Artificial Intelligence
Football tracking in the NFL with Amazon SageMaker
With the 2020 football season kicking off, Amazon Web Services (AWS) is continuing its work with the National Football League (NFL) on several ongoing game-changing initiatives. Specifically, the NFL and AWS are teaming up to develop state-of-the-art cloud technology using machine learning (ML) aimed at aiding the officiating process through real-time football detection. As a first step in this process, the Amazon Machine Learning Solutions Lab developed a computer vision model for the challenge of football detection. In this post, we provide in-depth examples including code snippets and visualizations to demonstrate the key components of the football detection pipeline, starting with data labeling and following up with training and deployment using Amazon SageMaker and Apache MXNet Gluon.
Detecting the football in NFL Broadcast videos
The following video illustrates detecting the football frame by frame.

Computer vision-based object detection techniques use deep learning algorithms to predict the location of objects in images and videos. Today, object detection has many far-reaching, high business value use cases, such as in self-driving car technology, where detecting pedestrians and vehicles is of paramount importance in ensuring safety on the roads. For the NFL, object detection technology like this is crucial as the game continues to evolve at a rapid pace. For example, they can use real-time object identification to generate new advanced analytics around player and team performance, in addition to aiding game officials in ball spotting. This technology is part of the larger suite of innovations in the AWS/NFL partnership.
The following sections of the post outline how we used NFL broadcast video data to train object detection models that analyze thousands of images to locate and classify the football from background objects.
Creating an object detection dataset with Amazon SageMaker Ground Truth
Amazon SageMaker Ground Truth is a fully managed data labeling service that makes it easy to build highly accurate training datasets for ML. With the help of Ground Truth, we created a custom object detection dataset by breaking the NFL play segments into images. It offers a user interface (UI) that allowed us to quickly spin up a bounding box labeling job, in which human annotators can quickly draw bounding box labels around thousands of football image sequences stored in an Amazon Simple Storage Service (Amazon S3) bucket. The following screenshot illustrates the object detection UI.
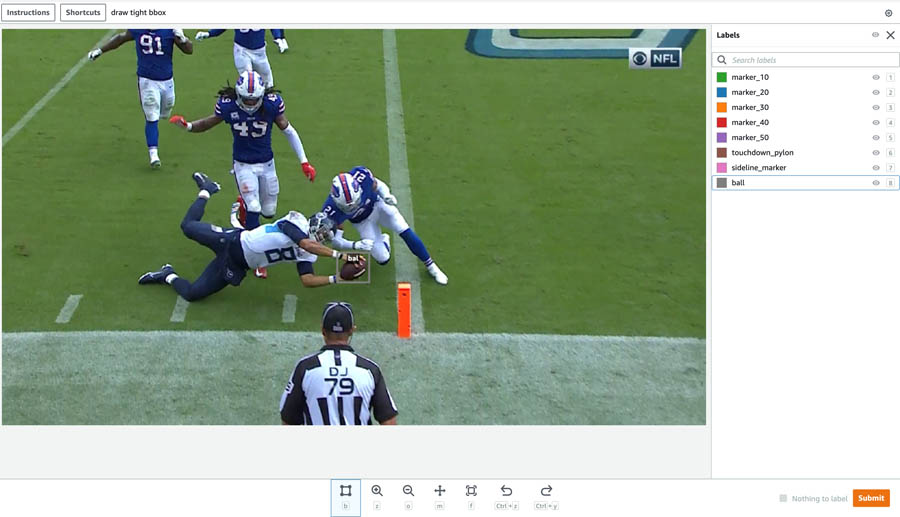
The labeling job outputs a manifest file that contains the S3 file path of the image, the (x, y) bounding box coordinates, and the class label (for this use case, football) needed for the model training process.
The following screenshot shows the manifest file that is automatically updated in the S3 path.

The following screenshot shows the contents of the output.manifest file.

Supercharging training with Apache MXNet Gluon and Amazon SageMaker Script Mode
Our approach to model development relied on an ML technique called transfer learning. In it, we take neural networks previously trained on similar applications with strong results and fine-tune these models on our annotated data. We converted the annotations from the labeling job to RecordIO format for compact storage and faster disk access. Neural networks have the tendency to overfit training data, leading to poor out-of-sample results. The MXNet Gluon toolkit we added provides image normalization and image augmentations, such as randomized image flipping and cropping, to help reduce overfitting during training.
Amazon SageMaker provides a simple UI to train object detection models with no code, offering the Single Shot Detector (SSD) pre-trained model with several out-of-the-box configurations. For a more customized architecture, we use Amazon SageMaker Script Mode, which allows you to bring your own training algorithms and directly train models while staying within the user-friendly confines of Amazon SageMaker. We could train larger, more accurate models directly from Amazon SageMaker notebooks by combining Script Mode with pre-trained models like Yolov3 and Faster-RCNN with several backbone network combinations from the Gluon Model Zoo for object detection. See the following code:
Object detection algorithm: Background
Object detectors typically combine two key components: detection of objects in images and regression for estimating bounding box coordinates of objects. During training, object detectors are optimized to reduce both detection error and localization error (bounding box prediction error) via a loss function.
Current state-of-the-art object detectors contain deep learning architectures that use pre-trained convolutional neural networks (CNNs) like VGG-16 or ResNet-50 as base networks to perform rich feature extraction from input images. SSD predicts the relative offsets to a fixed set of boxes at every location of a convolutional feature map. Empirically, SSD underperforms other object detector algorithms on small objects like football. In contrast, YOLOv3 uses DarkNet-53 for feature extraction, which concatenates multiple feature maps together to make predictions, leading to improved performance on smaller objects.
Faster-RCNN in comparison to both SSD and YOLOv3 uses an additional shared deep neural network to predict region proposals of the input image feature maps, which is aggregated in the feed downstream in the model for object classification and bounding box prediction. Faster-RCNN empirically outperformed other networks on small objects in our use case. One major consideration in addition to performance, when choosing object detectors, is model inference time. SSD and YOLOv3 tend to have fast inference times as measured in frames per second, which is a key consideration for real-time applications; larger networks like Faster-RCNN have slower inference time.
Hyperparameter optimization on Amazon SageMaker
A standard metric for evaluating object detectors is mean average precision (mAP). mAP is based on the model precision recall (PR) curve and provides a numerical metric that can be directly used across models. You can generate PR curves by setting model confidence score thresholds to different levels, resulting in precision and recall pairs. Plotting these pairs with a bit of interpolation results in a PR curve. Average precision (AP) is then defined as the area under this PR curve. Similarly, you may want to detect multiple objects in an image, such as K > 1 objects: mAP is the mean AP across all K classes.
Automatic model tuning in Amazon SageMaker, also known as hyperparameter optimization, allowed us to try over 100 models with unique parameter configurations to achieve the best model possible given our data. Hyperparameter optimization uses strategies like random search and Bayesian search to help tune hyper parameters in the ML algorithm. See the following sample code:
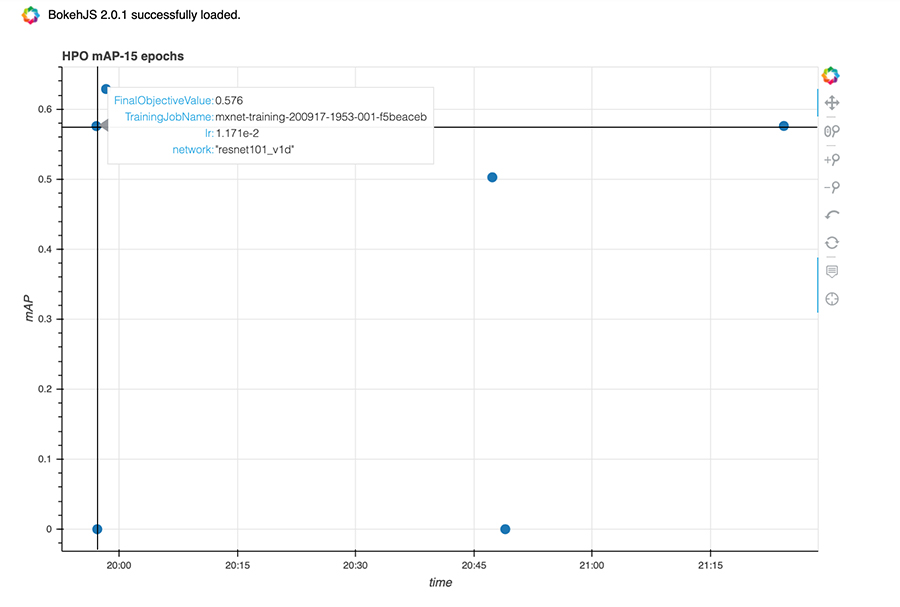
To do this, we specified the location of our data and manifest file on Amazon S3 and chose our Amazon SageMaker instance type and object detection algorithm to use (SSD with ResNet50). Amazon SageMaker hyperparameter optimization then launched several configurations of the base model with unique hyperparameter configurations, using Bayesian search to determine which configuration achieves the best model based on a preset test metric. In our case, we optimized towards the highest mean average precision (mAP) on our held-out test data. The following graph shows a visualization of a sample set of hyperparameter optimization jobs from the hyperparameter optimization tuner object.
Deploying the model
Deploying the model required only a few additional lines of code (hosting methods) within our Amazon SageMaker notebook instance. We can simply call tuner.deploy on our hyperparameter optimization tuner to deploy the best model based on the evaluation metric that was set for the hyperparameter optimization training job. The code below demonstrates a proof-of-concept deployment on Amazon SageMaker:
The model weights for each training job are stored in Amazon S3. We can deploy any of the jobs or Amazon SageMaker trained models by passing its model artifact path to an Amazon SageMaker estimator object. To do this, we referred to the preconfigured container optimized to perform inference and linked it to the model weights. After this model-container pair was created on our account, we could configure an endpoint with the instance type and number of instances needed by the NFL. See the following code:
Model inference for football detection
At runtime, a client sends a request to the endpoint hosting the model container on an Amazon Elastic Compute Cloud (Amazon EC2) instance and returns the output (inference). In production, scaling endpoints for large-scale inference on the NFL broadcast videos is significantly simplified with this pipeline.
Sensitivity and error analysis
When exploring strategies to improve model performance, you can scale up (use larger architectures) or scale out (acquire more data). After scaling up, which we discussed earlier during model exploration, data scientists commonly collect additional data in hopes of improving model generalizability. For our use case, we specifically aimed at reducing localization error. To do this, we created several test sets that quantitatively and qualitatively helped us understand mAP in relation to specific characteristics of the input video: occlusion (high vs. low) of the football, bounding box size (small vs. large) and aspect ratio (tall vs. wide) effects, camera angle (endzone vs. sideline), and contrast (high vs. low) between the football and its background area. From this, we understood which qualitative aspect of image the model was struggling to predict, and these findings led us to strategically gather additional data to target and improve upon these areas.
Summary
The NFL uses cloud computing to create innovative experiences that introduce additional ways for fans to enjoy football while making the game more efficient and fast-paced. By combining football detection with additional new technologies, the NFL can reduce game stoppage, support officiating, and bring real-time insight into what’s happening on the field, leading to a greater connection with the game that fans love. While fans take delight in “America’s game,” they can rest assured that the NFL in collaboration with AWS is utilizing the newest and best technologies to make the game more enjoyable with a broader range of data points.
You can find full, end-to-end examples of creating custom training jobs, training state-of-the-art object detection models, implementing HPO, and model deployment on Amazon SageMaker on the AWS Labs GitHub repo. To learn more about the ML Solutions Lab, see Amazon Machine Learning Solutions Lab.
About the Authors
 Michael Lopez is the Director of Football Data and Analytics at the National Football League and a Lecturer of Statistics and Research Associate at Skidmore College. At the National Football League, his work centers on how to use data to enhance and better understand the game of football.
Michael Lopez is the Director of Football Data and Analytics at the National Football League and a Lecturer of Statistics and Research Associate at Skidmore College. At the National Football League, his work centers on how to use data to enhance and better understand the game of football.
 Colby Wise is a Senior Data Scientist and manager at the Amazon Machine Learning Solutions Lab where he works with customers across different verticals to accelerate their use of machine learning and AWS cloud services to solve their business challenges.
Colby Wise is a Senior Data Scientist and manager at the Amazon Machine Learning Solutions Lab where he works with customers across different verticals to accelerate their use of machine learning and AWS cloud services to solve their business challenges.
 Divya Bhargavi is a Data Scientist at the Amazon Machine Learning Solutions Lab where she develops machine learning models to address customers’ business problems. Most recently, she worked on Computer Vision solutions involving both classical and deep learning methods for a sports customer.
Divya Bhargavi is a Data Scientist at the Amazon Machine Learning Solutions Lab where she develops machine learning models to address customers’ business problems. Most recently, she worked on Computer Vision solutions involving both classical and deep learning methods for a sports customer.