AWS Big Data Blog
Category: Advanced (300)

Using AWS AppSync and AWS Lake Formation to access a secure data lake through a GraphQL API
Data lakes have been gaining popularity for storing vast amounts of data from diverse sources in a scalable and cost-effective way. As the number of data consumers grows, data lake administrators often need to implement fine-grained access controls for different user profiles. They might need to restrict access to certain tables or columns depending on […]

Simplify data transfer: Google BigQuery to Amazon S3 using Amazon AppFlow
In today’s data-driven world, the ability to effortlessly move and analyze data across diverse platforms is essential. Amazon AppFlow, a fully managed data integration service, has been at the forefront of streamlining data transfer between AWS services, software as a service (SaaS) applications, and now Google BigQuery. In this blog post, you explore the new Google BigQuery connector in Amazon AppFlow and discover how it simplifies the process of transferring data from Google’s data warehouse to Amazon Simple Storage Service (Amazon S3), providing significant benefits for data professionals and organizations, including the democratization of multi-cloud data access.

Automate legacy ETL conversion to AWS Glue using Cognizant Data and Intelligence Toolkit (CDIT) – ETL Conversion Tool
In this post, we describe how Cognizant’s Data & Intelligence Toolkit (CDIT)- ETL Conversion Tool can help you automatically convert legacy ETL code to AWS Glue quickly and effectively. We also describe the main steps involved, the supported features, and their benefits.

Query big data with resilience using Trino in Amazon EMR with Amazon EC2 Spot Instances for less cost
New enhancements in Trino with Amazon EMR provide improved resiliency for running ETL and batch workloads on Spot Instances with reduced costs. This post showcases the resilience of Amazon EMR with Trino using fault-tolerant configuration to run long-running queries on Spot Instances to save costs. We simulate Spot interruptions on Trino worker nodes by using AWS Fault Injection Simulator (AWS FIS).
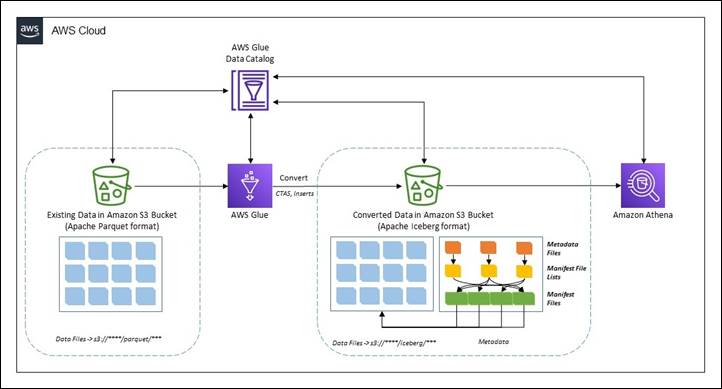
Migrate an existing data lake to a transactional data lake using Apache Iceberg
A data lake is a centralized repository that you can use to store all your structured and unstructured data at any scale. You can store your data as-is, without having to first structure the data and then run different types of analytics for better business insights. Over the years, data lakes on Amazon Simple Storage […]

Network connectivity patterns for Amazon OpenSearch Serverless
Amazon OpenSearch Serverless is an on-demand, auto-scaling configuration for Amazon OpenSearch Service. OpenSearch Serverless enables a broad set of use cases, such as real-time application monitoring, log analytics, and website search. OpenSearch Serverless lets you use OpenSearch without having to worry about scaling and managing an OpenSearch cluster. A collection can be accessed over the […]

Use the new SQL commands MERGE and QUALIFY to implement and validate change data capture in Amazon Redshift
Amazon Redshift has added many features to enhance analytical processing like ROLLUP, CUBE and GROUPING SETS, which were demonstrated in the post Simplify Online Analytical Processing (OLAP) queries in Amazon Redshift using new SQL constructs such as ROLLUP, CUBE, and GROUPING SETS. Amazon Redshift has recently added many SQL commands and expressions. In this post, we talk about two new SQL features, the MERGE command and QUALIFY clause, which simplify data ingestion and data filtering.

Externalize Amazon MSK Connect configurations with Terraform
Managing configurations for Amazon MSK Connect, a feature of Amazon Managed Streaming for Apache Kafka (Amazon MSK), can become challenging, especially as the number of topics and configurations grows. In this post, we address this complexity by using Terraform to optimize the configuration of the Kafka topic to Amazon S3 Sink connector. By adopting this […]
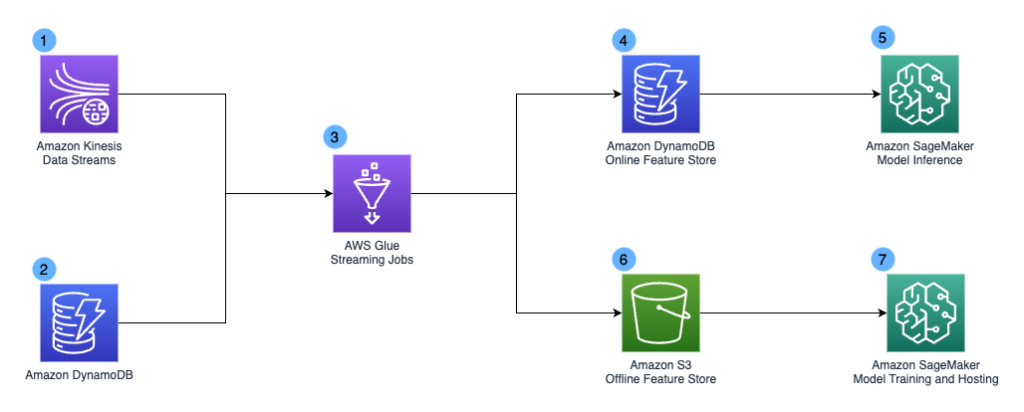
How Chime Financial uses AWS to build a serverless stream analytics platform and defeat fraudsters
This is a guest post by Khandu Shinde, Staff Software Engineer and Edward Paget, Senior Software Engineering at Chime Financial. Chime is a financial technology company founded on the premise that basic banking services should be helpful, easy, and free. Chime partners with national banks to design member first financial products. This creates a more […]

Optimize checkpointing in your Amazon Managed Service for Apache Flink applications with buffer debloating and unaligned checkpoints – Part 2
February 2024: This post was reviewed and updated for accuracy. This post is a continuation of a two-part series. In the first part, we delved into Apache Flink‘s internal mechanisms for checkpointing, in-flight data buffering, and handling backpressure. We covered these concepts in order to understand how buffer debloating and unaligned checkpoints allow us to […]