AWS Big Data Blog
Category: Analytics

Position2’s Arena Calibrate helps customers drive marketing efficiency with Amazon QuickSight Embedded
This is a guest post by Vinod Nambiar from Position2. Position2 is a leading US-based growth marketing services provider focused on data-driven strategy and technology to deliver growth with improved return on investment (ROI). Position2 was established in 2006 in Silicon Valley and has a clientele spanning American Express, Lenovo, Fujitsu, and Thales. We work […]

Migrate from Amazon Kinesis Data Analytics for SQL Applications to Amazon Managed Service for Apache Flink Studio
February 9, 2024: Amazon Kinesis Data Firehose has been renamed to Amazon Data Firehose. Read the AWS What’s New post to learn more. August 30, 2023: Amazon Kinesis Data Analytics has been renamed to Amazon Managed Service for Apache Flink. Read the announcement in the AWS News Blog and learn more. In this post, we […]

Centralize near-real-time governance through alerts on Amazon Redshift data warehouses for sensitive queries
Amazon Redshift is a fully managed, petabyte-scale data warehouse service in the cloud that delivers powerful and secure insights on all your data with the best price-performance. With Amazon Redshift, you can analyze your data to derive holistic insights about your business and your customers. In many organizations, one or multiple Amazon Redshift data warehouses […]

Getting started guide for near-real time operational analytics using Amazon Aurora zero-ETL integration with Amazon Redshift
November 2023: This post was reviewed and updated to include the latest enhancements in Aurora MySQL zero-ETL integration with Amazon Redshift on general availability (GA). Amazon Aurora zero-ETL integration with Amazon Redshift was announced at AWS re:Invent 2022 and is now generally available (GA) for Aurora MySQL 3.05.0 (compatible with MySQL 8.0.32) and higher version […]

With a zero-ETL approach, AWS is helping builders realize near-real-time analytics
Data is at the center of every application, process, and business decision. When data is used to improve customer experiences and drive innovation, it can lead to business growth. According to Forrester, advanced insights-driven businesses are 8.5 times more likely than beginners to report at least 20% revenue growth. However, to realize this growth, managing […]

iostudio delivers key metrics to public sector recruiters with Amazon QuickSight
This is a guest post by Jon Walker and Ari Orlinsky from iostudio written in collaboration with Sumitha AP from AWS. iostudio is an award-winning marketing agency based in Nashville, TN. We build solutions that bring brands to life, making content and platforms work together. We serve our customers, who range from small technology startups […]

Harmonize data using AWS Glue and AWS Lake Formation FindMatches ML to build a customer 360 view
In today’s digital world, data is generated by a large number of disparate sources and growing at an exponential rate. Companies are faced with the daunting task of ingesting all this data, cleansing it, and using it to provide outstanding customer experience. Typically, companies ingest data from multiple sources into their data lake to derive […]

Enable business users to analyze large datasets in your data lake with Amazon QuickSight
This blog post is co-written with Ori Nakar from Imperva. Imperva Cloud WAF protects hundreds of thousands of websites and blocks billions of security events every day. Events and many other security data types are stored in Imperva’s Threat Research Multi-Region data lake. Imperva harnesses data to improve their business outcomes. To enable this transformation […]
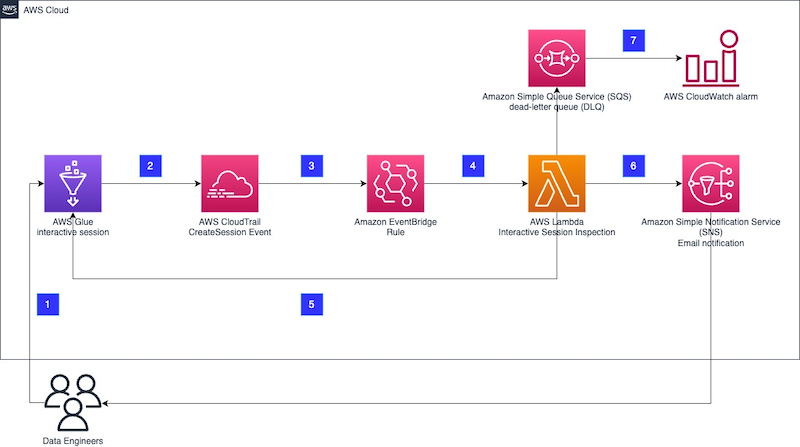
Enforce boundaries on AWS Glue interactive sessions
AWS Glue interactive sessions allow engineers to build, test, and run data preparation and analytics workloads in an interactive notebook. Interactive sessions provide isolated development environments, take care of the underlying compute cluster, and allow for configuration to stop idling resources. Glue interactive sessions provides default recommended configurations, and also allows users to customize the […]

Get started managing partitions for Amazon S3 tables backed by the AWS Glue Data Catalog
Large organizations processing huge volumes of data usually store it in Amazon Simple Storage Service (Amazon S3) and query the data to make data-driven business decisions using distributed analytics engines such as Amazon Athena. If you simply run queries without considering the optimal data layout on Amazon S3, it results in a high volume of […]