that can handle extremely large data sets.
Organizations benefit from having more than just a data lake. Lake House architecture will enable them to easily move data between the data lake and various components in the analytics landscape. This can happen in all directions with unified governance, allowing companies to harness the true power of data with analytics.
Unlocking data intelligence and implementing modern data architectures can turn organizations into data-driven enterprises and help drive business outcomes. It also results in automated data harvesting, improved data accuracy, data-driven analytics, improved customer experience, and better employee satisfaction.
In this post, we’ll walk you through how Amazon Web Services (AWS) and Accenture are helping customers transform to data-driven organizations through Accenture’s Data Lake Accelerator built on AWS.
Specifically, we will explain how the Data Lake-Ops component ARTEMIS minimizes the time and effort required to set up a data lake, and how the Data-Ops component Intelligent Data Foundation (IDF) accelerates deployment of governed data supply chains, enabling a range of data services.
Accenture is an AWS Premier Consulting Partner and leading, global professional services company with the AWS Data and Analytics Competency. Accenture is also a member of the AWS Managed Service Provider (MSP) and Well-Architected Partner Programs.
Why Do We Need an Accelerator?
Despite data and analytics gradually shifting to a core business function, many organizations find it challenging to move forward with their cloud analytics journey.
For enterprises, building production-scale data lakes following the Lake House architecture pattern involves several moving parts, such as security, networking, Active Directory integration, operations, data onboarding, data engineering, and Data-Ops.
The functions are typically handled by teams across the organization, and success may be perceived differently by various stakeholders, and concerns related to security and risks may hinder progress.
Although it may be straightforward to complete a simple data lake proof-of-concept (PoC), customers are spending on average several months to a year building production-scale data lakes that address the needs of their stakeholders.
To build an enterprise-scale data lake, we need to consider core data strategy components; for example, data supply chains addressing a variety of data consumption patterns and personas; data services powering business consumption through multiple channels; data research and exploration; and operationalizing machine learning-powered applications.
Having recognized the aforementioned challenges faced by customers, AWS and Accenture collaborated to build an accelerator to help enterprises jump-start their data and analytics journey. This accelerator is vetted with multiple use cases across industries, and it reduces the overall risk and time to implementation to help ensure best practices are followed.
A Holistic Approach to Building a Data Lake
The Data Lake Accelerator achieves efficiencies and economies of scale using best practices. From a Data Lake-Ops perspective, the ARTEMIS component expedites setting up the infrastructure, associated network and data security guardrails, code promotion pipelines, and auditing and logging capabilities associated with building modular and scalable data lakes.
From the Data-Ops point of view, the Intelligent Data Foundation (IDF) component helps to jump-start data acquisition and onboarding, data ingestion, data quality, and metadata management, extract, transform, and load (ETL) and enrichment, consolidation and reconciliation, and consumption of data.
The accelerator is designed to solve many of the issues customers run into when initially setting up a data lake. It comes with modular and fully-functional capabilities that can either be used independently or be stitched together to build automated data pipelines that can be deployed in production.
These modules are pre-created code bases that are optimized based on Accenture’s experience and expertise delivering data and analytics initiatives for decades.
Solution Overview
Data Lake-Ops: ARTEMIS
The core component behind the Data Lake-Ops component (ARTEMIS) is a fully automated workflow engine running on AWS Step Functions. It’s used to automate scaling and orchestration of ingestion, ETL, and reporting of data.
Each workflow uses pre-built PySpark code running in AWS Glue to perform the transformation process, from raw to curated data. Amazon DynamoDB manages state information for workflows.
Data ingestion is managed through real-time configuration that writes code dynamically to ingest both structured and unstructured data, in batch and real-time streaming modes, from both public and internal data sources.
Pre-defined security policies and standards are designed for Amazon Simple Storage Service (Amazon S3) buckets to support both hypersensitive and public data. All runtime roles are developed with least privilege access control in mind. The asset comes with built-in security, governance, key management, and multiple layers of data security.
Amazon CloudTrail and Amazon CloudWatch can be pre-configured for monitoring and alerting. Data from the “Processed” data lake can be consumed by a variety of analytics and machine learning (ML) services and ultimately exported to front-end systems.
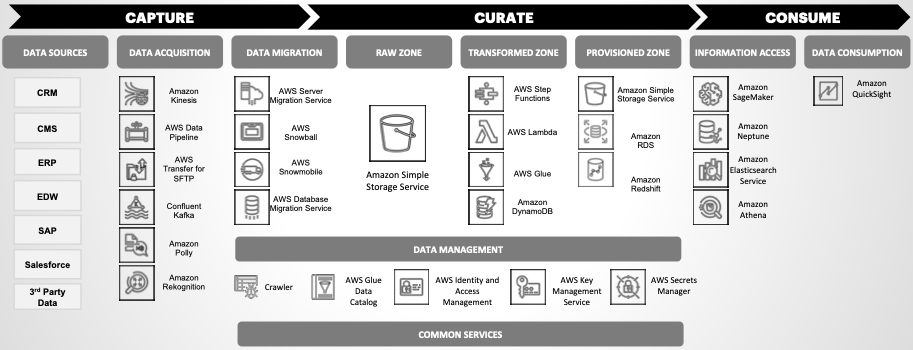
Figure 1 – Data Lake-Ops (ARTEMIS) solution architecture. Click to enlarge.
Data-Ops: Intelligent Data Foundation (IDF)
The Data-Ops component (IDF) can be used to design, implement, and deploy production-ready data and analytics pipelines through a user interface (UI) that generates AWS-native data pipelines.
Typically, IDF implementation can be done with a minimum of three AWS services: Amazon S3, AWS Glue, and AWS Lambda, which can help to build and run the data pipelines.
However, in an enterprise scenario where we’re looking to ensure security (access control based on data attributes, roles, policies and tags), continuous integration and continuous delivery (CI/CD), and DevOps, along with central metadata catalog and credential management, IDF can be deployed with the rest of the services.
The following diagram illustrates the features and modules that can be enabled through IDF. For example, as part of the data capture capability, IDF provides out-of-the-box abilities for data identification, onboarding workflow, configurable data loader, and data validation. Similarly, it has built-in capabilities for data curation and data publishing.
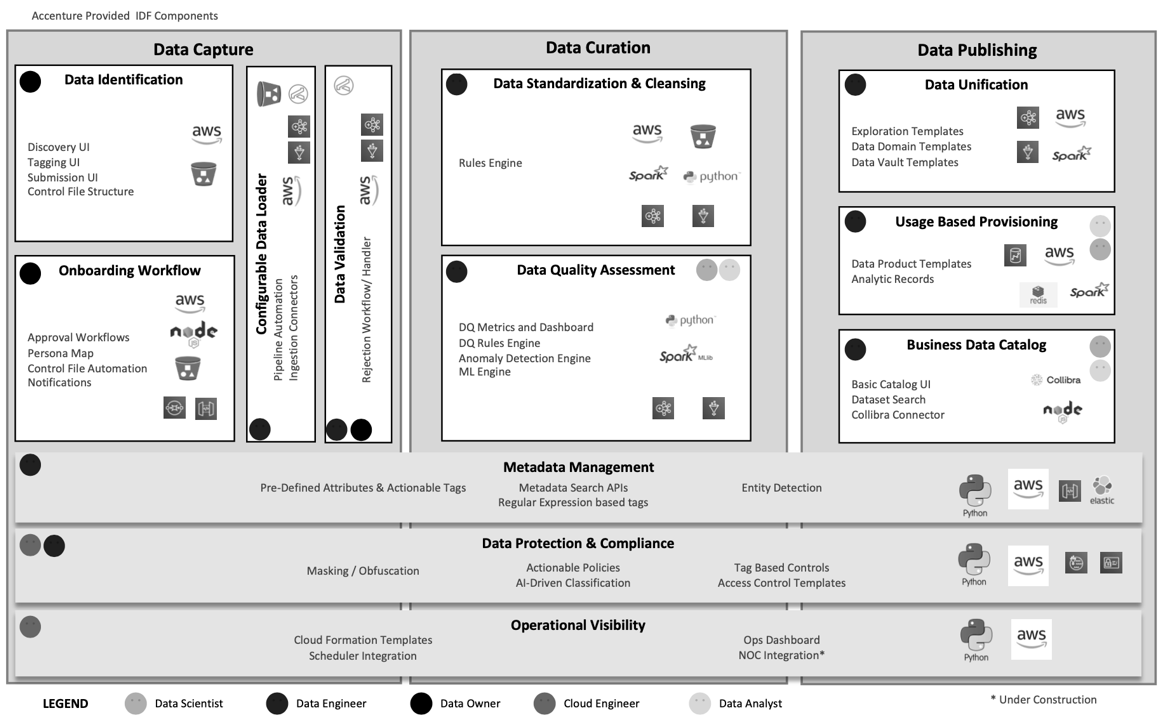
Figure 2 – Data-Ops (IDF) solution architecture. Click to enlarge.
Deployment
The accelerator can be deployed rapidly through a modularized, plug-and-play deployment process. Accenture uses a custom CI/CD framework to accelerate deployment of both backend and front-end core components of the system, and then deploy any à la carte modules systematically.
Environment migration for the accelerator is highly repeatable as a result of the infrastructure as code (IaC) baseline that it’s established on and the configuration migration utilities it comes with.
The accelerator automates zone creation for the data lake. Four zones (Landing, Raw, Curated, and Published) are provisioned. Scripts that create the S3 buckets and associated folder structures automatically in minutes are run as part of the initial setup.
The deployment process is highly automated with the help of AWS CloudFormation templates, AWS Lambda functions, AWS CodePipeline, and AWS CodeBuild. A Data-Ops cartridge for the data lake through AWS CodeCommit and CodeBuild helps ensure CI/CD across environments.
Integration with External Systems
The accelerator runs natively on AWS and supports several ingestion methods. Currently supported data lake ingestion capabilities include SFTP, REST, JDBC, Flat File, Amazon S3, and streaming data.
Ingestion and curation from both on-premises and cloud-based SAP implementations are available through the SAP Data Lake Accelerator, which is a child offering of the Data Lake Accelerator.
Apart from being cloud-native and built on AWS, the accelerator supports integrations with third-party tools such as Confluent, Paxata, Control-M, and Protegrity, as well as products like Collibra, Alation, Databricks, and Snowflake. These integrations can be enabled on demand.
Key Benefits of Using the Data Lake Accelerator
Accenture’s cloud-native Data Lake Accelerator provides a cost effective, scalable solution which streamlines, automates, and expedites the build and delivery of enterprise-scale data lakes on AWS. It improves speed to market and comes with built-in security and access controls.
The accelerator is built on a governance-first principle that does not treat governance as an afterthought, but more like a tangible component that ties people and processes together through the technology it provides. The center of the governance process is the UI and workflow management that provides clear definition of what to onboard and how.
The accelerator was built with the objective of making the process of setting up data lakes and designing, building, and deploying data pipelines automated, repeatable, and reusable. It helps address slow decision making in enterprises stemming from siloed and untapped data, and being tied to traditional data management processes.
The accelerator saves time and effort while ensuring a high degree of standardization of the data engineering process.
Conclusion
The Accenture Data Lake Accelerator powered by AWS provides a one-stop solution for automated data platform creation, managed data transformation, and data and analytics performed in a cloud-native way.
The accelerator is implemented at multiple customers at production scale, and can empower your organization’s data strategy and seamlessly enable extracting actionable insights from data.
The Data Lake-Ops and Data-Ops components, ARTEMIS and Intelligent Data Foundation (IDF) can be implemented as stand-alone solutions or as an integrated workflow to fit the unique requirements of your business.
Accenture and AWS have worked together for more than a decade to help organizations realize value from their applications and data. The collaboration between the two companies, the Accenture AWS Business Group (AABG), enables enterprises to accelerate their pace of digital innovation and realize incremental business value from cloud adoption and transformation.
Connect with the AABG team at accentureaws@amazon.com to drive business outcomes by transforming to an intelligent data enterprise on AWS.
.

.
Accenture – AWS Partner Spotlight
Accenture is an AWS Premier Consulting Partner and MSP. A global professional services company that provides an end-to-end solution to migrate to and manage operations on AWS, Accenture’s staff of 569,000+ people includes more than 20,000 AWS-trained technologists with more than 12,000 AWS Certifications.
Contact Accenture | Partner Overview
*Already worked with Accenture? Rate the Partner
*To review an AWS Partner, you must be a customer that has worked with them directly on a project.