Artificial Intelligence
Use computer vision to measure agriculture yield with Amazon Rekognition Custom Labels
In the agriculture sector, the problem of identifying and counting the amount of fruit on trees plays an important role in crop estimation. The concept of renting and leasing a tree is becoming popular, where a tree owner leases the tree every year before the harvest based on the estimated fruit yeild. The common practice of manually counting fruit is a time-consuming and labor-intensive process. It’s one of the hardest but most important tasks in order to obtain better results in your crop management system. This estimation of the amount of fruit and flowers helps farmers make better decisions—not only on only leasing prices, but also on cultivation practices and plant disease prevention.
This is where an automated machine learning (ML) solution for computer vision (CV) can help farmers. Amazon Rekognition Custom Labels is a fully managed computer vision service that allows developers to build custom models to classify and identify objects in images that are specific and unique to your business.
Rekognition Custom Labels doesn’t require you to have any prior computer vision expertise. You can get started by simply uploading tens of images instead of thousands. If the images are already labeled, you can begin training a model in just a few clicks. If not, you can label them directly within the Rekognition Custom Labels console, or use Amazon SageMaker Ground Truth to label them. Rekognition Custom Labels uses transfer learning to automatically inspect the training data, select the right model framework and algorithm, optimize the hyperparameters, and train the model. When you’re satisfied with the model accuracy, you can start hosting the trained model with just one click.
In this post, we showcase how you can build an end-to-end solution using Rekognition Custom Labels to detect and count fruit to measure agriculture yield.
Solution overview
We create a custom model to detect fruit using the following steps:
- Label a dataset with images containing fruit using Amazon SageMaker Ground Truth.
- Create a project in Rekognition Custom Labels.
- Import your labeled dataset.
- Train the model.
- Test the new custom model using the automatically generated API endpoint.
Rekognition Custom Labels lets you manage the ML model training process on the Amazon Rekognition console, which simplifies the end-to-end model development and inference process.
Prerequisites
To create an agriculture yield measuring model, you first need to prepare a dataset to train the model with. For this post, our dataset is composed of images of fruit. The following images show some examples.

We sourced our images from our own garden. You can download the image files from the GitHub repo.
For this post, we only use a handful of images to showcase the fruit yield use case. You can experiment further with more images.
To prepare your dataset, complete the following steps:
- Create an Amazon Simple Storage Service (Amazon S3) bucket.
- Create two folders inside this bucket, called
raw_dataandtest_data, to store images for labeling and model testing. - Choose Upload to upload the images to their respective folders from the GitHub repo.

The uploaded images aren’t labeled. You label the images in the following step.
Label your dataset using Ground Truth
To train the ML model, you need labeled images. Ground Truth provides an easy process to label the images. The labeling task is performed by a human workforce; in this post, you create a private workforce. You can use Amazon Mechanical Turk for labeling at scale.
Create a labeling workforce
Let’s first create our labeling workforce. Complete the following steps:
- On the SageMaker console, under Ground Truth in the navigation pane, choose Labeling workforces.
- On the Private tab, choose Create private team.

- For Team name, enter a name for your workforce (for this post,
labeling-team). - Choose Create private team.

- Choose Invite new workers.

- In the Add workers by email address section, enter the email addresses of your workers. For this post, enter your own email address.
- Choose Invite new workers.

You have created a labeling workforce, which you use in the next step while creating a labeling job.
Create a Ground Truth labeling job
To great your labeling job, complete the following steps:
- On the SageMaker console, under Ground Truth, choose Labeling jobs.
- Choose Create labeling job.

- For Job name, enter
fruits-detection. - Select I want to specify a label attribute name different from the labeling job name.
- For Label attribute name¸ enter
Labels. - For Input data setup, select Automated data setup.
- For S3 location for input datasets, enter the S3 location of the images, using the bucket you created earlier (
s3://{your-bucket-name}/raw-data/images/). - For S3 location for output datasets, select Specify a new location and enter the output location for annotated data (
s3://{your-bucket-name}/annotated-data/). - For Data type, choose Image.
- Choose Complete data setup.
This creates the image manifest file and updates the S3 input location path. Wait for the message “Input data connection successful.”

- Expand Additional configuration.
- Confirm that Full dataset is selected.
This is used to specify whether you want to provide all the images to the labeling job or a subset of images based on filters or random sampling.

- For Task category, choose Image because this is a task for image annotation.
- Because this is an object detection use case, for Task selection, select Bounding box.
- Leave the other options as default and choose Next.

- Choose Next.

Now you specify your workers and configure the labeling tool. - For Worker types, select Private.For this post, you use an internal workforce to annotate the images. You also have the option to select a public contractual workforce (Amazon Mechanical Turk) or a partner workforce (Vendor managed) depending on your use case.
- For Private teams¸ choose the team you created earlier.

- Leave the other options as default and scroll down to Bounding box labeling tool.It’s essential to provide clear instructions here in the labeling tool for the private labeling team. These instructions acts as a guide for annotators while labeling. Good instructions are concise, so we recommend limiting the verbal or textual instructions to two sentences and focusing on visual instructions. In the case of image classification, we recommend providing one labeled image in each of the classes as part of the instructions.
- Add two labels:
fruitandno_fruit. - Enter detailed instructions in the Description field to provide instructions to the workers. For example:
You need to label fruits in the provided image. Please ensure that you select label 'fruit' and draw the box around the fruit just to fit the fruit for better quality of label data. You also need to label other areas which look similar to fruit but are not fruit with label 'no_fruit'.You can also optionally provide examples of good and bad labeling images. You need to make sure that these images are publicly accessible. - Choose Create to create the labeling job.

After the job is successfully created, the next step is to label the input images.
Start the labeling job
Once you have successfully created the job, the status of the job is InProgress. This means that the job is created and the private workforce is notified via email regarding the task assigned to them. Because you have assigned the task to yourself, you should receive an email with instructions to log in to the Ground Truth Labeling project.

- Open the email and choose the link provided.
- Enter the user name and password provided in the email.
You may have to change the temporary password provided in the email to a new password after login. - After you log in, select your job and choose Start working.

You can use the provided tools to zoom in, zoom out, move, and draw bounding boxes in the images. - Choose your label (
fruitorno_fruit) and then draw a bounding box in the image to annotate it. - When you’re finished, choose Submit.
Now you have correctly labeled images that will be used by the ML model for training.
Create your Amazon Rekognition project
To create your agriculture yield measuring project, complete the following steps:
- On the Amazon Rekognition console, choose Custom Labels.
- Choose Get Started.
- For Project name, enter
fruits_yield. - Choose Create project.
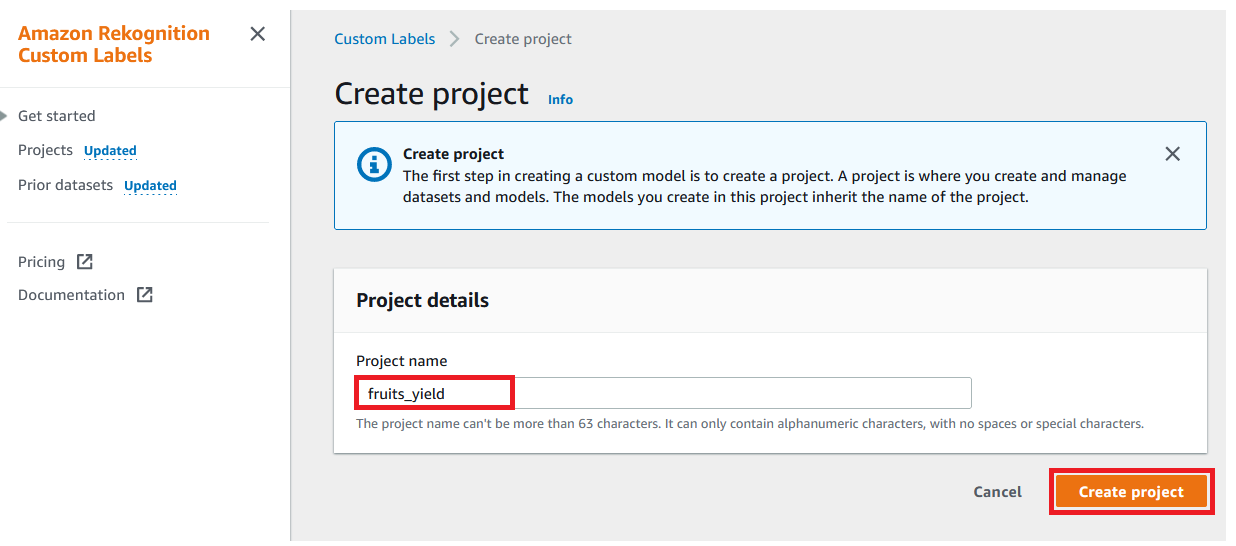
You can also create a project on the Projects page. You can access the Projects page via the navigation pane. The next step is to provide images as input.
Import your dataset
To create your agriculture yield measuring model, you first need to import a dataset to train the model with. For this post, our dataset is already labeled using Ground Truth.
- For Import images, select Import images labeled by SageMaker Ground Truth.
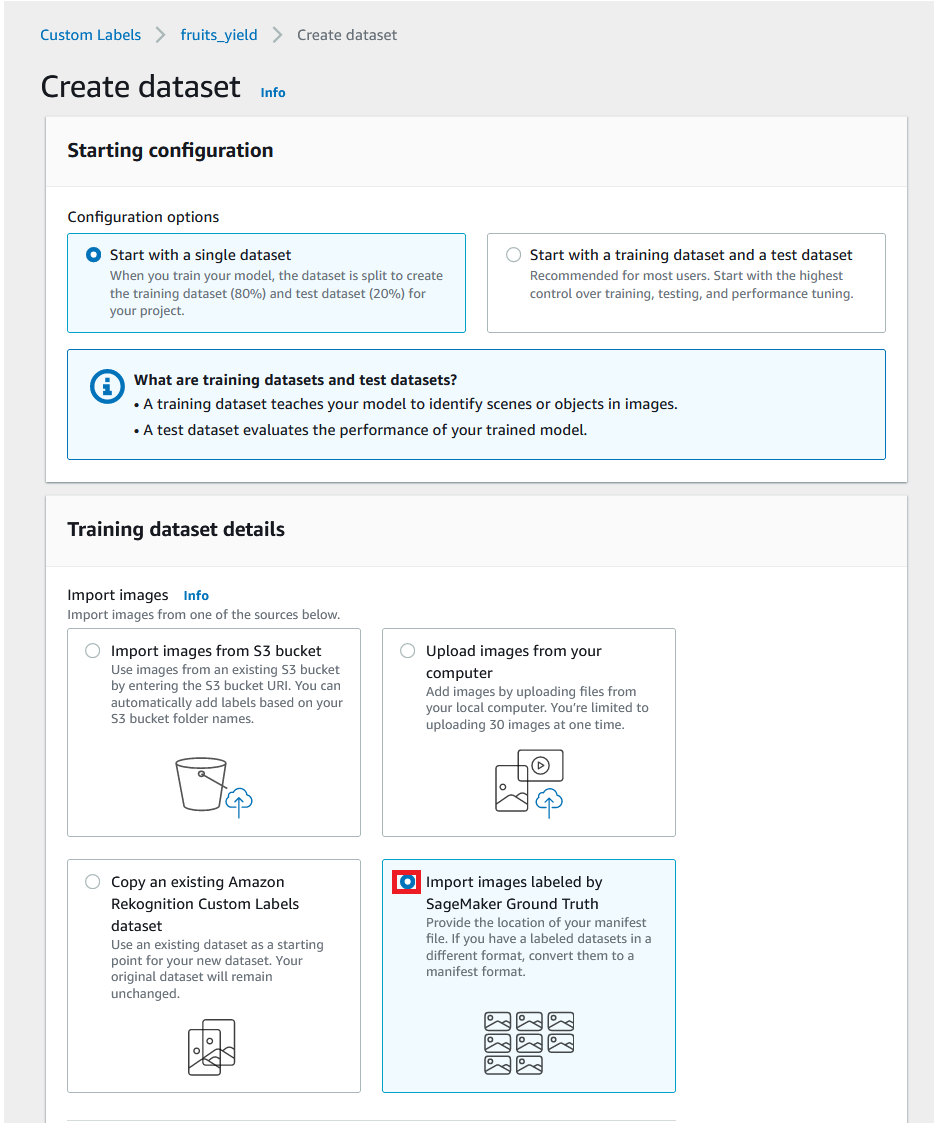
- For Manifest file location, enter the S3 bucket location of your manifest file (
s3://{your-bucket-name}/fruits_image/annotated_data/fruits-labels/manifests/output/output.manifest). - Choose Create Dataset.

You can see your labeled dataset.

Now you have your input dataset for the ML model to start training on them.
Train your model
After you label your images, you’re ready to train your model.
- Choose Train model.
- For Choose project, choose your project
fruits_yield. - Choose Train Model.
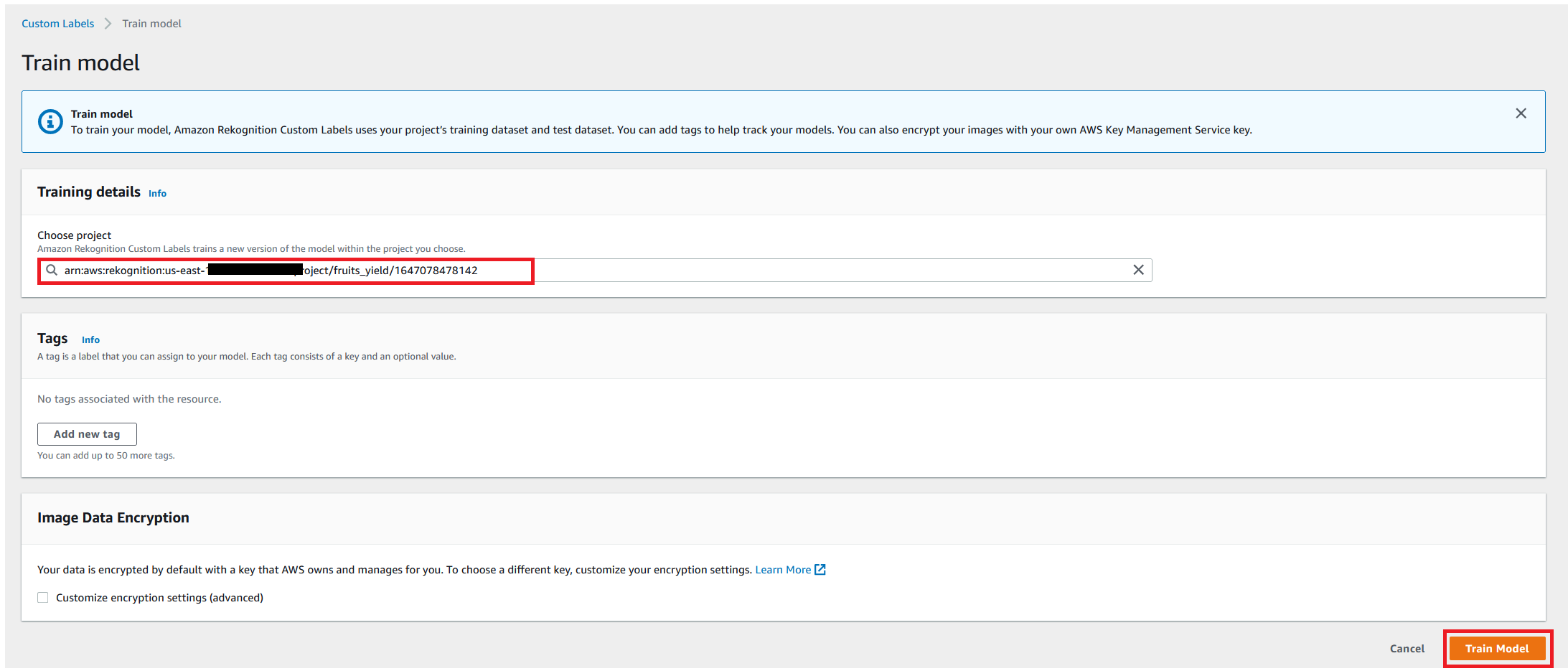
Wait for the training to complete. Now you can start testing the performance for this trained model.
Test your model
Your agriculture yield measuring model is now ready for use and should be in the Running state. To test the model, complete the following steps:
Step 1 : Start the model
On your model details page, on the Use model tab, choose Start.

Rekognition Custom Labels also provides the API calls for starting, using, and stopping your model.
Step 2 : Test the model
When the model is in the Running state, you can use the sample testing script analyzeImage.py to count the amount of fruit in an image.
- Download this script from of the GitHub repo.
- Edit this file to replace the parameter
bucketwith your bucket name andmodelwith your Amazon Rekognition model ARN.
We use the parameters photo and min_confidence as input for this Python script.

You can run this script locally using the AWS Command Line Interface (AWS CLI) or using AWS CloudShell. In our example, we ran the script via the CloudShell console. Note that CloudShell is free to use.
Make sure to install the required dependences using the command pip3 install boto3 PILLOW if not already installed.

- Upload the file
analyzeImage.pyto CloudShell using the Actions menu.
The following screenshot shows the output, which detected two fruits in the input image. We supplied 15.jpeg as the photo argument and 85 as the min_confidence value.

The following example shows image 15.jpeg with two bounding boxes.

You can run the same script with other images and experiment by changing the confidence score further.
Step 3: Stop the model
When you’re done, remember to stop model to avoid incurring in unnecessary charges. On your model details page, on the Use model tab, choose Stop.
Clean up
To avoid incurring unnecessary charges, delete the resources used in this walkthrough when not in use. We need to delete the Amazon Rekognition project and the S3 bucket.
Delete the Amazon Rekognition project
To delete the Amazon Rekognition project, complete the following steps:
- On the Amazon Rekognition console, choose Use Custom Labels.
- Choose Get started.
- In the navigation pane, choose Projects.
- On the Projects page, select the project that you want to delete.
- Choose Delete.
The Delete project dialog box appears.
- Choose Delete.
- If the project has no associated models:
- Enter delete to delete the project.
- Choose Delete to delete the project.
- If the project has associated models or datasets:
- Enter delete to confirm that you want to delete the model and datasets.
- Choose either Delete associated models, Delete associated datasets, or Delete associated datasets and models, depending on whether the model has datasets, models, or both.
Model deletion might take a while to complete. Note that the Amazon Rekognition console can’t delete models that are in training or running. Try again after stopping any running models that are listed, and wait until the models listed as training are complete. If you close the dialog box during model deletion, the models are still deleted. Later, you can delete the project by repeating this procedure.
- Enter delete to confirm that you want to delete the project.
- Choose Delete to delete the project.
Delete your S3 bucket
You first need to empty the bucket and then delete it.
- On the Amazon S3 console, choose Buckets.
- Select the bucket that you want to empty, then choose Empty.
- Confirm that you want to empty the bucket by entering the bucket name into the text field, then choose Empty.
- Choose Delete.
- Confirm that you want to delete the bucket by entering the bucket name into the text field, then choose Delete bucket.
Conclusion
In this post, we showed you how to create an object detection model with Rekognition Custom Labels. This feature makes it easy to train a custom model that can detect an object class without needing to specify other objects or losing accuracy in its results.
For more information about using custom labels, see What Is Amazon Rekognition Custom Labels?
About the authors
 Dhiraj Thakur is a Solutions Architect with Amazon Web Services. He works with AWS customers and partners to provide guidance on enterprise cloud adoption, migration, and strategy. He is passionate about technology and enjoys building and experimenting in the analytics and AI/ML space.
Dhiraj Thakur is a Solutions Architect with Amazon Web Services. He works with AWS customers and partners to provide guidance on enterprise cloud adoption, migration, and strategy. He is passionate about technology and enjoys building and experimenting in the analytics and AI/ML space.
 Sameer Goel is a Sr. Solutions Architect in the Netherlands, who drives customer success by building prototypes on cutting-edge initiatives. Prior to joining AWS, Sameer graduated with a master’s degree from Boston, with a concentration in data science. He enjoys building and experimenting with AI/ML projects on Raspberry Pi. You can find him on LinkedIn.
Sameer Goel is a Sr. Solutions Architect in the Netherlands, who drives customer success by building prototypes on cutting-edge initiatives. Prior to joining AWS, Sameer graduated with a master’s degree from Boston, with a concentration in data science. He enjoys building and experimenting with AI/ML projects on Raspberry Pi. You can find him on LinkedIn.