AWS Partner Network (APN) Blog
Building Scalable IT Platforms with the AWS CDK Using Attini
By Angelo Malatacca, Partner Solutions Architect – AWS
By Carl Ostrand, CEO and Founder – Attini Cloud Solutions
 |
| Attini |
 |
The AWS Cloud Development Kit (AWS CDK) is a software development framework that allows developers to define their infrastructure as code (IaC) using familiar programming languages such as TypeScript, Python, Java, and others.
With the AWS CDK, developers can easily provision and manage Amazon Web Services (AWS) resources, define complex architectures, and automate infrastructure deployments, all while leveraging the full power of modern software development practices like version control, code reuse, and automated testing.
AWS CDK simplifies the process of building, deploying, and managing infrastructure in AWS, making it a popular choice for organizations that want to improve their agility, reliability, and scalability. AWS CDK is a massive step forward in the DevOps field, as using a proper programming language for IaC helps deliver features faster, creates fewer bugs, and makes it easier to maintain IT environments.
In this post, we will create a flexible, serverless, and fast pipeline that can integrate with anything in the cloud environment.
Attini is an AWS Partner and serverless deployment framework for cloud platforms. Attini helps you package your code, configuration, and deployment instructions into immutable artifacts. The Attini Framework will then automatically run your deployments for you.
What Are the Challenges?
To maintain deployments in multiple environments, developers need to interact with the infrastructure deployed. Some everyday scenarios that are often faced include:
- Running database configurations, like Liquibase or SQL queries.
- Running integration/load test after a deployment.
- Running configuration tools like Ansible or SSM Documents.
- Taking backups before deployments.
- Handling dependencies between AWS CDK apps (sometimes cross-account and region).
- Applying Kubernetes configuration.
Essentially, developers need a way to integrate AWS CDK deployments with third-party technologies. This can be solved by putting your AWS CDK deployment in a pipeline that can execute other tasks.
In this example, we’ll keep it simple and use AWS CodeBuild to run a SQL query on a database we created previously. In reality, these pipelines can become very complex and need a lot of maintenance.

Figure 1 – Simple deployment to a single environment.
Now, we also need to manage multiple environments. Let’s scale our pipeline and add a development, acceptance, and production environment.
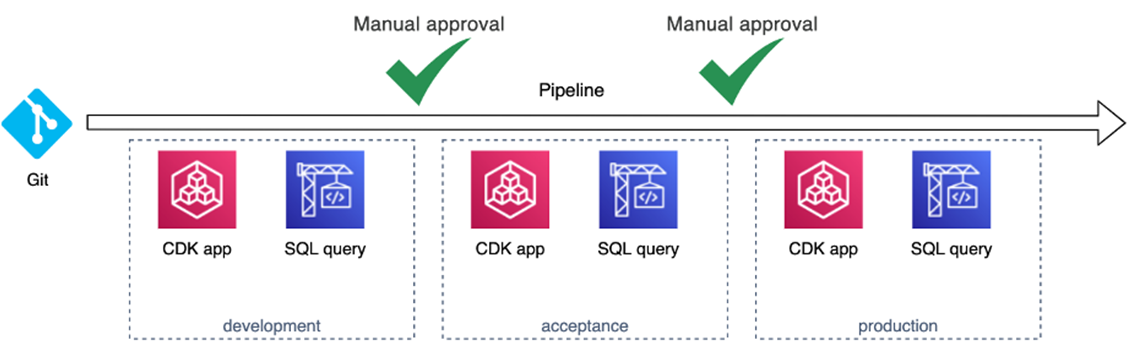
Figure 2 – Deploy to multiple environments.
It’s common for organizations to want even more lower-tier environments to increase development velocity. For example, every development team may want its own development environment, and a bigger project might need its own environment. AWS and the AWS CDK are great at this because they can decrease the cost and maintenance of these environments.
However, it becomes problematic to keep adding environments to the central pipeline, as any issues in a single environment can block the whole pipeline. As the pipeline grows, it also becomes slower and more difficult to change, so we’ll need to manage these environments separately. We can create separate pipelines for them or handle them manually. Either way, it’s a lot of work and there is no one-size-fits-all method here.

Figure 3 – Deploy to multiple environments, both manually and automatically.
All new changes need to be propagated to all environments, and because we have no unified method for this there’s a big risk of environmental drift.
It’s common practice to use Git as the source for IaC deployments. Because Git is a version control system and we source our deployments from Git, it’s easy to assume we know what version is running where. In reality, though, we have no idea.
Unless we build some custom logging/tagging system, we don’t know what has been deployed in what environment. This makes it important to frequently deploy to all environments, including production, just to ensure the environments don’t diverge too much.
The rollback process is also messy. It requires us to roll back our code in Git. If we don’t have a manual process for deploying, we also need to rerun the whole pipeline.
Your organization probably has more than one Git repository. For example, let’s say that you have three repositories—one AWS CDK App with your network, one for your databases, and one for your app. The databases also need to be configured by running some SQL queries during deployment.
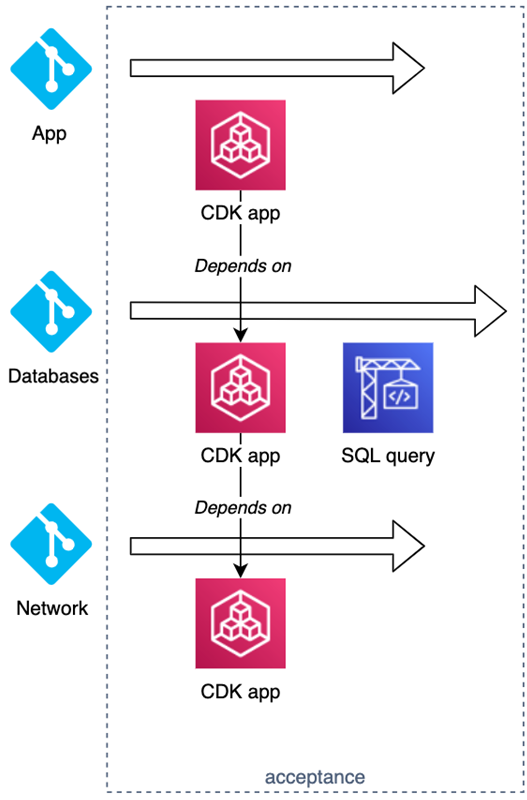
Figure 4 – Three repositories deployment.
These deployments are somewhat isolated and can be deployed independently most of the time. There are usually some dependencies that have to be satisfied; for example, the database will need a network.
So, every environment is being built with code from multiple repositories, and your pipelines must maintain your whole IT landscape. Now, we can see how the complexity grows exponentially.

Figure 5 – Overall architecture.
It’s easy to see how we lose control and how environmental drifts occur. The above example is still only three repositories with a few environments.
Where Did the Complexity Come From?
Where did we go wrong? First of all, we used Git as our deployment source. When building applications, we normally create an artifact from our code, like a Docker image, library, or file archive. We also give it a version and store it in an artifact repository. But we don’t package our IaC for some reason—we just push it to Git and roll it out.
Secondly, we mixed two very different architectural scopes. We have our environment scope where the deployment occurs, and then we have our central/global scope that orchestrates our different environments. Having one pipeline that deploys to several environments is good because it helps to keep environments in sync, but it also creates a tight coupling and a single point of failure.
On the other hand, if environments are deployed separately, they become harder to manage and we run the risk of environmental drift. Manual deployments also become more difficult as the deployment complexity increases.
Essentially, we get to choose between tight coupling and poor maintenance.
How Can We Make it Better?
So, how should we make it better? First, we should stop sourcing our deployments directly from Git. Instead, we should create a package containing everything we want to deploy.
When working with IaC, what we deploy and how we deploy it is very tightly coupled. We want to make sure our pipelines are in sync with our application. An easy way to achieve this is to include the pipeline definition in the package.

Figure 6 – Package containing the code and the pipeline.
We can give the package a name, version, and any other metadata we might need. We also have dependencies, so we’ll need to be able to declare and manage those.
Now, we have a package that has all of the information and logic it needs to be deployed, but we still need to unpackage and deploy it. This could be done from a central platform, but it would be better if we could do this from within the environment we are deploying to. That way, our environments can be completely independent and we avoid bottlenecks and single points of failure.
We need to keep one thing in mind—the package has to be “environment agnostic,” meaning it should always be reusable for all your environments. That way, your package can be used in as many environments as you need, just like a Docker image or a software lib.
However, the deployment is executed from within the environment so, at deployment time, we can use AWS CDK lookup functions, get configuration from AWS Systems Manager Parameter Store, or run AWS Lambda functions to get environment-specific configurations for us.
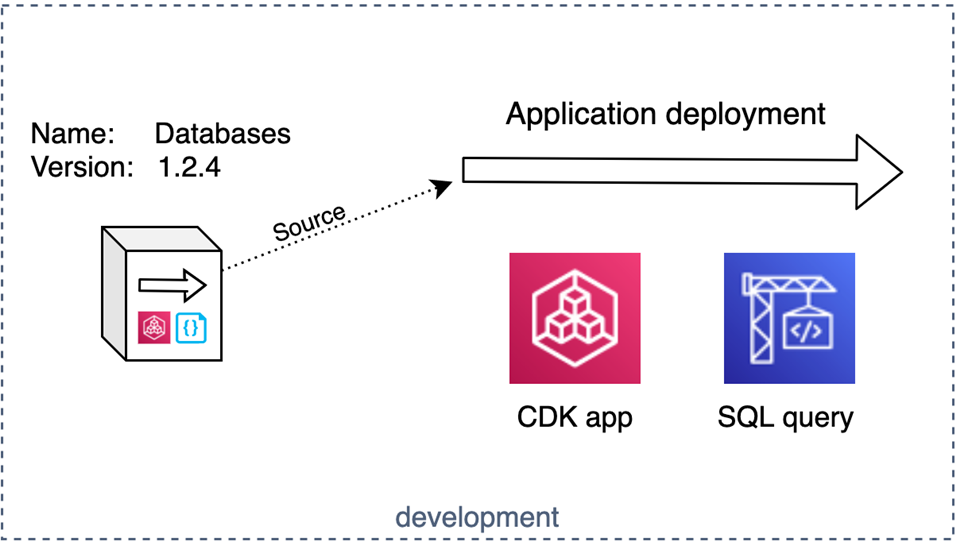
Figure 7 – Deploying a package.
Finally, we want to know what we have deployed in our different environments. Because we gave the package a name and a version, this is easy to keep track of. Every environment can maintain its own inventory so we can always see what’s deployed where. We can also keep copies of earlier versions in the environment to make rollbacks simpler.
The central pipeline is still useful to orchestrate and visualize our IT landscape from one location, but we heavily decreased our dependency on it. Now, we can easily perform manual deployments in a standardized way while keeping track of what code is running where. We just need to check the environments inventory to see what’s deployed with what version.
Attini helps you to create this package, and it manages the automation required to perform a hands-off deployment. It also keeps track of inventory and backups of older versions in case you need to perform a rollback.
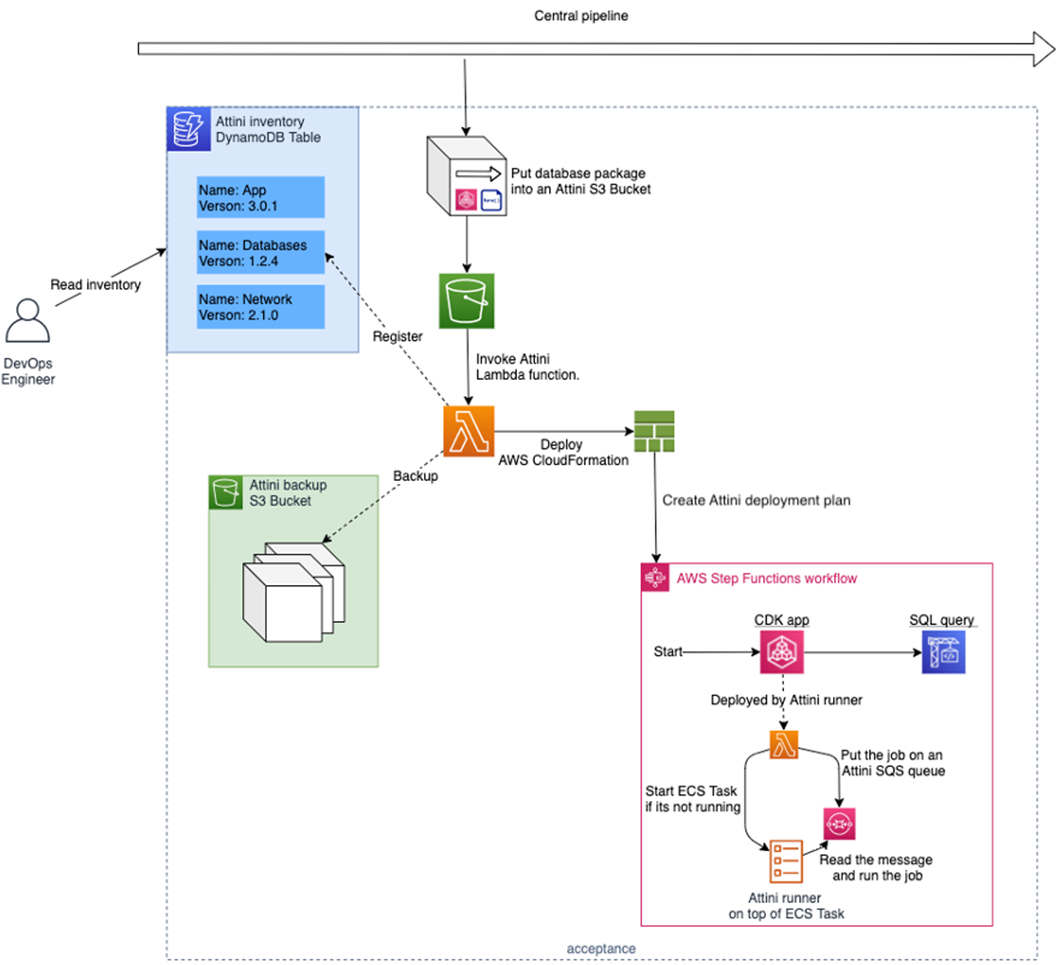
Figure 8 – Attini hands-off deployment.
Attini deployment plans (the pipeline) are written in AWS CloudFormation or using AWS CDK constructs. Deployments are triggered when you upload an Attini distribution (the package) to Amazon Simple Storage Service (Amazon S3).
Behind the scenes, a Lambda function will be invoked, creating a CloudFormation stack using the deployment plan template. When the deployment plan is ready, Attini will run the deployment automatically.
The deployment is then executed from within your AWS account using only serverless resources. This means the deployment plan and its associated resources will automatically be maintained and highly available.
The Attini deployment plan is built using AWS Step Functions, and all of its features are available. In addition, Attini has its own state types for everyday tasks, such as deploying AWS Serverless Application Model (AWS SAM) or CDK applications, running build containers, and asking for manual approval.
Solution Benefits
- Attini is free to use, open source, and only uses serverless resources that should easily fit within the free tier.
- Attini is built for being fast. It uses containers that will stay warm between executions, reducing time spent on cold starts. It also event-driven, further increasing deployment speed.
- AWS Step Functions orchestrates the deployments, and the build server (Attini runner) uses Amazon Elastic Container Service (Amazon ECS) and stays warm between executions, like a Lambda function.
- The deployment is executed from within your AWS account, so the deployment can be run from within private networks using least privilege AWS Identity and Access Management (IAM) roles, while the Attini’s command line interface (CLI) can follow the deployment from any terminal or central pipeline.
- Attini keeps track of your deployments, maintains dependencies and deployment history, saves backups, and performs rollbacks. You can easily see what projects/apps and versions are running in your IT environments.
- Everything is authenticated using IAM, so if you have the AWS CLI installed, you’re already logged in. This also means Attini’s actions are logged by AWS CloudTrail.
Conclusion
As an organization’s IT landscape grows and teams adopt new technologies, you’ll likely face new challenges. You have to find a way of working that keeps your development velocity up and your maintenance workload down. This is essential if you want to be successful on your cloud journey.
Find a full example of how to deploy an AWS CDK application using Attini , or visit the Attini website for more information.
.

.
Attini – AWS Partner Spotlight
Attini is an AWS Partner and serverless deployment framework for cloud platforms. Attini helps you package your code, configuration, and deployment instructions into immutable artifacts. The Attini Framework will then automatically run your deployments for you.