AWS Big Data Blog
Category: Analytics

Reduce EMR HBase upgrade downtime with the EMR read-replica prewarm feature
In this post, we show you how the read-replica prewarm feature of Amazon EMR 7.12 improves HBase cluster operations by minimizing the hard cutover constraints that make infrastructure changes challenging. This feature gives you a consistent blue-green deployment pattern that reduces risk and downtime for version upgrades and security patches.

Modernize game intelligence with generative AI on Amazon Redshift
In this post, we discuss how you can use Amazon Redshift as a knowledge base to provide additional context to your LLM. We share best practices and explain how you can improve the accuracy of responses from the knowledge base by following these best practices.

Streamline your Amazon Redshift maintenance event notifications with Amazon Simple Notification Service
In this post, we take you through customization options for managing the schedule of your Amazon Redshift maintenance events, along with Amazon Redshift maintenance tracks for optimizing cluster performance. We also walk you through how to set up Amazon Redshift event notifications using Amazon SNS.

Get started faster with one-click onboarding, serverless notebooks, and AI agents in Amazon SageMaker Unified Studio
Using Amazon SageMaker Unified Studio serverless notebooks, AI-assisted development, and unified governance, you can speed up your data and AI workflows across data team functions while maintaining security and compliance. In this post, we walk you through how these new capabilities in SageMaker Unified Studio can help you consolidate your fragmented data tools, reduce time to insight, and collaborate across your data teams.
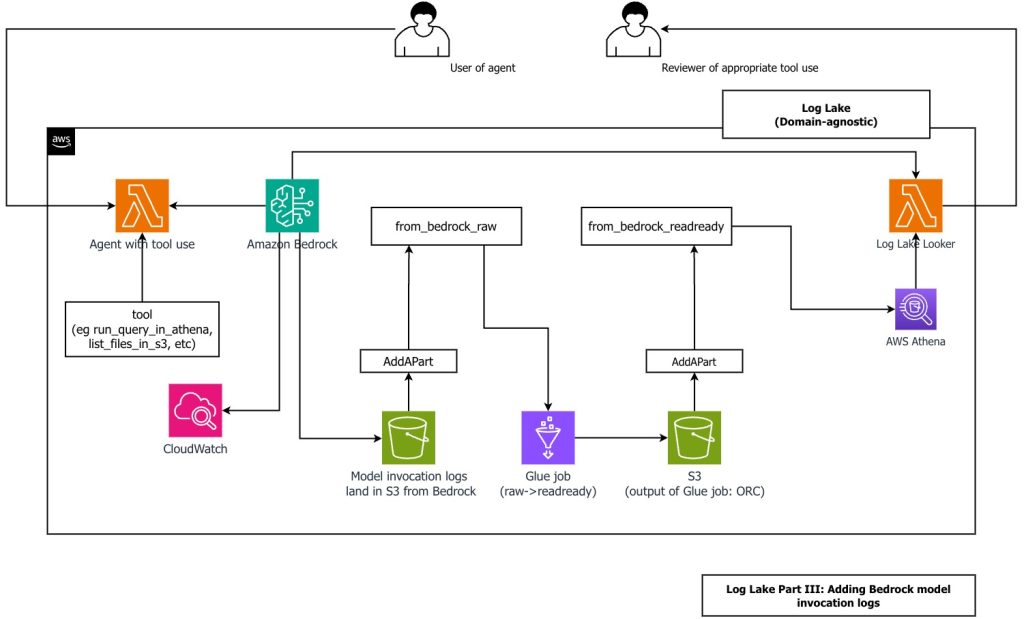
Create a customizable cross-company log lake, Part II: Build and add Amazon Bedrock
In this post, you learn how to build Log Lake, a customizable cross-company data lake for compliance-related use cases that combines AWS CloudTrail and Amazon CloudWatch logs. You’ll discover how to set up separate tables for writing and reading, implement event-driven partition management using AWS Lambda, and transform raw JSON files into read-optimized Apache ORC format using AWS Glue jobs. Additionally, you’ll see how to extend Log Lake by adding Amazon Bedrock model invocation logs to enable human review of agent actions with elevated permissions, and how to use an AI agent to query your log data without writing SQL.

Secure Apache Spark writes to Amazon S3 on Amazon EMR with dynamic AWS KMS encryption
When processing data at scale, many organizations use Apache Spark on Amazon EMR to run shared clusters that handle workloads across tenants, business units, or classification levels. In such multi-tenant environments, different datasets often require distinct AWS Key Management Service (AWS KMS) keys to enforce strict access controls and meet compliance requirements. At the same […]
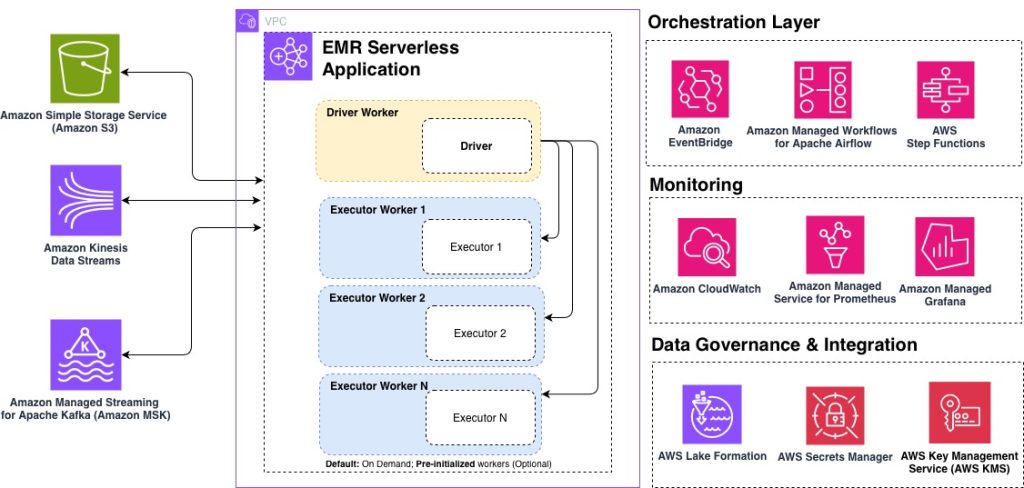
Top 10 best practices for Amazon EMR Serverless
Amazon EMR Serverless is a deployment option for Amazon EMR that you can use to run open source big data analytics frameworks such as Apache Spark and Apache Hive without having to configure, manage, or scale clusters and servers. Based on insights from hundreds of customer engagements, in this post, we share the top 10 best practices for optimizing your EMR Serverless workloads for performance, cost, and scalability. Whether you’re getting started with EMR Serverless or looking to fine-tune existing production workloads, these recommendations will help you build efficient, cost-effective data processing pipelines.
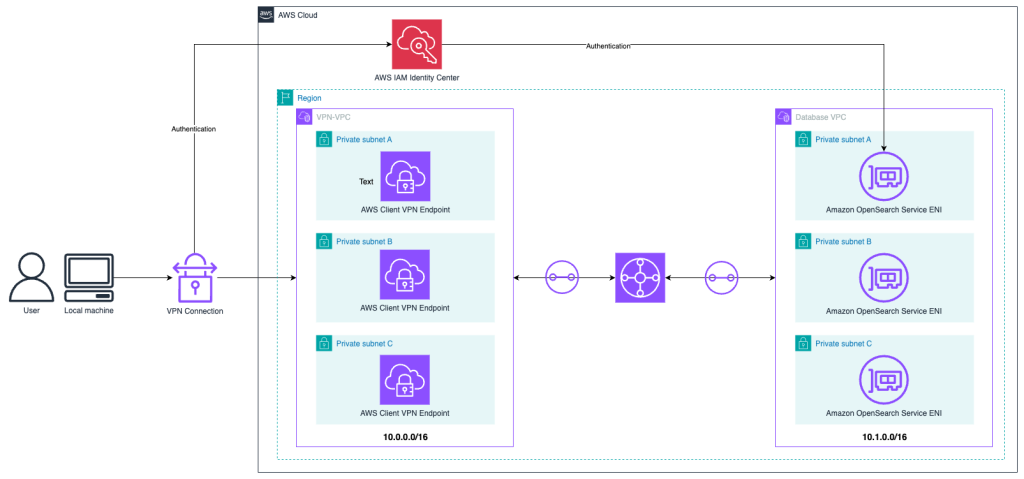
Access a VPC-hosted Amazon OpenSearch Service domain with SAML authentication using AWS Client VPN
In this post, we explore different OpenSearch Service authentication methods and network topology considerations. Then we show how to build an architecture to access an OpenSearch Service domain hosted in a VPC using AWS Client VPN, AWS Transit Gateway, and AWS IAM Identity Center.

Enable strategic data quality management with AWS Glue DQDL labels
AWS Glue DQDL labels add organizational context to data quality management by attaching business metadata directly to validation rules. In this post, we highlight the new DQDL labels feature, which enhances how you organize, prioritize, and operationalize your data quality efforts at scale. We show how labels such as business criticality, compliance requirements, team ownership, or data domain can be attached to data quality rules to streamline triage and analysis. You’ll learn how to quickly surface targeted insights (for example, “all high-priority customer data failures owned by marketing” or “GDPR-related issues from our Salesforce ingestion pipeline”) and how DQDL labels can help teams improve accountability and accelerate remediation workflows.

Apache Spark 4.0.1 preview now available on Amazon EMR Serverless
In this post, we explore key benefits, technical capabilities, and considerations for getting started with Spark 4.0.1 on Amazon EMR Serverless. With the emr-spark-8.0-preview release label, you can evaluate new SQL capabilities, Python API improvements, and streaming enhancements in your existing EMR Serverless environment.