AWS Big Data Blog
Category: Serverless

Introducing AWS Glue interactive sessions for Jupyter
Interactive Sessions for Jupyter is a new notebook interface in the AWS Glue serverless Spark environment. Starting in seconds and automatically stopping compute when idle, interactive sessions provide an on-demand, highly-scalable, serverless Spark backend to Jupyter notebooks and Jupyter-based IDEs such as Jupyter Lab, Microsoft Visual Studio Code, JetBrains PyCharm, and more. Interactive sessions replace […]

AWS Glue Python shell now supports Python 3.9 with a flexible pre-loaded environment and support to install additional libraries
AWS Glue is the central service of an AWS modern data architecture. It is a serverless data integration service that allows you to discover, prepare, and combine data for analytics and machine learning. AWS Glue offers you a comprehensive range of tools to perform ETL (extract, transform, and load) at the right scale. AWS Glue […]

Build a pseudonymization service on AWS to protect sensitive data: Part 1
According to an article in MIT Sloan Management Review, 9 out of 10 companies believe their industry will be digitally disrupted. In order to fuel the digital disruption, companies are eager to gather as much data as possible. Given the importance of this new asset, lawmakers are keen to protect the privacy of individuals and […]
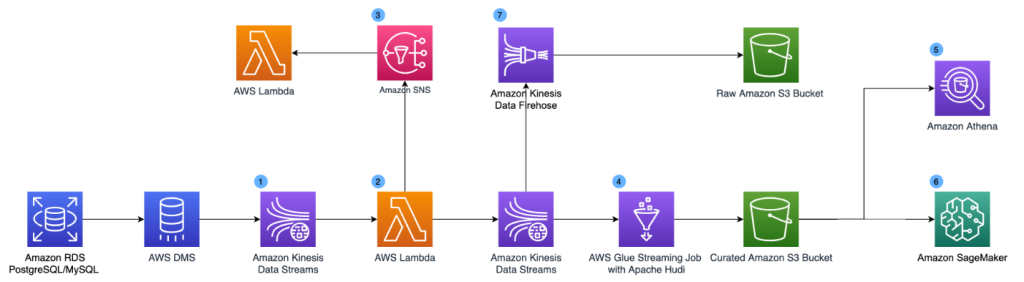
How NerdWallet uses AWS and Apache Hudi to build a serverless, real-time analytics platform
This is a guest post by Kevin Chun, Staff Software Engineer in Core Engineering at NerdWallet. NerdWallet’s mission is to provide clarity for all of life’s financial decisions. This covers a diverse set of topics: from choosing the right credit card, to managing your spending, to finding the best personal loan, to refinancing your mortgage. […]

Introducing AWS Glue Flex jobs: Cost savings on ETL workloads
AWS Glue is a serverless data integration service that makes it simple to discover, prepare, and combine data for analytics, machine learning (ML), and application development. You can use AWS Glue to create, run, and monitor data integration and ETL (extract, transform, and load) pipelines and catalog your assets across multiple data stores. Typically, these […]

Best practices to optimize cost and performance for AWS Glue streaming ETL jobs
AWS Glue streaming extract, transform, and load (ETL) jobs allow you to process and enrich vast amounts of incoming data from systems such as Amazon Kinesis Data Streams, Amazon Managed Streaming for Apache Kafka (Amazon MSK), or any other Apache Kafka cluster. It uses the Spark Structured Streaming framework to perform data processing in near-real […]

How Epos Now modernized their data platform by building an end-to-end data lake with the AWS Data Lab
Epos Now provides point of sale and payment solutions to over 40,000 hospitality and retailers across 71 countries. Their mission is to help businesses of all sizes reach their full potential through the power of cloud technology, with solutions that are affordable, efficient, and accessible. Their solutions allow businesses to leverage actionable insights, manage their […]

Use SQL queries to define Amazon Redshift datasets in AWS Glue DataBrew
July 2023: This post was reviewed for accuracy. In the post Data preparation using Amazon Redshift with AWS Glue DataBrew, we saw how to create an AWS Glue DataBrew job using a JDBC connection for Amazon Redshift. In this post, we show you how to create a DataBrew profile job and a recipe job using […]

Process Apache Hudi, Delta Lake, Apache Iceberg dataset at scale, part 2: Using AWS Glue Studio Visual Editor
June 2023: This post was reviewed and updated for accuracy. AWS Glue supports native integration with Apache Hudi, Delta Lake, and Apache Iceberg. Refer to Introducing native support for Apache Hudi, Delta Lake, and Apache Iceberg on AWS Glue for Apache Spark, Part 2: AWS Glue Studio Visual Editor to learn more. Transactional data lake […]

Process Apache Hudi, Delta Lake, Apache Iceberg datasets at scale, part 1: AWS Glue Studio Notebook
August 2023: This post was reviewed and updated for accuracy. AWS Glue supports native integration with Apache Hudi, Delta Lake, and Apache Iceberg. Refer to Introducing native support for Apache Hudi, Delta Lake, and Apache Iceberg on AWS Glue for Apache Spark, Part 2: AWS Glue Studio Visual Editor to learn more. Cloud data lakes […]