AWS for SAP
Extend your SAP business processes using Amazon AppFlow and AWS native services
Introduction
Our customers increasingly want to combine their SAP and non-SAP data in a single data lake and analytics solution to bridge siloed data and drive deeper business insights. Last year, we launched the Amazon AppFlow SAP OData Connector to make it easier for customers to get value out of SAP data with AWS services. We outlined how to get started with AppFlow and SAP and some of the benefits in previous blog.
Following this launch, customers told use that have told us they also want to use the AWS data platform to enhance their SAP business process by enriching data using higher level services such as Artificial Intelligence or Machine Learning. and then feeding the data back to their SAP applications. In January, we delivered against that request by enabling bi-directional data flows between SAP applications and AWS data lake, analytics services and AI/ML services in just a few clicks.
Today, I will show you how to set up a bi-directional data flow in just a few minutes.
The Write Back Feature
The write back feature supports Amazon S3 as a source and writes the data to an SAP system at the OData layer. You can also create deep entities with the SAP OData deep insert feature. Customers also have the option to further protect the data flowing between AWS and SAP systems, with optional AWS PrivateLink security.
The new functionality can enable variety of use cases for our customers and integration from data sources such as Redshift, Lambda, or enriched business data from Amazon AI/ML services such as Sagemaker, Rekognition, Textract or Lookout for Vision.

In the next section we will show you how to easily get up and running with an example of what you can achieve with Amazon AppFlow, SAP and AWS native services.
The Amazon AppFlow SAP OData Connector
First, I will recap some of the basics for the SAP OData Connector before going into a detailed guide on setting up the write back feature and an example end to end use case with AppFlow, SAP and native services.
Amazon AppFlow offers a significant cost saving advantage compared to building connectors in-house or using enterprise integration platforms. There are no upfront charges or fees to use AppFlow, and customers only pay for the number of flows they run and the volume of data processed. The SAP OData Connector provides direct integration of SAP with AWS services without the need to pay for any additional adapters or licenses. This is all configured in the same simple AppFlow interface.
The Amazon AppFlow SAP OData Connector supports AWS PrivateLink which adds an extra layer of security and privacy. When the data flows between the SAP application and your source or destination Amazon S3 bucket with AWS PrivateLink, the traffic stays on the AWS network rather than using the public internet (see Private Amazon AppFlow flows for further details).
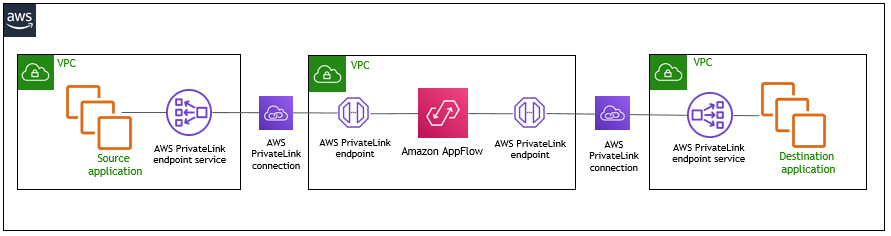
Customers running SAP Systems on-premises can also use the Amazon AppFlow SAP OData Connector by using AWS PrivateLink in conjunction with an AWS VPN or AWS Direct Connect based connection as an alternative of using the public IP address for the SAP OData endpoint.
Configuring your flow
In our previous blog we showed you how to set up a connection and configure an extract flow, the setup steps for configuring a write back connection are the same and you can also refer to our Amazon AppFlow SAP OData Connector documentation.
Once you have your connection in place, the configuration steps to create the update flow in SAP through Amazon AppFlow SAP OData are as follows:
1) Configure Flow. In this configuration screen you can set select source Amazon S3 bucket, target SAP Connection with Service Entity Sets as well as file formats for reading data from Amazon S3 (JSON or CSV)
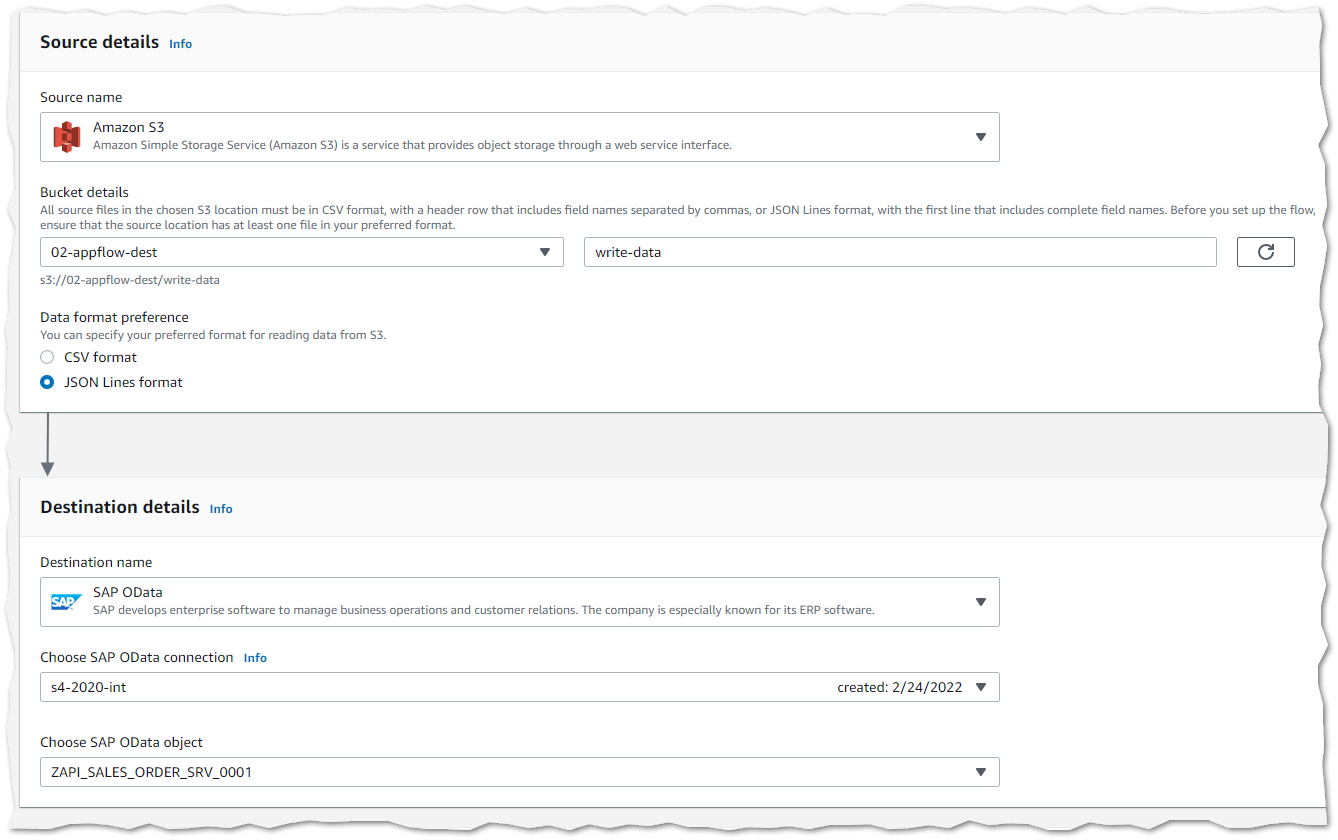
You can also select a destination for the response handling which will write response data into a destination S3 bucket. In the error handling section you can define how the flow will behave if the AppFlow is unable to write a record to the destination, you can select to a) Stop the current flow run or b) Ignore and continue the flow run.
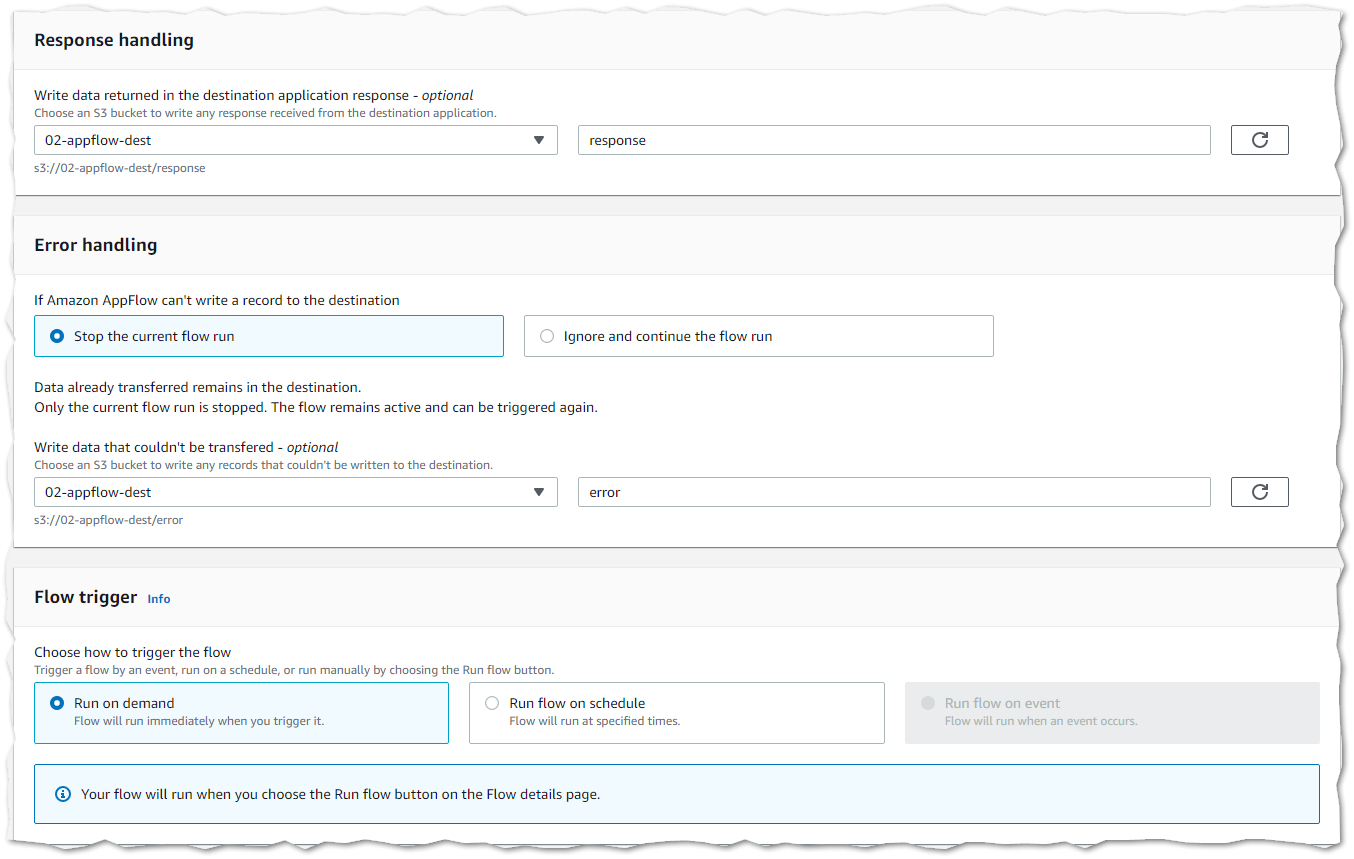
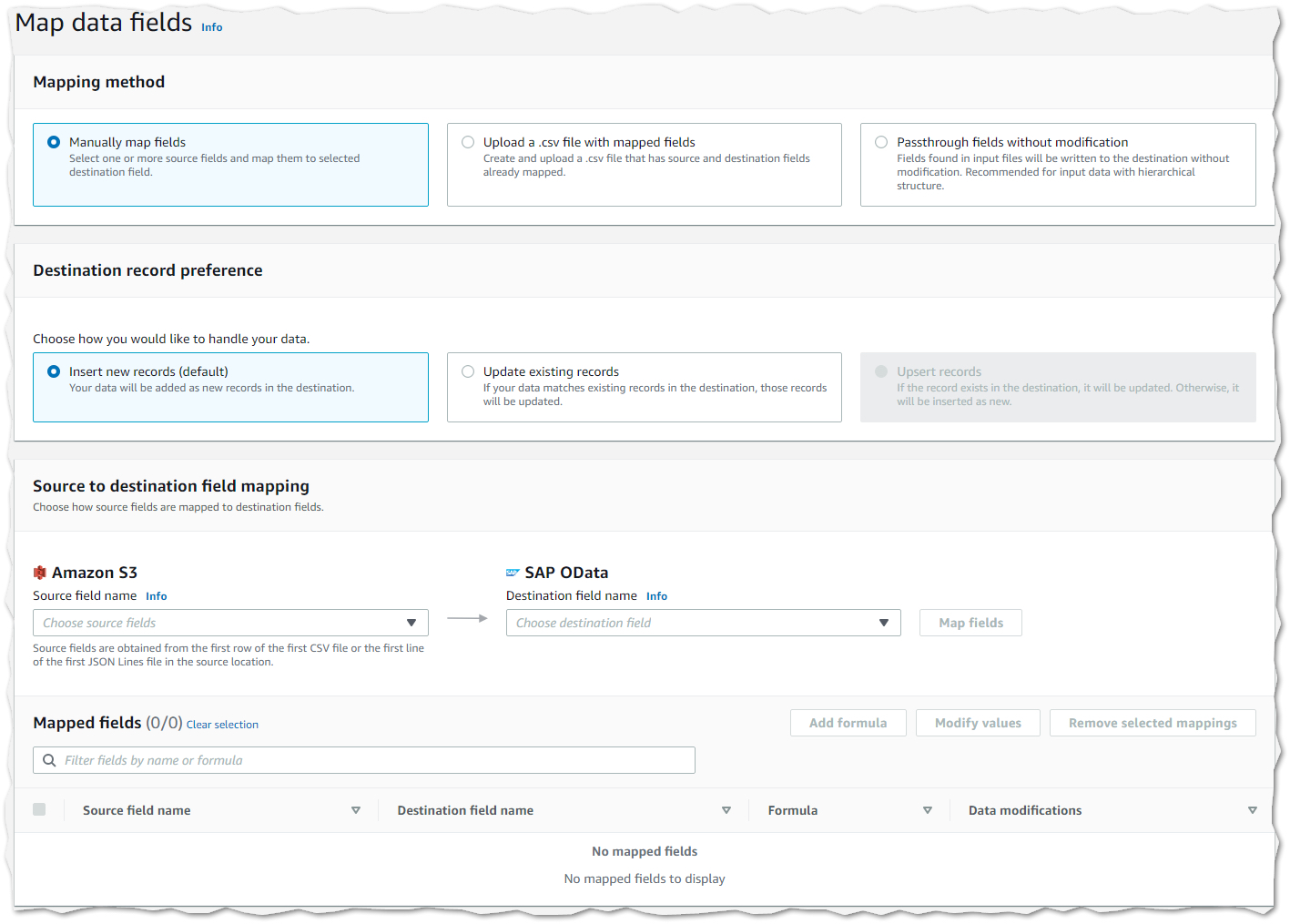
2) Data mapping. In the map data fields step you can select the method for mapping the source to destination fields – manually, using a CSV file or passthrough without modification (recommended for hierarchical structure of input data).
In the destination record preference section you can either select to a) Insert new data records or b) Update existing records. Note: The Upsert operation is not supported for SAP OData connector.
3) Create Flow. In this step you will confirm the flow parameters and create the flow
4) Run the Flow. In this step you will trigger the flow execution
Putting it all together
Now we are able to set up flows to both an extract from and write back to SAP and S3 using the Amazon AppFlow SAP OData Connector we are able to extend customer SAP business processes with AWS native services.This example architecture combines AI/ML services and SAP to provide an automated invoice processing process.

1) Scanned invoices are sent from Vendors and stored to Amazon S3
2) Sales Order data is extracted from SAP S/4 HANA using the AppFlow SAP OData connector
3) Amazon Textract is used to process incoming scanned invoices and extract the text contained in these using machine learning.
4) AWS Step Functions is used to carry out the workflow functionality
5) The first step is to process and store the extracted invoice data to S3.
6) The following step in the AWS Step Function workflow compares the invoice data extracted from SAP with the scanned invoice data.
7) If a match is found an Amazon DynamoDB table is updated with details of the Sales Order and Invoice
8) If no match is found an exception is generated and an email notification is sent to the operations team to investigate using Amazon SNS
9) The final step in the workflow is to generate update files in JSON format based on the matched records in DynamoDB
10) Amazon Appflow writes the updates back to the SAP S/4 HANA system using the SAP OData connector
All of this is done using native AWS services, without provisioning any servers or procuring costly enterprise licenses. The Amazon AppFlow SAP OData flows are all configured through a few clicks in the AWS console and are fully secured through transport level encryption and PrivateLink connectivity.
This was one of the simple example of Amazon Textract, where you can use it for various other use cases such as
- Document processing with SAP
- Automate business processes such as ingesting sensitive tax documents
- Automating search and index of historical records using Textract
The architecture pattern and approach of using AWS native services to extend your processes aligns to both SAP and AWS’s strategy to keep the core SAP system clean. Customers who follow this approach will benefit from less customization and associated overheads in the SAP system of record. They will also be to take advantage of the pace of innovation in AWS services and as these support more agility will enable faster time to market.
The possibilities for our customers are really exciting and we have multiple AI/ML use cases that can help to enrich your SAP business data and built similar pattern
- Enrich SAP time series data with Amazon Forecast for predictive forecasting in manufacturing, workforce or finance processes
- Integrating SAP QM with Amazon Lookout for Vision to perform anomaly detection in the manufacturing process
- Using Amazon Rekogition together with SAP Manufacturing for product detection and classification
- Searching and indexing SAP structured and unstructured data with Amazon Kendra
- Amazon Lex and Amazon Pinpoint for chatbots integrations
The Amazon AppFlow SAP OData Connector is important building block for this approach and with the new write back feature you can easily extend SAP business processes with AWS services.
Summary
The Amazon AppFlow SAP OData Connector write back functionality provides extended capabilities for customers who want to extend their SAP processes and make use of AWS native services to gain business value from their data. This release continues AWS’s 13 year track record of delivering SAP innovations for our customer and builds upon the same easy and efficient pattern which was introduced with the extract function of the SAP OData Connector. Customers will now be able to read and write data directly from SAP to S3, from where they can leverage higher level AWS services in Analytics, Machine Learning or Artificial Intelligence.
Today, we have shown you how easy it is to get up and running with this new feature and how an example extension of your SAP process may look like with AWS native services. Customers running SAP workloads on AWS can start using this service within the AWS Management Console. Customers still running SAP systems on-premises can also integrate their data using Amazon AppFlow and benefit from the multiple AWS services.
To get started, visit the Amazon AppFlow page. To learn why AWS is the platform of choice and innovation for more than 5000 active SAP customers, visit the SAP on AWS page.