AWS Big Data Blog
Category: Advanced (300)

Federate access to Amazon SageMaker Unified Studio with AWS IAM Identity Center and Ping Identity
In this post, we show how to set up workforce access with SageMaker Unified Studio using Ping Identity as an external IdP with IAM Identity Center.
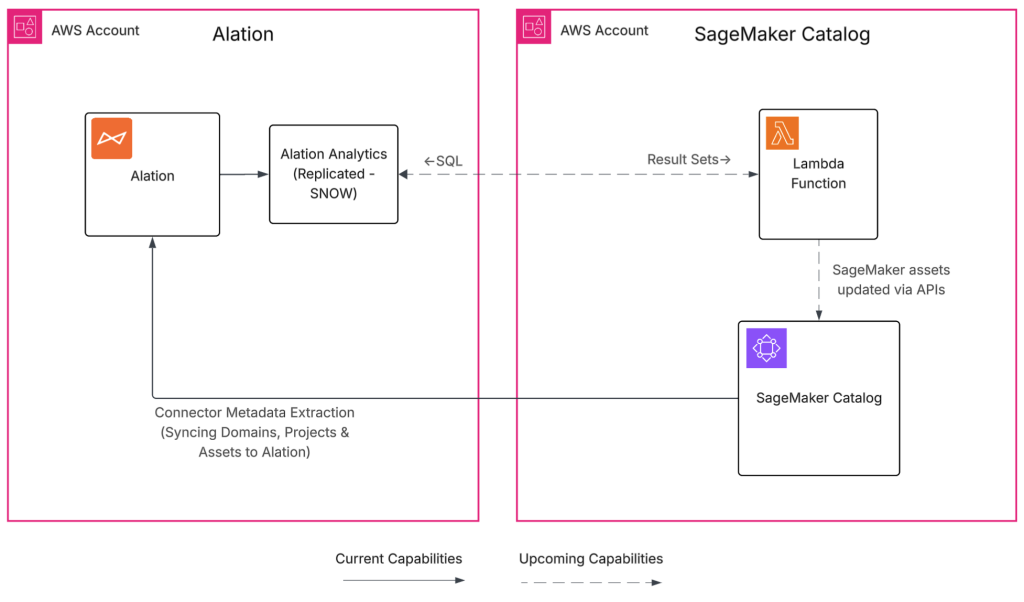
Build a trusted foundation for data and AI using Alation and Amazon SageMaker Unified Studio
The Alation and SageMaker Unified Studio integration helps organizations bridge the gap between fast analytics and ML development and the governance requirements most enterprises face. By cataloging metadata from SageMaker Unified Studio in Alation, you gain a governed, discoverable view of how assets are created and used. In this post, we demonstrate who benefits from this integration, how it works, the specific metadata it synchronizes, and provide a complete deployment guide for your environment.

Reduce EMR HBase upgrade downtime with the EMR read-replica prewarm feature
In this post, we show you how the read-replica prewarm feature of Amazon EMR 7.12 improves HBase cluster operations by minimizing the hard cutover constraints that make infrastructure changes challenging. This feature gives you a consistent blue-green deployment pattern that reduces risk and downtime for version upgrades and security patches.
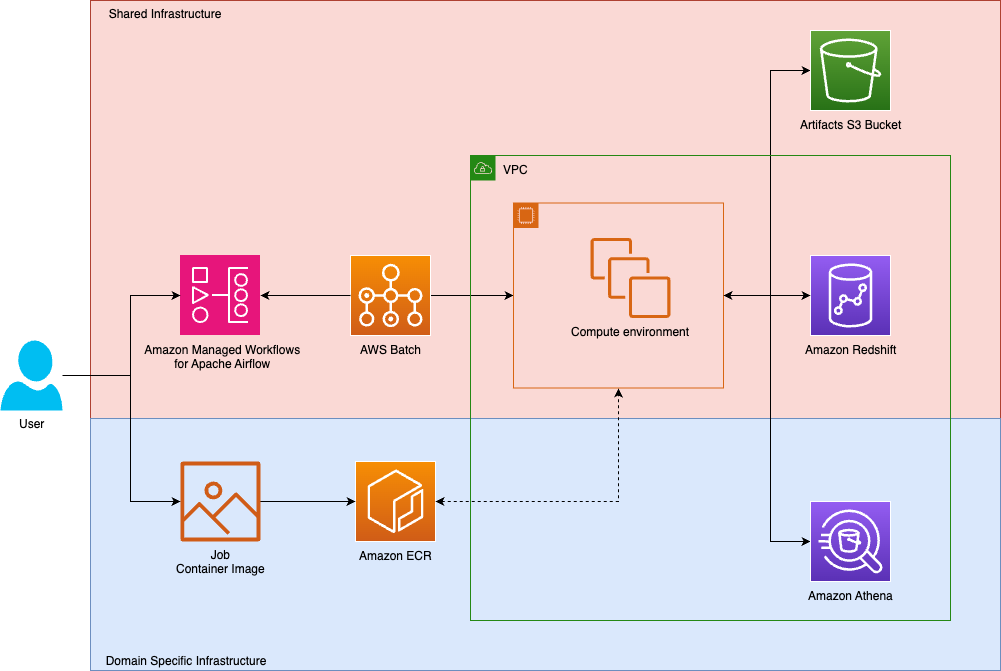
How Tipico democratized data transformations using Amazon Managed Workflows for Apache Airflow and AWS Batch
Tipico is the number one name in sports betting in Germany. Every day, we connect millions of fans to the thrill of sport, combining technology, passion, and trust to deliver fast, secure, and exciting betting, both online and in more than a thousand retail shops across Germany. We also bring this experience to Austria, where we proudly operate a strong sports betting business. In this post, we show how Tipico built a unified data transformation platform using Amazon Managed Workflows for Apache Airflow (Amazon MWAA) and AWS Batch.

Modernize game intelligence with generative AI on Amazon Redshift
In this post, we discuss how you can use Amazon Redshift as a knowledge base to provide additional context to your LLM. We share best practices and explain how you can improve the accuracy of responses from the knowledge base by following these best practices.

Streamline your Amazon Redshift maintenance event notifications with Amazon Simple Notification Service
In this post, we take you through customization options for managing the schedule of your Amazon Redshift maintenance events, along with Amazon Redshift maintenance tracks for optimizing cluster performance. We also walk you through how to set up Amazon Redshift event notifications using Amazon SNS.
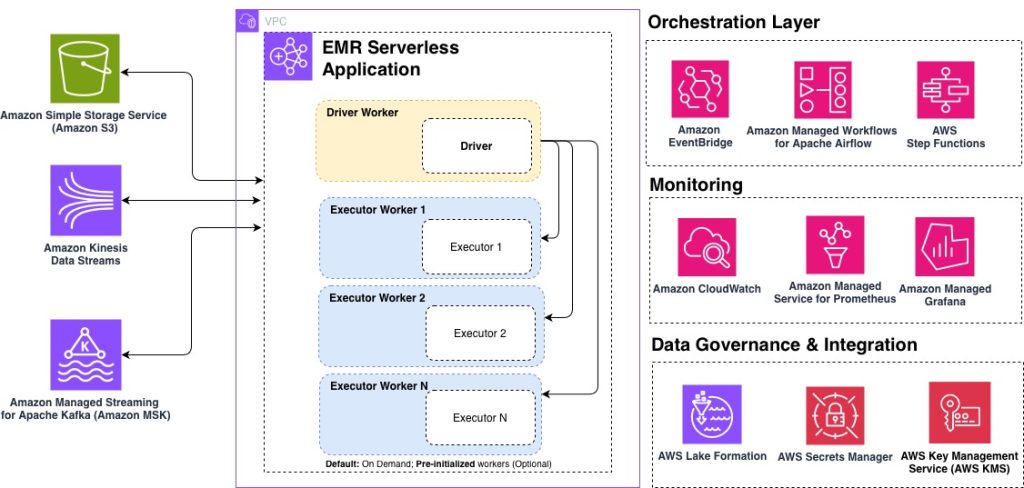
Top 10 best practices for Amazon EMR Serverless
Amazon EMR Serverless is a deployment option for Amazon EMR that you can use to run open source big data analytics frameworks such as Apache Spark and Apache Hive without having to configure, manage, or scale clusters and servers. Based on insights from hundreds of customer engagements, in this post, we share the top 10 best practices for optimizing your EMR Serverless workloads for performance, cost, and scalability. Whether you’re getting started with EMR Serverless or looking to fine-tune existing production workloads, these recommendations will help you build efficient, cost-effective data processing pipelines.
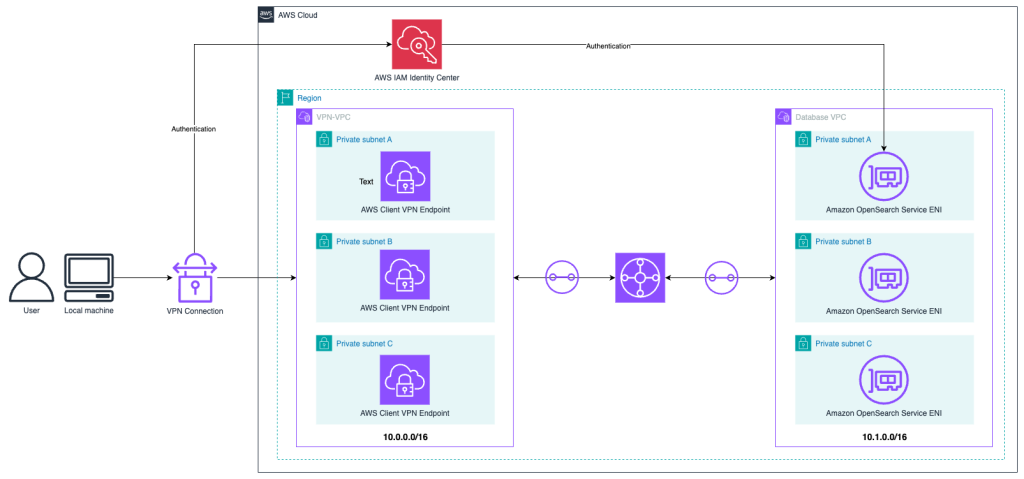
Access a VPC-hosted Amazon OpenSearch Service domain with SAML authentication using AWS Client VPN
In this post, we explore different OpenSearch Service authentication methods and network topology considerations. Then we show how to build an architecture to access an OpenSearch Service domain hosted in a VPC using AWS Client VPN, AWS Transit Gateway, and AWS IAM Identity Center.

Apache Spark 4.0.1 preview now available on Amazon EMR Serverless
In this post, we explore key benefits, technical capabilities, and considerations for getting started with Spark 4.0.1 on Amazon EMR Serverless. With the emr-spark-8.0-preview release label, you can evaluate new SQL capabilities, Python API improvements, and streaming enhancements in your existing EMR Serverless environment.

Modernize your data warehouse by migrating Oracle Database to Amazon Redshift with Oracle GoldenGate
In this post, we show how to migrate an Oracle data warehouse to Amazon Redshift using Oracle GoldenGate and DMS Schema Conversion, a feature of AWS Database Migration Service (AWS DMS). This approach facilitates minimal business disruption through continuous replication.