AWS Machine Learning Blog
Category: Best Practices

Reinventing a cloud-native federated learning architecture on AWS
In this blog, you will learn to build a cloud-native FL architecture on AWS. By using infrastructure as code (IaC) tools on AWS, you can deploy FL architectures with ease. Also, a cloud-native architecture takes full advantage of a variety of AWS services with proven security and operational excellence, thereby simplifying the development of FL.

Prepare your data for Amazon Personalize with Amazon SageMaker Data Wrangler
A recommendation engine is only as good as the data used to prepare it. Transforming raw data into a format that is suitable for a model is key to getting better personalized recommendations for end-users. In this post, we walk through how to prepare and import the MovieLens dataset, a dataset prepared by GroupLens research […]
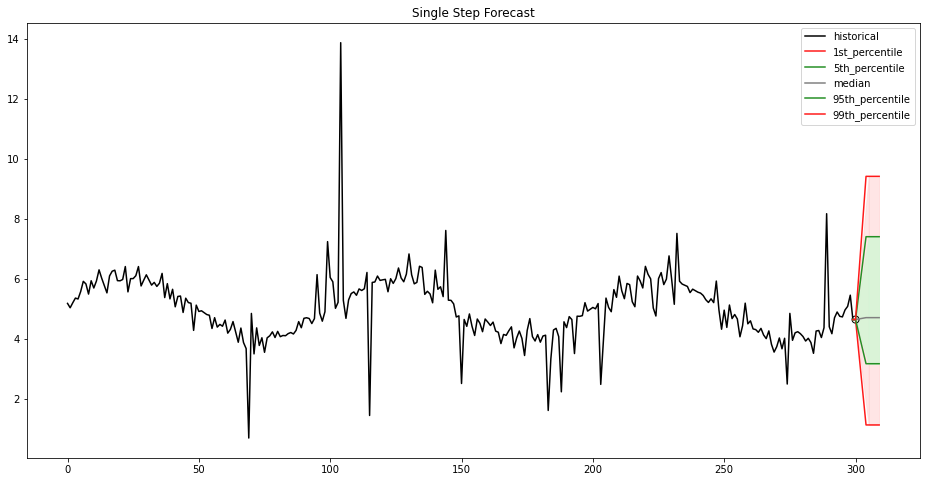
Robust time series forecasting with MLOps on Amazon SageMaker
In the world of data-driven decision-making, time series forecasting is key in enabling businesses to use historical data patterns to anticipate future outcomes. Whether you are working in asset risk management, trading, weather prediction, energy demand forecasting, vital sign monitoring, or traffic analysis, the ability to forecast accurately is crucial for success. In these applications, […]

Create a Generative AI Gateway to allow secure and compliant consumption of foundation models
In the rapidly evolving world of AI and machine learning (ML), foundation models (FMs) have shown tremendous potential for driving innovation and unlocking new use cases. However, as organizations increasingly harness the power of FMs, concerns surrounding data privacy, security, added cost, and compliance have become paramount. Regulated and compliance-oriented industries, such as financial services, […]

A generative AI-powered solution on Amazon SageMaker to help Amazon EU Design and Construction
The Amazon EU Design and Construction (Amazon D&C) team is the engineering team designing and constructing Amazon Warehouses across Europe and the MENA region. The design and deployment processes of projects involve many types of Requests for Information (RFIs) about engineering requirements regarding Amazon and project-specific guidelines. These requests range from simple retrieval of baseline […]

Improving your LLMs with RLHF on Amazon SageMaker
In this blog post, we illustrate how RLHF can be performed on Amazon SageMaker by conducting an experiment with the popular, open-sourced RLHF repo Trlx. Through our experiment, we demonstrate how RLHF can be used to increase the helpfulness or harmlessness of a large language model using the publicly available Helpfulness and Harmlessness (HH) dataset provided by Anthropic. Using this dataset, we conduct our experiment with Amazon SageMaker Studio notebook that is running on an ml.p4d.24xlarge instance. Finally, we provide a Jupyter notebook to replicate our experiments.

Optimize generative AI workloads for environmental sustainability
To add to our guidance for optimizing deep learning workloads for sustainability on AWS, this post provides recommendations that are specific to generative AI workloads. In particular, we provide practical best practices for different customization scenarios, including training models from scratch, fine-tuning with additional data using full or parameter-efficient techniques, Retrieval Augmented Generation (RAG), and prompt engineering.

Orchestrate Ray-based machine learning workflows using Amazon SageMaker
Machine learning (ML) is becoming increasingly complex as customers try to solve more and more challenging problems. This complexity often leads to the need for distributed ML, where multiple machines are used to train a single model. Although this enables parallelization of tasks across multiple nodes, leading to accelerated training times, enhanced scalability, and improved […]

Semantic image search for articles using Amazon Rekognition, Amazon SageMaker foundation models, and Amazon OpenSearch Service
Digital publishers are continuously looking for ways to streamline and automate their media workflows in order to generate and publish new content as rapidly as they can. Publishers can have repositories containing millions of images and in order to save money, they need to be able to reuse these images across articles. Finding the image that best matches an article in repositories of this scale can be a time-consuming, repetitive, manual task that can be automated. It also relies on the images in the repository being tagged correctly, which can also be automated (for a customer success story, refer to Aller Media Finds Success with KeyCore and AWS). In this post, we demonstrate how to use Amazon Rekognition, Amazon SageMaker JumpStart, and Amazon OpenSearch Service to solve this business problem.

Best practices and design patterns for building machine learning workflows with Amazon SageMaker Pipelines
In this post, we provide some best practices to maximize the value of SageMaker Pipelines and make the development experience seamless. We also discuss some common design scenarios and patterns when building SageMaker Pipelines and provide examples for addressing them.