AWS Partner Network (APN) Blog
Creating the Right Patient Outcomes with Amazon HealthLake and Accenture Health Analytics
By Sercan Bilgic, Technical Architecture Manager – Accenture
By Jens Hoefkens, PhD, Healthcare and Life Sciences Lead – Accenture
By Cecil Lynch, MD, MS, Chief Medical Information Officer – Accenture
By Faris Haddad and Jan-Paul Groeneboom – AWS
 |
| Accenture |
 |
Challenged with the growing need for comprehensive chronic and acute disease management with a standardized, integrated view of a patient across care settings, healthcare organizations are seeking guidance and solutions to improve patient outcomes and reduce delivery costs.
The ability to accurately share and analyze patient information between different healthcare providers and systems is critical to the transition to patient-centric care.
Examples of relevant data include patient diagnosis, test results, medication history, and treatment plans. While the industry has created a number of standards to support seamless interoperability, they have often fallen short on scope and ease of use.
In this post, we present a scalable precision medicine and population health solution architected and built using Amazon HealthLake. We will highlight how leveraging the Fast Healthcare Interoperability Resources (FHIR) industry standard for electronic healthcare information exchange and the use of Amazon HealthLake removes the heavy lift of organizing, indexing, and structuring patient information in a secure, compliant, and auditable manner.
We will also showcase how Amazon Web Services (AWS) and Accenture, an AWS Premier Tier Services Partner, collaborated to build a population-scale research cohort analytics solution called Accenture Health Analytics (AHA) which contains 54 million longitudinal patient records using a range of AWS services.
Accenture Health Analytics was steered and supported by the Accenture AWS Business Group (AABG), which represents the global collaboration of the two organizations and combines the resources, technical expertise, and industry knowledge of Accenture and AWS, all through a single team.
The team was asked to move an existing application running on another platform with all components to AWS. The application was migrated and redesigned using an improved architecture that leverages AWS-native capabilities and a serverless architecture.
FHIR Mapping
While FHIR’s flexibility and adaptability is its strength, it can cause complexity as the logical interpretation at either end of an integration can vary widely.
To tackle the complexity of handling myriad diagnosis, procedure, and differing code systems, the AABG team created a unified infrastructure for having all code standardized and accessible from a single FHIR server. This makes building and supporting analytical queries much easier. The diagram below illustrates the data entities and their relationships.

Figure 1 – FHIR terminology resources overview.
FHIR Conversion
An important part of the AHA value proposition is the customer’s ability to integrate and compare proprietary data with over 54 million rows of longitudinal health records. Since the original patient data were not in FHIR format, we leveraged the HiPaaS FHIR data converter for Amazon HealthLake.
Key components of the HiPaaS API service are the master loader (to load the incoming data and manage end-to-end orchestration), GetHiPaaSID API (to retrieve the loaded files and execute maps), and master object insert (which executes the business logic to compare, validate, and convert to FHIR), as illustrated in the diagram below.

Figure 2 – FHIR converter overview.
Data Ingestion to Amazon HealthLake
We decided to use Amazon HealthLake to securely import, store, transact, transform, and analyze the 54 million longitudinal patient records. Using HealthLake APIs, we could easily ingest tens of terabytes of data within a few days.
In addition to storing all data in the standard FHIR format, HealthLake uses Amazon Comprehend Medical integration to automatically understand and extract meaningful medical information from the raw data, such as medications, procedures, and diagnoses. See the diagram below for an overview of HealthLake and related AWS services.

Figure 3 – Amazon HealthLake overview.
Upon ingestion, Amazon HealthLake uses machine learning (ML) models that are trained to understand medical terminology to show and tag each piece of clinical information, index events into a timeline view, and enrich the data with standardized labels (medications, conditions, diagnoses, procedures). This eases quick and easy information search and retrieval.
For example, if a healthcare provider wants to know “What is the immunization status for my patients?” this can be easily queried from the time-lined data by searching for “immunization” with search parameters as “patients” for a detailed view of immunization status for different diseases for different patients.
Relational Data Access
In addition to the ML-based indexation of data described above, Amazon HealthLake also provides a relational view of the FHIR data using Amazon Athena and Apache Iceberg tables. This provides users with full SQL read access to the underlying data, which are stored in parquet files in Amazon Simple Storage Service (Amazon S3).
Being able to access the health data using Iceberg tables provides a convenient access mechanism for existing analytics and visualization tools.
Cohort Browser and Data Visualization
The native API access and SQL query capabilities of Amazon HealthLake are generally not suitable for access to the patient data by physicians and healthcare providers. Instead, graphical query builders and dashboarding capabilities are required.
To that end, this solution includes a graphics cohort browser with the following capabilities:
- Provides immediate access to 54 million clinical patient records (both inpatient and ambulatory visits, longitudinal data up to 12 years).
- Allows users to segment patients for advanced population health analytics and can ingest a client’s own dataset.
- Includes full pharmaceutical drug discovery capabilities and hyper-targeted clinical trial population selection to accelerate and the drug development lifecycle.
- Enables a population genomic overlay linking diseases to their genes, variants, pathways, and proteins to develop and deliver precision therapies.
The following screenshots show the process of cohort creation using a graphical user interface (UI) with drag-and-drop and live result preview.
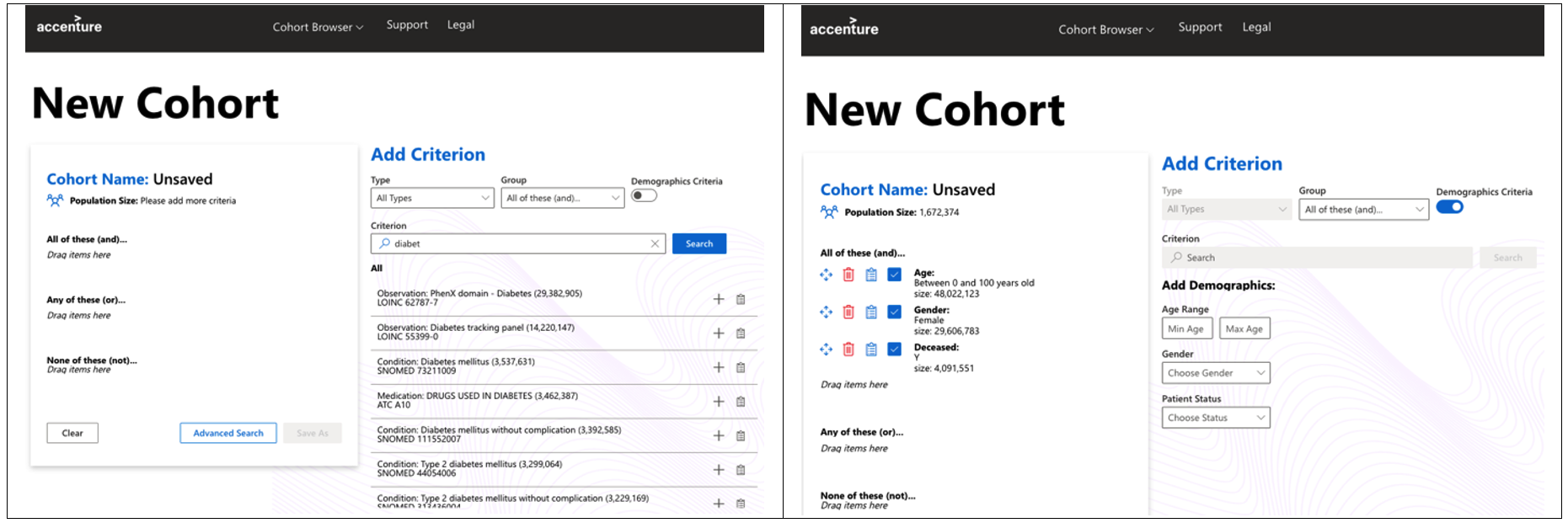
Figure 4 – Cohort creation from UI.
To improve the performance of the cohort browser, the team implemented a query cache using Amazon Redshift. When a search is initiated, the system performs a check to determine if the query has already recently occurred.
If two search requests are made in close succession for the exact same search parameters, the results from the first search will be reused and returned for the second instead of executing the same search again. This results in time savings as the query cache is extremely fast compared to executing searches against the HealthLake database.
In addition to improving query times by a factor of 1,000 or more, the query cache also helps minimize traffic spikes in the database with large numbers of backend calls, which could lead to application timeouts and high consumption charges.
After cohort creation, users are guided to further analyze the selected patient cohort with predefined interactive dashboards. For this, we used a combination of Amazon HealthLake, Amazon Redshift, and Amazon QuickSight to enable near real-time analytics and dashboarding.

Figure 5 – Opening embedded QuickSight.
When opening the Amazon QuickSight dashboard from the created cohort, embedded QuickSight data is filtered via a passed id parameter in the URL, as seen below.
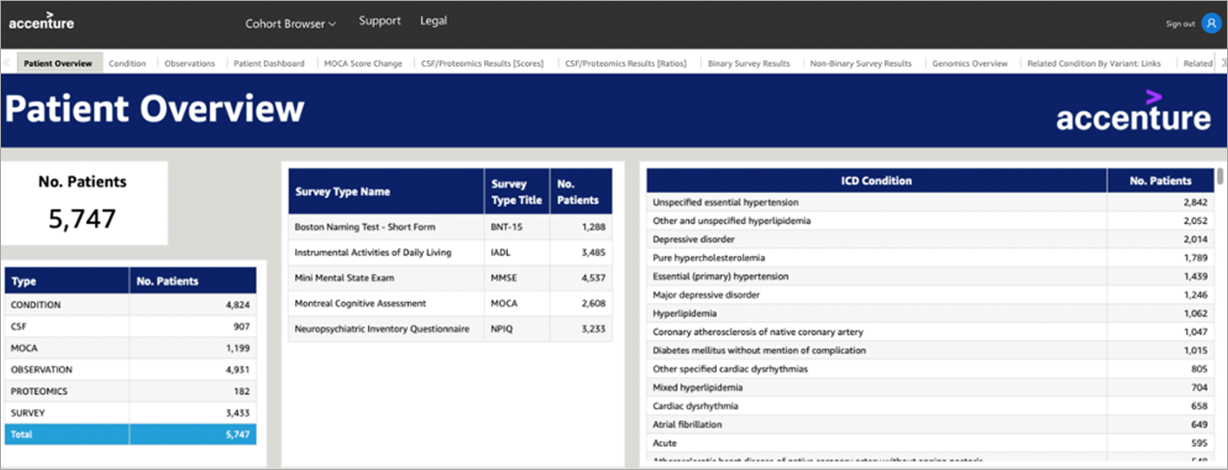
Figure 6 – Launching embedded QuickSight.
The team built the embedded QuickSight dashboards so the user experience mimics the experience of using QuickSight as a standalone web application for published dashboards, with the publisher of the dashboard determining the design and the level of access and interactivity.
Examples of this level of customization are the ability to download data to comma-separated value (CSV) files and to use the advanced filtering panel. Examples of the predefined QuickSight dashboards are provided in the screenshots below. Notably, the embedded dashboards can be customized by clients to help answer the use-case specific questions of interest.

Figure 7 – Other dashboard screens.
Reference Architecture
The solution leverages Amazon HealthLake for its FHIR server capability and easy integration with all HIPAA-eligible AWS analytics and machine learning services such as Amazon Athena, Amazon Redshift, Amazon SageMaker, Amazon QuickSight, and third-party analytic tools and services.
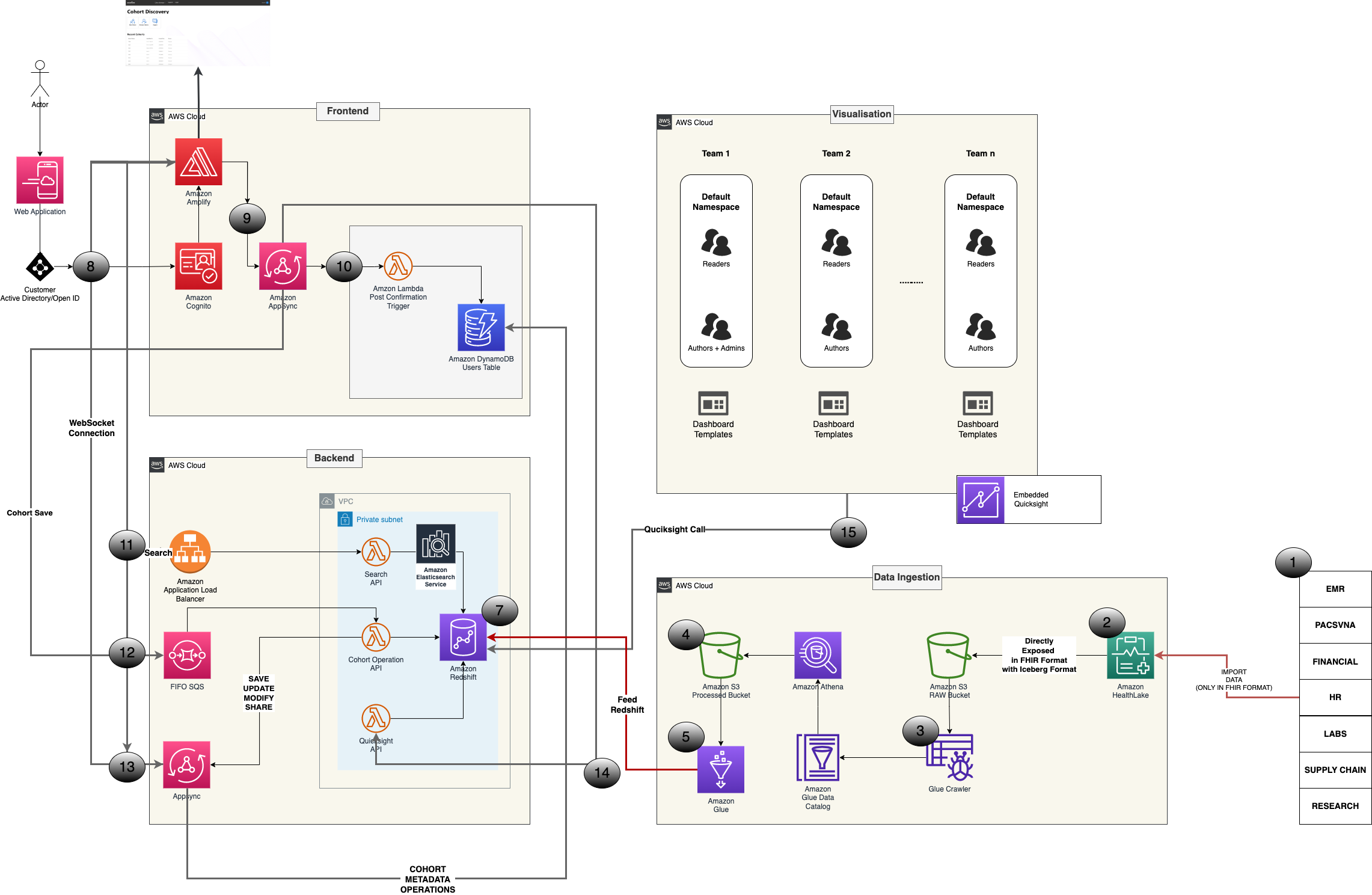
Figure 8 – AWS reference architecture.
Core Solution Components
- FHIR logical layer: 1-2-3-4-5
- Designed around Amazon HealthLake, Amazon Athena, and Apache Iceberg
- Terminology backend: 7-11-12-13
- Cache layer: 7
- Leverages Amazon Redshift Serverless with Amazon OpenSearch Service
- Frontend: 8-9-10
-
- ReactJS apps deployed via AWS Amplify
-
- Visualization layer: 14-15
- Amazon QuickSight
This solution was awarded and recognized by AWS during the 2022 Q4 “Disruptive Architectures” competition for its innovative use of Amazon HealthLake and serverless services.
Conclusion
In this post, we presented how AWS and the Accenture AWS Business Group (AABG) have implemented the Accenture Health Analytics (AHA) healthcare analytics solution on AWS, leveraging Amazon HealthLake to store and access 54 million longitudinal patient records. The solution provides highly performant access to interoperable clinical data for dynamic exploration, analysis, reporting, and actionable outcomes improvement.
In addition to enabling precision medicine and population health analytics at scale, AHA helps healthcare payers prepare for the interoperability requirements of the 21st Century Cures Act, while providers can run SMART on FHIR apps in their workflows.
Moving through the rapid cycle of event-to-data-to-insight enables stakeholders to ask new questions, discover insights, act on new understandings, measure performance, and share ideas through the network—all of which improves patient health and outcomes.
The re-architecture of this solution using AWS-native capabilities provided the following benefits:
- Reduced complexity of running and deploying the platform.
- Provided a unified scalable health data store in FHIR format.
- Eliminated the need to create bespoke data marts for each customer, which used to require three people for four weeks.
- Managed HIPPA-eligible storage, analytics, and sharing service.
- Optimized SQL query through Amazon Redshift and Amazon Athena for all data.
- Reduced total cost of ownership (TCO) of maintaining complex extract, transform, load (ETL) pipelines and transformations.
- Gained a 7% increase in ML model effectiveness based on the ability to leverage the contextual data captured in FHIR.
Finally, moving to a managed service and serverless architecture using Amazon HealthLake helped us reduce the deployment time from 12 weeks to one week, and allowed us to reduce the run costs by a factor of five.
This joint effort builds on the 15-year strategic relationship between AWS and Accenture and uses the same proven mechanisms and accelerators built by the AABG.
.

.
Accenture – AWS Partner Spotlight
Accenture is an AWS Premier Tier Services Partner and MSP that provides an end-to-end solution to migrate to and manage operations on AWS. By working with the Accenture AWS Business Group (AABG), a strategic collaboration by Accenture and AWS, organizations can accelerate the pace of innovation to deliver disruptive products and services.