AWS Big Data Blog
Category: Technical How-to

Build a serverless log analytics pipeline using Amazon OpenSearch Ingestion with managed Amazon OpenSearch Service
In this post, we show how to build a log ingestion pipeline using the new Amazon OpenSearch Ingestion, a fully managed data collector that delivers real-time log and trace data to Amazon OpenSearch Service domains. OpenSearch Ingestion is powered by the open-source data collector Data Prepper. Data Prepper is part of the open-source OpenSearch project. […]

Level up your React app with Amazon QuickSight: How to embed your dashboard for anonymous access
Using embedded analytics from Amazon QuickSight can simplify the process of equipping your application with functional visualizations without any complex development. There are multiple ways to embed QuickSight dashboards into application. In this post, we look at how it can be done using React and the Amazon QuickSight Embedding SDK. Dashboard consumers often don’t have […]

Access Amazon OpenSearch Serverless collections using a VPC endpoint
Amazon OpenSearch Serverless helps you index, analyze, and search your logs and data using OpenSearch APIs and dashboards. The OpenSearch Serverless collection is a group of indexes. API and dashboard clients can access the collections from public networks or one or more VPCs. For VPC access to collections and dashboards, you can create VPC endpoints. […]

Backtesting index rebalancing arbitrage with Amazon EMR and Apache Iceberg
Backtesting is a process used in quantitative finance to evaluate trading strategies using historical data. This helps traders determine the potential profitability of a strategy and identify any risks associated with it, enabling them to optimize it for better performance. Index rebalancing arbitrage takes advantage of short-term price discrepancies resulting from ETF managers’ efforts to […]

Migrate from Amazon Kinesis Data Analytics for SQL Applications to Amazon Managed Service for Apache Flink Studio
February 9, 2024: Amazon Kinesis Data Firehose has been renamed to Amazon Data Firehose. Read the AWS What’s New post to learn more. August 30, 2023: Amazon Kinesis Data Analytics has been renamed to Amazon Managed Service for Apache Flink. Read the announcement in the AWS News Blog and learn more. February 9, 2024: Amazon […]

Centralize near-real-time governance through alerts on Amazon Redshift data warehouses for sensitive queries
Amazon Redshift is a fully managed, petabyte-scale data warehouse service in the cloud that delivers powerful and secure insights on all your data with the best price-performance. With Amazon Redshift, you can analyze your data to derive holistic insights about your business and your customers. In many organizations, one or multiple Amazon Redshift data warehouses […]

Harmonize data using AWS Glue and AWS Lake Formation FindMatches ML to build a customer 360 view
In today’s digital world, data is generated by a large number of disparate sources and growing at an exponential rate. Companies are faced with the daunting task of ingesting all this data, cleansing it, and using it to provide outstanding customer experience. Typically, companies ingest data from multiple sources into their data lake to derive […]
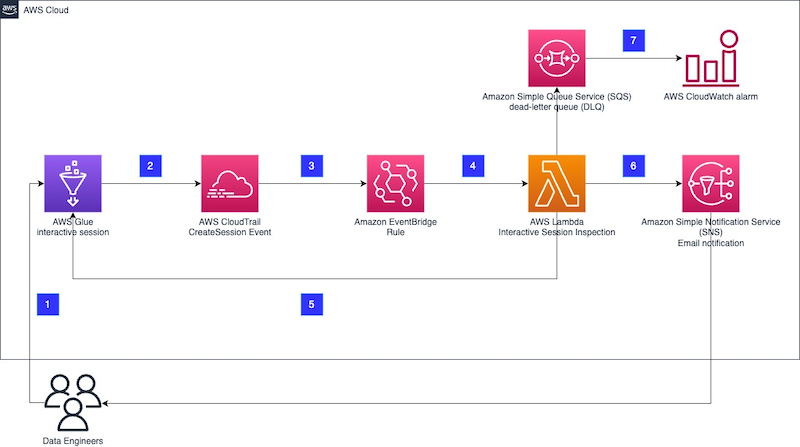
Enforce boundaries on AWS Glue interactive sessions
AWS Glue interactive sessions allow engineers to build, test, and run data preparation and analytics workloads in an interactive notebook. Interactive sessions provide isolated development environments, take care of the underlying compute cluster, and allow for configuration to stop idling resources. Glue interactive sessions provides default recommended configurations, and also allows users to customize the […]

Stream VPC Flow Logs to Datadog via Amazon Kinesis Data Firehose
February 9, 2024: Amazon Kinesis Data Firehose has been renamed to Amazon Data Firehose. Read the AWS What’s New post to learn more. It’s common to store the logs generated by customer’s applications and services in various tools. These logs are important for compliance, audits, troubleshooting, security incident responses, meeting security policies, and many other […]

Multi-tenancy Apache Kafka clusters in Amazon MSK with IAM access control and Kafka Quotas – Part 1
With Amazon Managed Streaming for Apache Kafka (Amazon MSK), you can build and run applications that use Apache Kafka to process streaming data. To process streaming data, organizations either use multiple Kafka clusters based on their application groupings, usage scenarios, compliance requirements, and other factors, or a dedicated Kafka cluster for the entire organization. It […]