AWS Big Data Blog
Generic orchestration framework for data warehousing workloads using Amazon Redshift RSQL
Tens of thousands of customers run business-critical workloads on Amazon Redshift, AWS’s fast, petabyte-scale cloud data warehouse delivering the best price-performance. With Amazon Redshift, you can query data across your data warehouse, operational data stores, and data lake using standard SQL. You can also integrate AWS services like Amazon EMR, Amazon Athena, Amazon SageMaker, AWS Glue, AWS Lake Formation, and Amazon Kinesis to take advantage of all of the analytic capabilities in the AWS Cloud.
Amazon Redshift RSQL is a native command-line client for interacting with Amazon Redshift clusters and databases. You can connect to an Amazon Redshift cluster, describe database objects, query data, and view query results in various output formats. You can use Amazon Redshift RSQL to replace existing extract, transform, load (ETL) and automation scripts, such as Teradata BTEQ scripts. You can wrap Amazon Redshift RSQL statements within a shell script to replicate existing functionality in the on-premise systems. Amazon Redshift RSQL is available for Linux, Windows, and macOS operating systems.
This post explains how you can create a generic configuration-driven orchestration framework using AWS Step Functions, Amazon Elastic Compute Cloud (Amazon EC2), AWS Lambda, Amazon DynamoDB, and AWS Systems Manager to orchestrate RSQL-based ETL workloads. If you’re migrating from legacy data warehouse workloads to Amazon Redshift, you can use this methodology to orchestrate your data warehousing workloads.
Solution overview
Customers migrating from legacy data warehouses to Amazon Redshift may have a significant investment in proprietary scripts like Basic Teradata Query (BTEQ) scripting for database automation, ETL, or other tasks. You can now use the AWS Schema Conversion Tool (AWS SCT) to automatically convert proprietary scripts like BTEQ scripts to Amazon Redshift RSQL scripts. The converted scripts run on Amazon Redshift with little to no changes. To learn about new options for database scripting, refer to Accelerate your data warehouse migration to Amazon Redshift – Part 4.
During such migrations, you may also want to modernize your current on-premises, third-party orchestration tools with a cloud-native framework to replicate and enhance your current orchestration capability. Orchestrating data warehouse workloads includes scheduling the jobs, checking if the pre-conditions have been met, running the business logic embedded within RSQL, monitoring the status of the jobs, and alerting if there are any failures.
This solution allows on-premises customers to migrate to a cloud-native orchestration framework that uses AWS serverless services such as Step Functions, Lambda, DynamoDB, and Systems Manager to run the Amazon Redshift RSQL jobs deployed on a persistent EC2 instance. You can also deploy the solution for greenfield implementations. In addition to meeting functional requirements, this solution also provides full auditing, logging, and monitoring of all ETL and ELT processes that are run.
To ensure high availability and resilience, you can use multiple EC2 instances that are a part of an auto scaling group along with Amazon Elastic File System (Amazon EFS) to deploy and run the RSQL jobs. When using auto scaling groups, you can install RSQL onto the EC2 instance as a part of the bootstrap script. You can also deploy the Amazon Redshift RSQL scripts onto the EC2 instance using AWS CodePipeline and AWS CodeDeploy. For more details, refer to Auto Scaling groups, the Amazon EFT User Guide, and Integrating CodeDeploy with Amazon EC2 Auto Scaling.
The following diagram illustrates the architecture of the orchestration framework.

The key components of the framework are as follows:
- Amazon EventBridge is used as the ETL workflow scheduler, and it triggers a Lambda function at a preset schedule.
- The function queries a DynamoDB table for the configuration associated to the RSQL job and queries the status of the job, run mode, and restart information for that job.
- After receiving the configuration, the function triggers a Step Functions state machine by passing the configuration details.
- Step Functions starts running different stages (like configuration iteration, run type check, and more) of the workflow.
- Step Functions uses the Systems Manager
SendCommandAPI to trigger the RSQL job and goes into a paused state withTaskToken. The RSQL scripts are persisted on an EC2 instance and are wrapped in a shell script. Systems Manager runs anAWS-RunShellScriptSSM document to run the RSQL job on the EC2 instance. - The RSQL job performs ETL and ELT operations on the Amazon Redshift cluster. When it’s complete, it returns a success/failure code and status message back to the calling shell script.
- The shell script calls a custom Python module with the success/failure code, status message, and the callwait
TaskTokenthat was received from Step Functions. The Python module logs the RSQL job status in the job audit DynamoDB audit table, and exports logs to the Amazon CloudWatch log group. - The Python module then performs a
SendTaskSuccessorSendTaskFailureAPI call based on the RSQL job run status. Based on the status of the RSQL job, Step Functions either resumes the flow or stops with failure. - Step Functions logs the workflow status (success or failure) in the DynamoDB workflow audit table.
Prerequisites
You should have the following prerequisites:
- An AWS account.
- The AWS Cloud Development Kit (AWS CDK) installed on the development environment. For more information, refer to Prerequisites.
- An Amazon Redshift cluster.
- Amazon Redshift database credentials stored in AWS Secrets Manager. For more information, refer to Storing database credentials in AWS Secrets Manager. After you create the secret, modify it to add the name of the Amazon Redshift database with the secret key
dbname. For instructions, refer to Modify an AWS Secrets Manager secret. - An Amazon Linux 2 EC2 instance with Amazon Redshift RSQL installed.
Deploy AWS CDK stacks
Complete the following steps to deploy your resources using the AWS CDK:
- Clone the GitHub repo:
- Update the following the environment parameters in
cdk.json(this file can be found in the infra directory):- ec2_instance_id – The EC2 instance ID on which RSQL jobs are deployed
- redshift_secret_id – The name of the Secrets Manager key that stores the Amazon Redshift database credentials
- rsql_script_path – The absolute directory path in the EC2 instance where the RSQL jobs are stored
- rsql_log_path – The absolute directory path in the EC2 instance used for storing the RSQL job logs
- rsql_script_wrapper – The absolute directory path of the RSQL wrapper script (rsql_trigger.sh) on the EC2 instance.
The following is a sample
cdk.jsonfile after being populated with the parameters - Deploy the AWS CDK stack with the following code:
Let’s look at the resources the AWS CDK stack deploys in more detail.
CloudWatch log group
A CloudWatch log group (/ops/rsql-logs/) is created, which is used to store, monitor, and access log files from EC2 instances and other sources.
The log group is used to store the RSQL job run logs. For each RSQL script, all the stdout and stderr logs are stored as a log stream within this log group.
DynamoDB configuration table
The DynamoDB configuration table (rsql-blog-rsql-config-table) is the basic building block of this solution. All the RSQL jobs, restart information and run mode (sequential or parallel), and sequence in which the jobs are to be run are stored in this configuration table.
The table has the following structure:
- workflow_id – The identifier for the RSQL-based ETL workflow.
- workflow_description – The description for the RSQL-based ETL workflow.
- workflow_stages – The sequence of stages within a workflow.
- execution_type – The type of run for RSQL jobs (sequential or parallel).
- stage_description – The description for the stage.
- scripts – The list of RSQL scripts to be run. The RSQL scripts must be placed in the location defined in a later step.
The following is an example of an entry in the configuration table. You can see the workflow_id is blog_test_workflow and the description is Test Workflow for Blog.
It has three stages that are triggered in the following order: Schema & Table Creation Stage, Data Insertion Stage 1, and Data Insertion Stage 2. The stage Schema & Table Creation Stage has two RSQL jobs running sequentially, and Data Insertion Stage 1 and Data Insertion Stage 2 each have two jobs running in parallel.
DynamoDB audit tables
The audit tables store the run details for each RSQL job within the ETL workflow with a unique identifier for monitoring and reporting purposes. The reason why there are two audit tables is because one table stores the audit information at a RSQL job level and the other stores it at a workflow level.
The job audit table (rsql-blog-rsql-job-audit-table) has the following structure:
- job_name – The name of the RSQL script
- workflow_execution_id – The run ID for the workflow
- execution_start_ts – The start timestamp for the RSQL job
- execution_end_ts – The end timestamp for the RSQL job
- execution_status – The run status of the RSQL job (
Running, Completed, Failed) - instance_id – The EC2 instance ID on which the RSQL job is run
- ssm_command_id – The Systems Manager command ID used to trigger the RSQL job
- workflow_id – The
workflow_idunder which the RSQL job is run
The workflow audit table (rsql-blog-rsql-workflow-audit-table) has the following structure:
- workflow_execution_id – The run ID for the workflow
- workflow_id – The identifier for a particular workflow
- execution_start_ts – The start timestamp for the workflow
- execution_status – The run status of the workflow or state machine (
Running, Completed, Failed) - rsql_jobs – The list of RSQL scripts that are a part of the workflow
- execution_end_ts – The end timestamp for the workflow
Lambda functions
The AWS CDK creates the Lambda functions that retrieve the config data from the DynamoDB config table, update the audit details in DynamoDB, trigger the RSQL scripts on the EC2 instance, and iterate through each stage. The following is a list of the functions:
rsql-blog-master-iterator-lambdarsql-blog-parallel-load-check-lambdarsql-blog-sequential-iterator-lambdarsql-blog-rsql-invoke-lambdarsql-blog-update-audit-ddb-lambda
Step Functions state machines
This solution implements a Step Functions callback task integration pattern that enables Step Functions workflows to send a token to an external system via multiple AWS services.
The AWS CDK deploys the following state machines:
- RSQLParallelStateMachine – The parallel state machine is triggered if the execution_type for a stage in the configuration table is set to parallel. The Lambda function with a callback token is triggered in parallel for each of the RSQL scripts using a Map state.
- RSQLSequentialStateMachine – The sequential state machine is triggered if the execution_type for a stage in the configuration table is set to sequential. This state machine uses a iterator design pattern to run each RSQL job within the stage as per the sequence mentioned in the configuration.
- RSQLMasterStatemachine – The primary state machine iterates through each stage and triggers different state machines based on the run mode (sequential or parallel) using a Choice state.
Move the RSQL script and instance code
Copy the instance_code and rsql_scripts directories (present in the GitHub repo) to the EC2 instance. Make sure the framework directory within instance_code is copied as well.
The following screenshots show that the instance_code and rsql_scripts directories are copied to the same parent folder on the EC2 instance.




RSQL script run workflow
To further illustrate the mechanism to run the RSQL scripts, see the following diagram.

The Lambda function, which gets the configuration details from the configuration DynamoDB table, triggers the Step Functions workflow, which performs the following steps:
- A Lambda function defined as a workflow step receives the Step Functions
TaskTokenand configuration details. - The
TaskTokenand configuration details are passed onto the EC2 instance using the Systems MangerSendCommandAPI call. After the Lambda function is run, the workflow branch goes into paused state and waits for a callback token. - The RSQL scripts are run on the EC2 instance, which perform ETL and ELT on Amazon Redshift. After the scripts are run, the RSQL script passes the completion status and
TaskTokento a Python script. This Python script is embedded within the RSQL script. - The Python script updates the RSQL job status (success/failure) in the job audit DynamoDB table. It also exports the RSQL job logs to the CloudWatch log group.
- The Python script passes the RSQL job status (success/failure) and the status message back to the Step Functions workflow along with
TaskTokenusing theSendTaskSuccessorSendTaskFailureAPI call. - Depending on the job status received, Step Functions either resumes the workflow or stops the workflow.
If EC2 auto scaling groups are used, then you can use the Systems Manager SendCommand to ensure resilience and high availability by specifying one or more EC2 instances (that are a part of the auto scaling group). For more information, refer to Run commands at scale.
When multiple EC2 instances are used, set the max-concurrency parameter of the RunCommand API call to 1, which makes sure that the RSQL job is triggered on only one EC2 instance. For further details, refer to Using concurrency controls.
Run the orchestration framework
To run the orchestration framework, complete the following steps:
- On the DynamoDB console, navigate to the configuration table and insert the configuration details provided earlier. For instructions on how to insert the example JSON configuration details, refer to Write data to a table using the console or AWS CLI.

- On the Lambda console, open the rsql-blog-rsql-workflow-trigger-lambda function and choose Test.

- Add the test event similar to the following code and choose Test:

- On the Step Functions console, navigate to the
rsql-master-state-machinefunction to open the details page.
- Choose Edit, then choose Workflow Studio New. The following screenshot shows the primary state machine.

- Choose Cancel to leave Workflow Studio, then choose Cancel again to leave edit mode. You’re directed back to the details page.

- On the Executions tab, choose the latest run.

- From the Graph view, you can check the status of each state by choosing it. Every state that uses an external resource has a link to it on the Details tab.

- The orchestration framework runs the ETL load, which consists of the following sample RSQL scripts:
- rsql_blog_script_1.sh – This script creates a schema
rsql_blogwithin the database - rsql_blog_script_2.sh – This script creates a table
blog_tablewithin the schema created in the earlier script - rsql_blog_script_3.sh – Inserts one row into the table created in the previous script
- rsql_blog_script_4.sh – Inserts one row into the table created in the previous script
- rsql_blog_script_5.sh – Inserts one row into the table created in the previous script
- rsql_blog_script_6.sh – Inserts one row into the table created in the previous script
- rsql_blog_script_1.sh – This script creates a schema
You need to replace these RSQL scripts with the RSQL scripts developed for your workloads by inserting the relevant configuration details into the configuration DynamoDB table (rsql-blog-rsql-config-table).
Validation
After you run the framework, you’ll find a schema (called rsql_blog) with one table (called blog_table) created. This table consists of four rows.
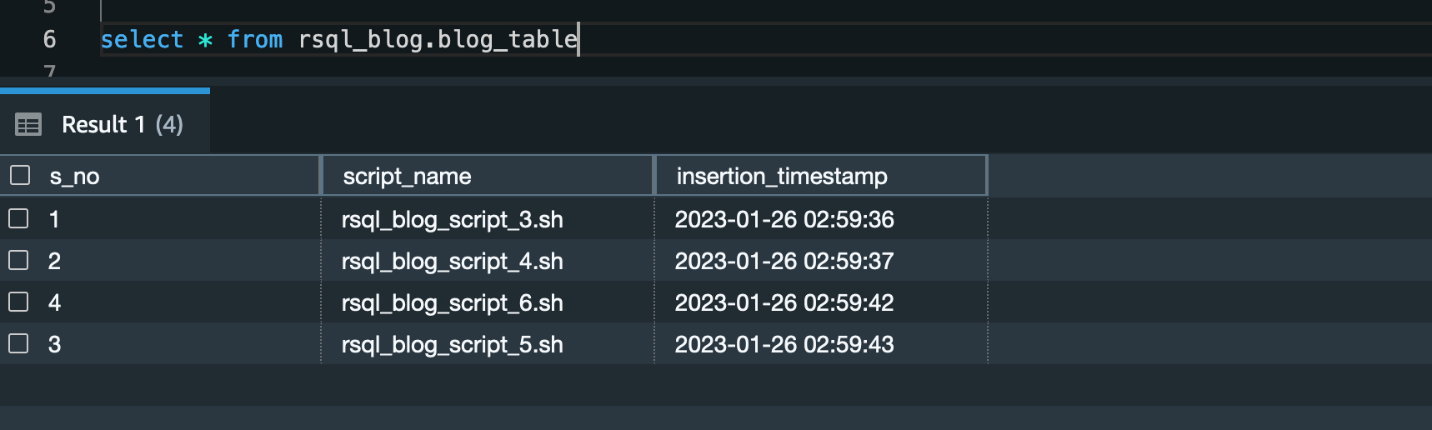
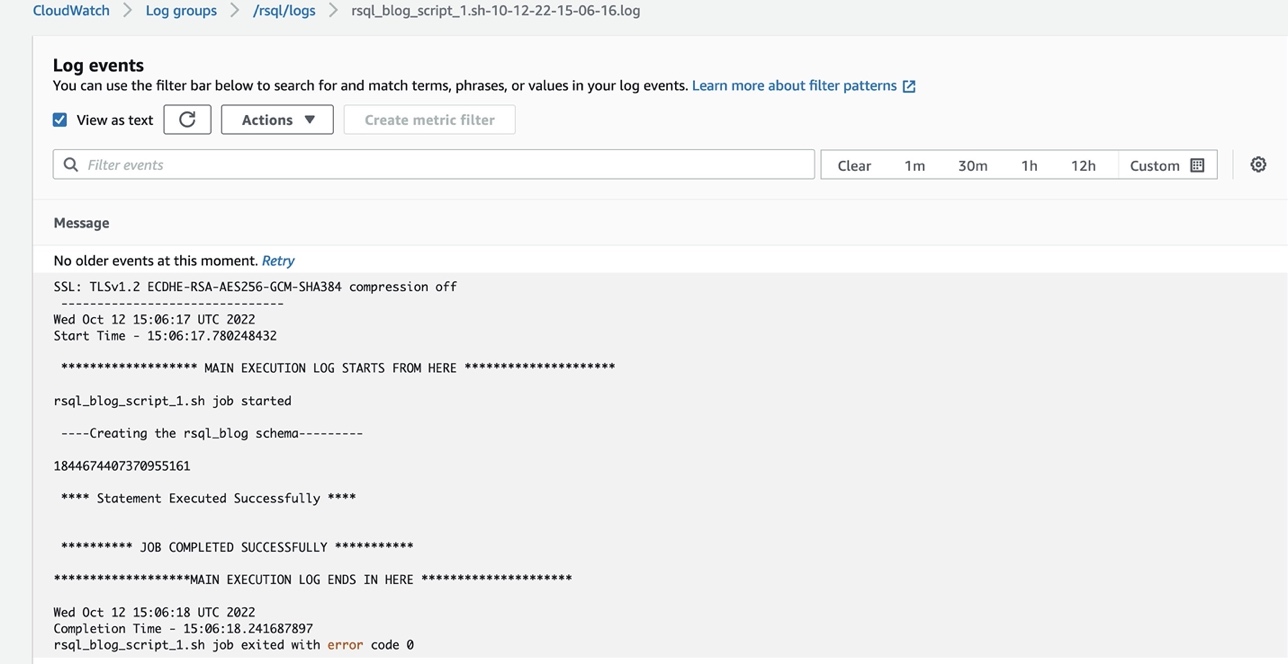
You can check the logs of the RSQL job in the CloudWatch log group (/ops/rsql-logs/) and also the run status of the workflow in the workflow audit DynamoDB table (rsql-blog-rsql-workflow-audit-table).

Clean up
To avoid ongoing charges for the resources that you created, delete them. AWS CDK deletes all resources except data resources such as DynamoDB tables.
- First, delete all AWS CDK stacks
- On the DynamoDB console, select the following tables and delete them:
rsql-blog-rsql-config-tablersql-blog-rsql-job-audit-tablersql-blog-rsql-workflow-audit-table
Conclusion
You can use Amazon Redshift RSQL, Systems Manager, EC2 instances, and Step Functions to create a modern and cost-effective orchestration framework for ETL workflows. There is no overhead to create and manage different state machines for each of your ETL workflow. In this post, we demonstrated how to use this configuration-based generic orchestration framework to trigger complex RSQL-based ETL workflows.
You can also trigger an email notification through Amazon Simple Notification Service (Amazon SNS) within the state machine to the notify the operations team of the completion status of the ETL process. Further, you can achieve a event-driven ETL orchestration framework by using EventBridge to start the workflow trigger lambda function.
About the Authors
 Akhil is a Data Analytics Consultant at AWS Professional Services. He helps customers design & build scalable data analytics solutions and migrate data pipelines and data warehouses to AWS. In his spare time, he loves travelling, playing games and watching movies.
Akhil is a Data Analytics Consultant at AWS Professional Services. He helps customers design & build scalable data analytics solutions and migrate data pipelines and data warehouses to AWS. In his spare time, he loves travelling, playing games and watching movies.

Ramesh Raghupathy is a Senior Data Architect with WWCO ProServe at AWS. He works with AWS customers to architect, deploy, and migrate to data warehouses and data lakes on the AWS Cloud. While not at work, Ramesh enjoys traveling, spending time with family, and yoga.
 Raza Hafeez is a Senior Data Architect within the Shared Delivery Practice of AWS Professional Services. He has over 12 years of professional experience building and optimizing enterprise data warehouses and is passionate about enabling customers to realize the power of their data. He specializes in migrating enterprise data warehouses to AWS Modern Data Architecture.
Raza Hafeez is a Senior Data Architect within the Shared Delivery Practice of AWS Professional Services. He has over 12 years of professional experience building and optimizing enterprise data warehouses and is passionate about enabling customers to realize the power of their data. He specializes in migrating enterprise data warehouses to AWS Modern Data Architecture.
 Dipal Mahajan is a Lead Consultant with Amazon Web Services based out of India, where he guides global customers to build highly secure, scalable, reliable, and cost-efficient applications on the cloud. He brings extensive experience on Software Development, Architecture and Analytics from industries like finance, telecom, retail and healthcare.
Dipal Mahajan is a Lead Consultant with Amazon Web Services based out of India, where he guides global customers to build highly secure, scalable, reliable, and cost-efficient applications on the cloud. He brings extensive experience on Software Development, Architecture and Analytics from industries like finance, telecom, retail and healthcare.