AWS Big Data Blog
Category: Amazon Redshift

Create cross-account, custom Amazon Managed Grafana dashboards for Amazon Redshift
Amazon Managed Grafana recently announced a new data source plugin for Amazon Redshift, enabling you to query, visualize, and alert on your Amazon Redshift data from Amazon Managed Grafana workspaces. With the new Amazon Redshift data source, you can now create dashboards and alerts in your Amazon Managed Grafana workspaces to analyze your structured and […]

Resize Amazon Redshift from DC2 to RA3 with minimal or no downtime
Amazon Redshift is a popular cloud data warehouse that allows you to process exabytes of data across your data warehouse, operational database, and data lake using standard SQL. Amazon Redshift offers different node types like DC2 (dense compute) and RA3, which you can use for your different workloads and use cases. For more information about […]

How GE Proficy Manufacturing Data Cloud replatformed to improve TCO, data SLA, and performance
This is post is co-authored by Jyothin Madari, Madhusudhan Muppagowni and Ayush Srivastava from GE. GE Proficy Manufacturing Data Cloud (MDC), part of the GE Digital’s Manufacturing Execution Systems (MES) suite of solutions, allows GED’s customers to increase the derived value easily and quickly from the MES by reliably bringing enterprise-wide manufacturing data into the […]

Supercharging Dream11’s Data Highway with Amazon Redshift RA3 clusters
This is a guest post by Dhanraj Gaikwad, Principal Engineer on Dream11 Data Engineering team. Dream11 is the world’s largest fantasy sports platform, with over 120 million users playing fantasy cricket, football, kabaddi, basketball, hockey, volleyball, handball, rugby, futsal, American football, and baseball. Dream11 is the flagship brand of Dream Sports, India’s leading Sports Technology […]

Use Amazon Redshift RA3 with managed storage in your modern data architecture
Amazon Redshift is a fully managed, petabyte-scale data warehouse service in the cloud. You can start with just a few hundred gigabytes of data and scale to a petabyte or more. This enables you to use your data to acquire new insights for your business and customers. Over the years, Amazon Redshift has evolved a […]
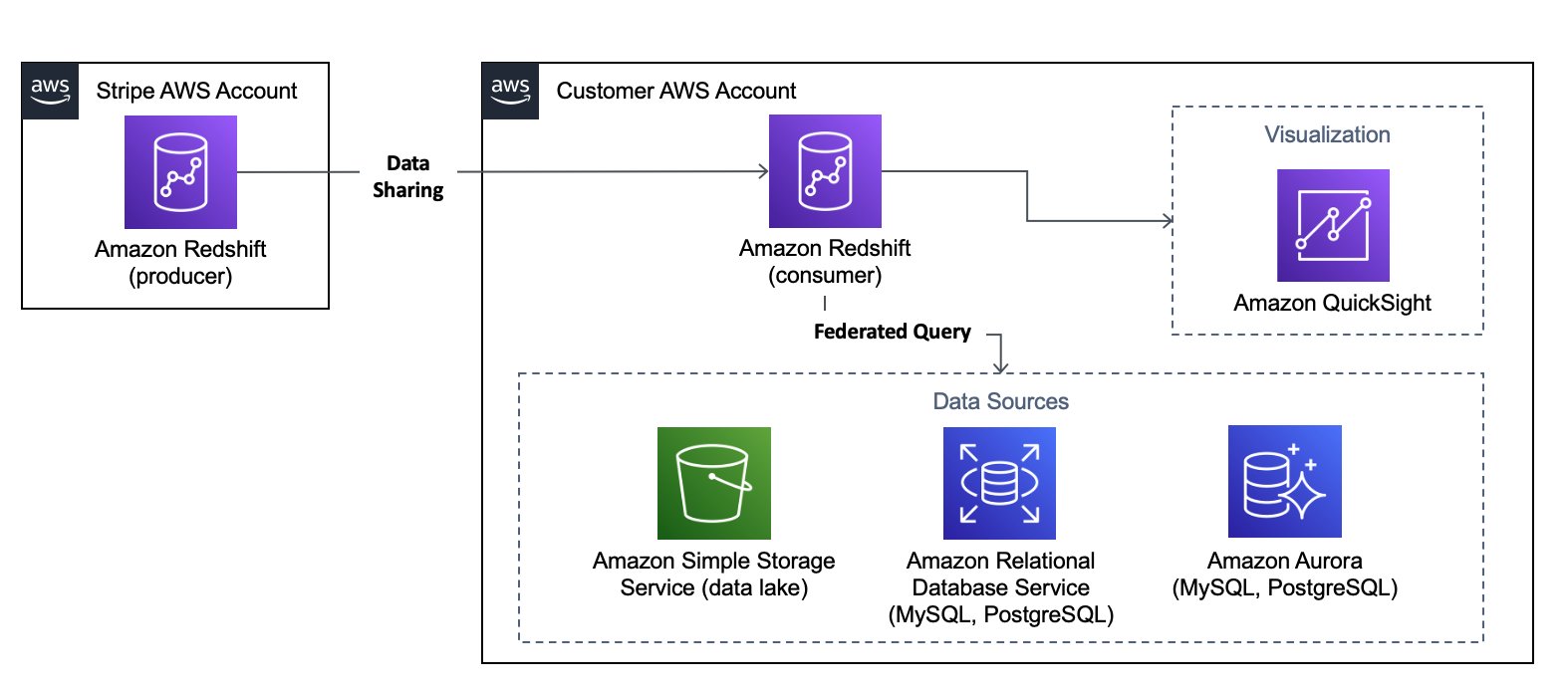
Ingest Stripe data in a fast and reliable way using Stripe Data Pipeline for Amazon Redshift
Enterprises typically host a myriad of business applications for varying data needs. As companies grow, so does the demand for insights from a complete set of business data. Having data from various applications that store data in disparate silos can delay the decision-making process. However, building and maintaining an API integration or a third-party extract, […]

Use a linear learner algorithm in Amazon Redshift ML to solve regression and classification problems
July 2024: This post was reviewed and updated for accuracy. Amazon Redshift is a fast, petabyte-scale cloud data warehouse delivering the best price–performance. Tens of thousands of customers use Amazon Redshift to process exabytes of data every day to power their analytics workloads. Amazon Redshift ML, powered by Amazon SageMaker, makes it easy for SQL […]

Federate single sign-on access to Amazon Redshift query editor v2 with Okta
Amazon Redshift query editor v2 is a web-based SQL client application that you can use to author and run queries on your Amazon Redshift data warehouse. You can visualize query results with charts and collaborate by sharing queries with members of your team. You can use query editor v2 to create databases, schemas, tables, and […]
Federate access to Amazon Redshift query editor V2 with Active Directory Federation Services (AD FS): Part 3
In the first post of this series, Federate access to your Amazon Redshift cluster with Active Directory Federation Services (AD FS): Part 1, you set up Microsoft Active Directory Federation Services (AD FS) and Security Assertion Markup Language (SAML) based authentication and tested the SAML federation using a web browser. In Part 2, you learned […]
Analyze Amazon SES events at scale using Amazon Redshift
Email is one of the most important methods for business communication across many organizations. It’s also one of the primary methods for many businesses to communicate with their customers. With the ever-increasing necessity to send emails at scale, monitoring and analysis has become a major challenge. Amazon Simple Email Service (Amazon SES) is a cost-effective, […]