AWS Big Data Blog
Category: Storage

Analyze Amazon S3 storage costs using AWS Cost and Usage Reports, Amazon S3 Inventory, and Amazon Athena
Since its launch in 2006, Amazon Simple Storage Service (Amazon S3) has experienced major growth, supporting multiple use cases such as hosting websites, creating data lakes, serving as object storage for consumer applications, storing logs, and archiving data. As the application portfolio grows, customers tend to store data from multiple application and different business functions […]

How BookMyShow saved 80% in costs by migrating to an AWS modern data architecture
This is a guest post co-authored by Mahesh Vandi Chalil, Chief Technology Officer of BookMyShow. BookMyShow (BMS), a leading entertainment company in India, provides an online ticketing platform for movies, plays, concerts, and sporting events. Selling up to 200 million tickets on an annual run rate basis (pre-COVID) to customers in India, Sri Lanka, Singapore, […]

How GoDaddy built a data mesh to decentralize data ownership using AWS Lake Formation
This is a guest post co-written with Ankit Jhalaria from GoDaddy. GoDaddy is empowering everyday entrepreneurs by providing all the help and tools to succeed online. With more than 20 million customers worldwide, GoDaddy is the place people come to name their idea, build a professional website, attract customers, and manage their work. GoDaddy is […]

Get started with data integration from Amazon S3 to Amazon Redshift using AWS Glue interactive sessions
Organizations are placing a high priority on data integration, especially to support analytics, machine learning (ML), business intelligence (BI), and application development initiatives. Data is growing exponentially and is generated by increasingly diverse data sources. Data integration becomes challenging when processing data at scale and the inherent heavy lifting associated with infrastructure required to manage […]

How a blockchain startup built a prototype solution to solve the need of analytics for decentralized applications with AWS Data Lab
February 9, 2024: Amazon Kinesis Data Firehose has been renamed to Amazon Data Firehose. Read the AWS What’s New post to learn more. This post is co-written with Dr. Quan Hoang Nguyen, CTO at Fantom Foundation. Here at Fantom Foundation (Fantom), we have developed a high performance, highly scalable, and secure smart contract platform. It’s […]

Build incremental crawls of data lakes with existing Glue catalog tables
AWS Glue includes crawlers, a capability that make discovering datasets simpler by scanning data in Amazon Simple Storage Service (Amazon S3) and relational databases, extracting their schema, and automatically populating the AWS Glue Data Catalog, which keeps the metadata current. This reduces the time to insight by making newly ingested data quickly available for analysis […]
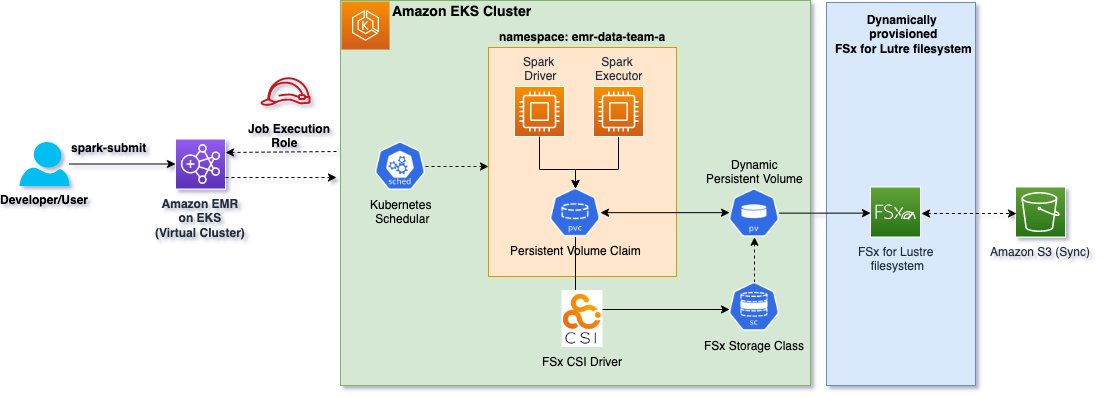
Run Apache Spark with Amazon EMR on EKS backed by Amazon FSx for Lustre storage
September 2023: This post was reviewed and updated for accuracy to reflect recent improvements and changes. Traditionally, Spark workloads have been run on a dedicated setup like a Hadoop stack with YARN or MESOS as a resource manager. Starting from Apache Spark 2.3, Spark added support for Kubernetes as a resource manager. The new Kubernetes […]

Convert Oracle XML BLOB data using Amazon EMR and load to Amazon Redshift
In legacy relational database management systems, data is stored in several complex data types, such XML, JSON, BLOB, or CLOB. This data might contain valuable information that is often difficult to transform into insights, so you might be looking for ways to load and use this data in a modern cloud data warehouse such as […]

Optimize Federated Query Performance using EXPLAIN and EXPLAIN ANALYZE in Amazon Athena
Amazon Athena is an interactive query service that makes it easy to analyze data in Amazon Simple Storage Service (Amazon S3) using standard SQL. Athena is serverless, so there is no infrastructure to manage, and you pay only for the queries that you run. In 2019, Athena added support for federated queries to run SQL […]

Build a big data Lambda architecture for batch and real-time analytics using Amazon Redshift
February 9, 2024: Amazon Kinesis Data Firehose has been renamed to Amazon Data Firehose. Read the AWS What’s New post to learn more. With real-time information about customers, products, and applications in hand, organizations can take action as events happen in their business application. For example, you can prevent financial fraud, deliver personalized offers, and […]