AWS Big Data Blog
Tag: Data Lake
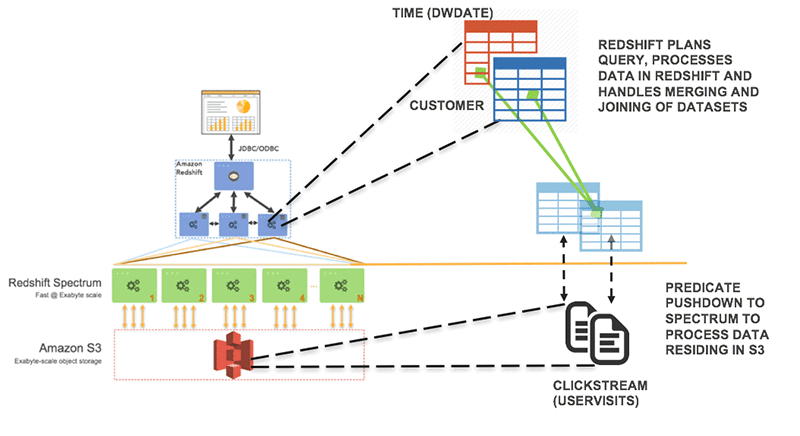
From Data Lake to Data Warehouse: Enhancing Customer 360 with Amazon Redshift Spectrum
Achieving a 360o-view of your customer has become increasingly challenging as companies embrace omni-channel strategies, engaging customers across websites, mobile, call centers, social media, physical sites, and beyond. The promise of a web where online and physical worlds blend makes understanding your customers more challenging, but also more important. Businesses that are successful in this […]

Building a Real World Evidence Platform on AWS
Deriving insights from large datasets is central to nearly every industry, and life sciences is no exception. To combat the rising cost of bringing drugs to market, pharmaceutical companies are looking for ways to optimize their drug development processes. They are turning to big data analytics to better quantify the effect that their drug compounds […]

New AWS Training: Building a Serverless Data Lake
AWS Training allows you to learn from the experts so that you can advance your knowledge with practical skills and get more out of the AWS Cloud. We are adding one of our most popular event boot camps, Building a Serverless Data Lake, to our permanent instructor-led training portfolio. This one-day course is designed to […]

Amazon Redshift Spectrum Extends Data Warehousing Out to Exabytes—No Loading Required
When we first looked into the possibility of building a cloud-based data warehouse many years ago, we were struck by the fact that our customers were storing ever-increasing amounts of data, and yet only a small fraction of that data ever made it into a data warehouse or Hadoop system for analysis. We saw that […]
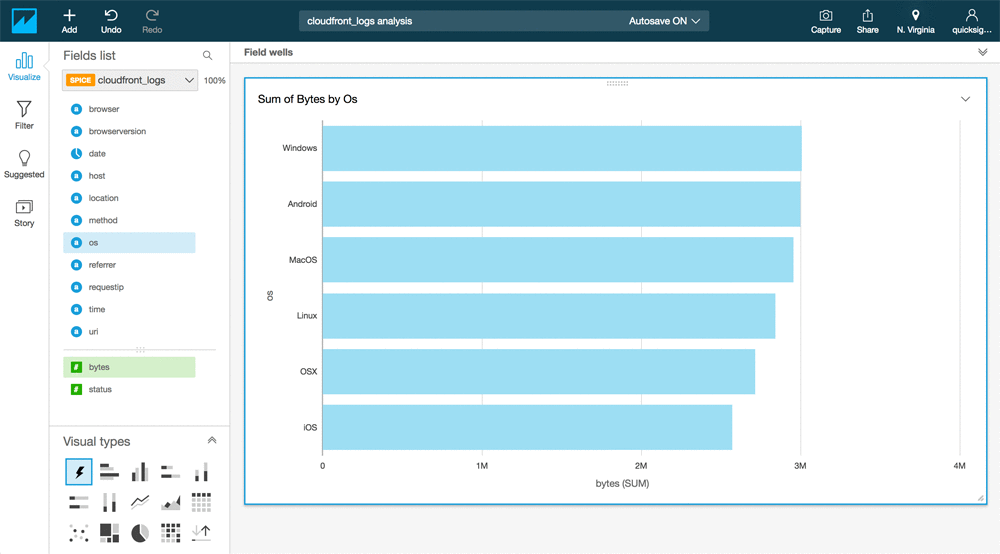
Visualize Big Data with Amazon QuickSight, Presto, and Apache Spark on Amazon EMR
February 9, 2024: Amazon Kinesis Data Firehose has been renamed to Amazon Data Firehose. Read the AWS What’s New post to learn more. Last December, we introduced the Amazon Athena connector in Amazon QuickSight, in the Derive Insights from IoT in Minutes using AWS IoT, Amazon Kinesis Firehose, Amazon Athena, and Amazon QuickSight post. The […]

Top 10 Performance Tuning Tips for Amazon Athena
February 2024: This post was reviewed and updated to reflect changes in Amazon Athena engine version 3, including cost-based optimization and query result reuse. Amazon Athena is an interactive analytics service built on open source frameworks that make it straightforward to analyze data stored using open table and file formats in Amazon Simple Storage Service […]

Derive Insights from IoT in Minutes using AWS IoT, Amazon Kinesis Firehose, Amazon Athena, and Amazon QuickSight
February 9, 2024: Amazon Kinesis Data Firehose has been renamed to Amazon Data Firehose. Read the AWS What’s New post to learn more. Ben Snively is a Solutions Architect with AWS Speed and agility are essential with today’s analytics tools. The quicker you can get from idea to first results, the more you can experiment […]

Introducing the Data Lake Solution on AWS
NOTE: The solution in this post is in the process of being updated. For the most current information, please visit the What is a data lake? page. This blog post has been translated into Japanese. Many of our customers choose to build their data lake on AWS. They find the flexible, pay-as-you-go, cloud model is […]

Optimize Amazon S3 for High Concurrency in Distributed Workloads
In today’s blog post, I will discuss how to optimize Amazon S3 for an architecture commonly used to enable genomic data analyses. This optimization is important to my work in genomics because, as genome sequencing continues to drop in price, the rate at which data becomes available is accelerating.

Using Spark SQL for ETL
Ben Snively is a Solutions Architect with AWS With big data, you deal with many different formats and large volumes of data. SQL-style queries have been around for nearly four decades. Many systems support SQL-style syntax on top of the data layers, and the Hadoop/Spark ecosystem is no exception. This allows companies to try new […]