AWS Big Data Blog
Tag: Big Data

Export JMX metrics from Kafka connectors in Amazon Managed Streaming for Apache Kafka Connect with a custom plugin
In this post, we demonstrate how you can export the JMX metrics for Debezium connector when used with Amazon MSK Connect.

Express brokers for Amazon MSK: Turbo-charged Kafka scaling with up to 20 times faster performance
In this post, we walk you through the implementation of MSK Express brokers, highlighting their core features, benefits, and best practices for rapid Kafka scaling.

Modernize your legacy databases with AWS data lakes, Part 2: Build a data lake using AWS DMS data on Apache Iceberg
This is part two of a three-part series where we show how to build a data lake on AWS using a modern data architecture. This post shows how to load data from a legacy database (SQL Server) into a transactional data lake (Apache Iceberg) using AWS Glue. We show how to build data pipelines using AWS Glue jobs, optimize them for both cost and performance, and implement schema evolution to automate manual tasks. To review the first part of the series, where we load SQL Server data into Amazon Simple Storage Service (Amazon S3) using AWS Database Migration Service (AWS DMS), see Modernize your legacy databases with AWS data lakes, Part 1: Migrate SQL Server using AWS DMS.

How Getir unleashed data democratization using a data mesh architecture with Amazon Redshift
In this post, we explain how ultrafast delivery pioneer, Getir, unleashed the power of data democratization on a large scale through their data mesh architecture using Amazon Redshift. We start by introducing Getir and their vision—to seamlessly, securely, and efficiently share business data across different teams within the organization for BI, extract, transform, and load (ETL), and other use cases. We’ll then explore how Amazon Redshift data sharing powered the data mesh architecture that allowed Getir to achieve this transformative vision.
Building a scalable streaming data platform that enables real-time and batch analytics of electric vehicles on AWS
The automobile industry has undergone a remarkable transformation because of the increasing adoption of electric vehicles (EVs). EVs, known for their sustainability and eco-friendliness, are paving the way for a new era in transportation. As environmental concerns and the push for greener technologies have gained momentum, the adoption of EVs has surged, promising to reshape […]

Detect and handle data skew on AWS Glue
October 2024: This post was reviewed and updated for accuracy. AWS Glue is a fully managed, serverless data integration service provided by Amazon Web Services (AWS) that uses Apache Spark as one of its backend processing engines (as of this writing, you can use Python Shell or Spark). Data skew occurs when the data being […]

How the GoDaddy data platform achieved over 60% cost reduction and 50% performance boost by adopting Amazon EMR Serverless
This is a guest post co-written with Brandon Abear, Dinesh Sharma, John Bush, and Ozcan IIikhan from GoDaddy. GoDaddy empowers everyday entrepreneurs by providing all the help and tools to succeed online. With more than 20 million customers worldwide, GoDaddy is the place people come to name their ideas, build a professional website, attract customers, […]

Interactively develop your AWS Glue streaming ETL jobs using AWS Glue Studio notebooks
Enterprise customers are modernizing their data warehouses and data lakes to provide real-time insights, because having the right insights at the right time is crucial for good business outcomes. To enable near-real-time decision-making, data pipelines need to process real-time or near-real-time data. This data is sourced from IoT devices, change data capture (CDC) services like […]
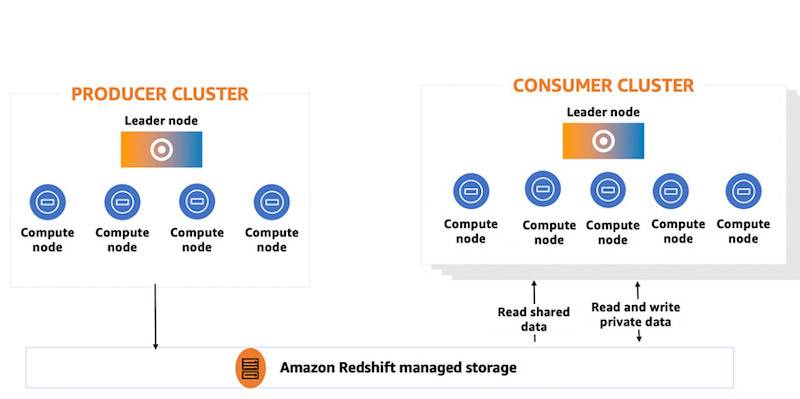
From centralized architecture to decentralized architecture: How data sharing fine-tunes Amazon Redshift workloads
Amazon Redshift is a fast, petabyte-scale cloud data warehouse delivering the best price-performance. It makes it fast, simple, and cost-effective to analyze all your data using standard SQL and your existing business intelligence (BI) tools. Today, tens of thousands of customers run business-critical workloads on Amazon Redshift. With the significant growth of data for big […]

Running a high-performance SAS Grid Manager cluster on AWS with Amazon FSx for Lustre
SAS® is a software provider of data science and analytics used by enterprises and government organizations. SAS Grid is a highly available, fast processing analytics platform that offers centralized management that balances workloads across different compute nodes. This application suite is capable of data management, visual analytics, governance and security, forecasting and text mining, statistical […]