AWS Big Data Blog
Category: Analytics

Resize Amazon Redshift from DC2 to RA3 with minimal or no downtime
Amazon Redshift is a popular cloud data warehouse that allows you to process exabytes of data across your data warehouse, operational database, and data lake using standard SQL. Amazon Redshift offers different node types like DC2 (dense compute) and RA3, which you can use for your different workloads and use cases. For more information about […]

Implement a CDC-based UPSERT in a data lake using Apache Iceberg and AWS Glue
May 2023: This post was reviewed and updated with code to read and write data to Iceberg table using Native iceberg connector, in the Appendix section. As the implementation of data lakes and modern data architecture increases, customers’ expectations around its features also increase, which include ACID transaction, UPSERT, time travel, schema evolution, auto compaction, […]

How GE Proficy Manufacturing Data Cloud replatformed to improve TCO, data SLA, and performance
This is post is co-authored by Jyothin Madari, Madhusudhan Muppagowni and Ayush Srivastava from GE. GE Proficy Manufacturing Data Cloud (MDC), part of the GE Digital’s Manufacturing Execution Systems (MES) suite of solutions, allows GED’s customers to increase the derived value easily and quickly from the MES by reliably bringing enterprise-wide manufacturing data into the […]

Optimize Federated Query Performance using EXPLAIN and EXPLAIN ANALYZE in Amazon Athena
Amazon Athena is an interactive query service that makes it easy to analyze data in Amazon Simple Storage Service (Amazon S3) using standard SQL. Athena is serverless, so there is no infrastructure to manage, and you pay only for the queries that you run. In 2019, Athena added support for federated queries to run SQL […]

Use an AD FS user and Tableau to securely query data in AWS Lake Formation
Security-conscious customers often adopt a Zero Trust security architecture. Zero Trust is a security model centered on the idea that access to data shouldn’t be solely based on network location, but rather require users and systems to prove their identities and trustworthiness and enforce fine-grained identity-based authorization rules before granting access to applications, data, and […]
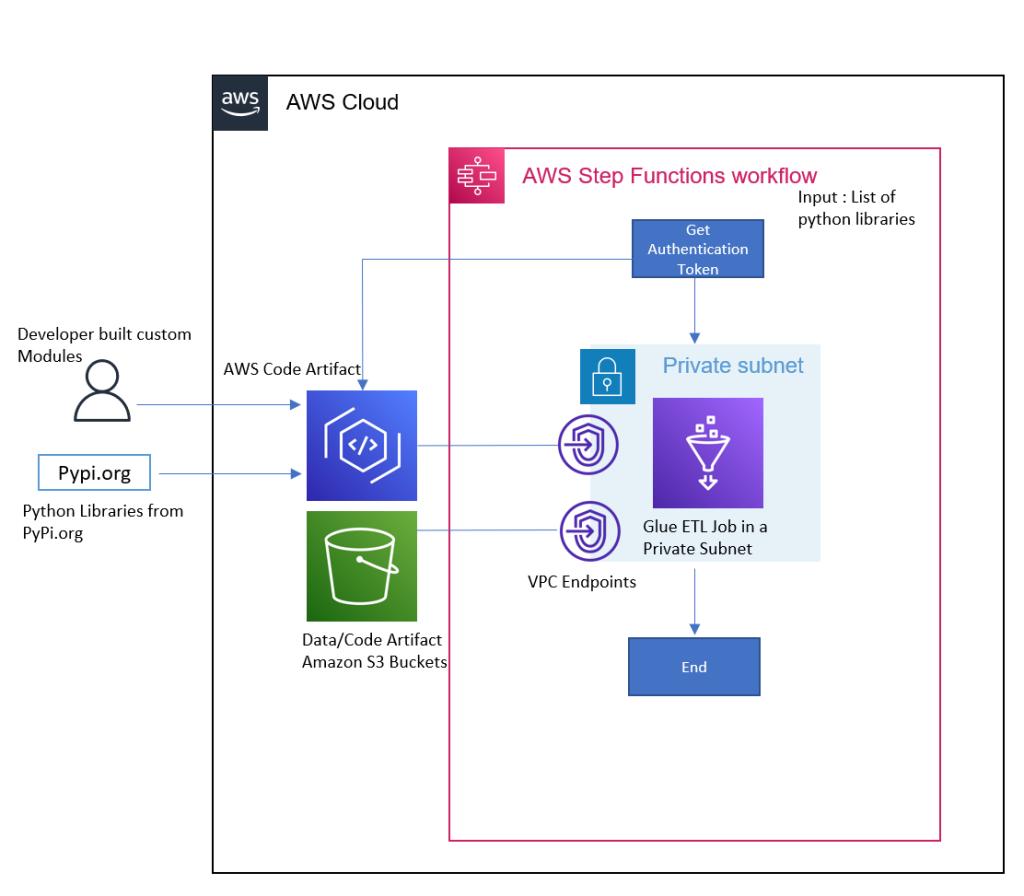
Simplify and optimize Python package management for AWS Glue PySpark jobs with AWS CodeArtifact
Data engineers use various Python packages to meet their data processing requirements while building data pipelines with AWS Glue PySpark Jobs. Languages like Python and Scala are commonly used in data pipeline development. Developers can take advantage of their open-source packages or even customize their own to make it easier and faster to perform use […]

Build a multilingual dashboard with Amazon Athena and Amazon QuickSight
Amazon QuickSight is a serverless business intelligence (BI) service used by organizations of any size to make better data-driven decisions. QuickSight dashboards can also be embedded into SaaS apps and web portals to provide interactive dashboards, natural language query or data analysis capabilities to app users seamlessly. The QuickSight Demo Central contains many dashboards, feature showcase […]
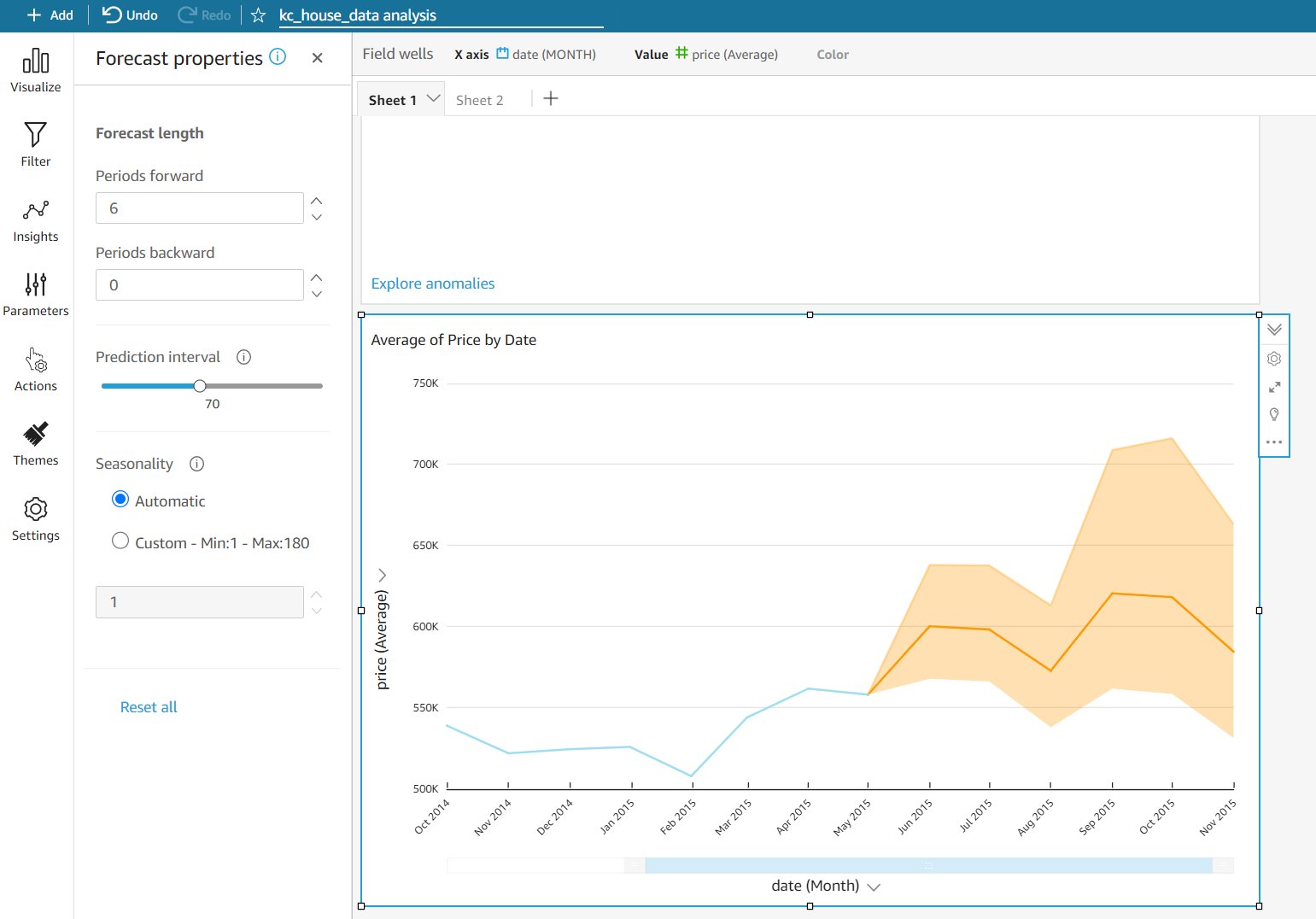
Introduction to Amazon QuickSight ML Insights
Amazon QuickSight was launched in November 2016 as a fast, cloud-powered business analytics service to build visualizations, perform ad hoc analysis, and quickly get business insights from a variety of data sources. In 2018, ML Insights for QuickSight (Enterprise Edition) was announced to add machine learning (ML)-powered forecasting and anomaly detection with a few clicks. […]

A serverless operational data lake for retail with AWS Glue, Amazon Kinesis Data Streams, Amazon DynamoDB, and Amazon QuickSight
Do you want to reduce stockouts at stores? Do you want to improve order delivery timelines? Do you want to provide your customers with accurate product availability, down to the millisecond? A retail operational data lake can help you transform the customer experience by providing deeper insights into a variety of operational aspects of your […]

Automate your validated dataset deployment using Amazon QuickSight and AWS CloudFormation
A lot of the power behind business intelligence (BI) and data visualization tools such as Amazon QuickSight comes from the ability to work interactively with data through a GUI. Report authors create dashboards using GUI-based tools, then in just a few clicks can share the dashboards with business users and decision-makers. This workflow empowers authors […]