AWS Storage Blog
CME Group accelerates cloud migration with AWS Storage Gateway
At CME Group, the world’s leading and most diverse derivatives marketplace, we offer futures and options across every investible asset class, from corn to Bitcoin. This breadth means our global, electronic markets are powered by data – and lots of it. Making sure that our customers have access to the market data that they need to inform their risk management and trading decisions is a crucial priority. As our legacy technologies became outdated and costly to maintain, we began considering cloud-based solutions for those priorities, and a big question we had to answer (that is still relevant) was: how do we manage all of that data?
In order to tackle this and other questions around how we would make the move to cloud, CME Group formed a Platform Engineering team. Our leadership team tasked us with designing a robust, secure, and fault-tolerant solution that could allow the organization to make this transition from on premises to cloud while minimizing the impacts on other team’s existing project workloads. In this blog, I discuss how we at CME Group leveraged AWS Storage Gateway to help meet these requirements. I’ll also discuss the evolution of our architecture over time, leveraging AWS Storage Gateway.
Phase 1: The innovator
Because CME Group has an established datacenter footprint, our first objective was to determine whether there was a strong need and demand for cloud-based solutions. Global distribution of CME Group market data via our public website gave us the first opportunity to answer that question. Legacy technologies that were the basis of our existing system were facing costly upgrades and had become exceedingly complex over time, and so it made sense to retire them in favor of a new simplified solution. We needed the ability to distribute both static content and streaming data to a global audience. A cloud-based solution seemed to be exactly what we were looking for, while enabling us to realize significant cost savings.
One big challenge we immediately faced was how to identify and catalogue all of the existing workflows to our website that CME teams built over the last couple of decades. Identifying and asking each of those corresponding teams to make the necessary changes to move to a new set of tools and processes was going to be difficult, and wouldn’t meet our mandate to limit impacts on other teams. We reached out to our AWS Account Team for some help, and they introduced us to AWS Storage Gateway as a potential solution. Storage Gateway is a hybrid cloud storage service that provides on-premises access to virtually unlimited cloud storage. As we learned more about Storage Gateway, we realized it would solve a few of our initial concerns and challenges:
- The first was the ease of transitioning existing workflows of static data to the website. As one step in the transfer of data, our existing solution was placing the files on a file share on NAS. Due to this streamlined process, we were able to quickly update that workflow by moving to a file share on a File Gateway. File Gateway, a gateway type of AWS Storage Gateway, enabled us to store and access objects in Amazon S3 from NFS or SMB file-based applications with local caching. This meant that the existing process continued to function without making any changes to our application, and we were now uploading the files to Amazon S3 as well.
- Another challenge this solution overcame was the maintenance overhead of managing IAM user credentials for applications writing to Amazon S3. Because Storage Gateway uses an IAM role, we no longer have to worry about securing and rotating IAM credentials for each application on a regular basis.
- AWS Storage Gateway also allowed us to centralize the management of many of the security controls and configurations we wanted to implement for this workflow. Specifically, we could configure the correct encryption, S3 storage class, and force the application workflows to use AWS Direct Connect so that access could be limited to our VPC endpoints for S3.
With those concerns addressed, we deployed Storage Gateway using the following architecture, enabling parallel testing and eventual migration to the new website.
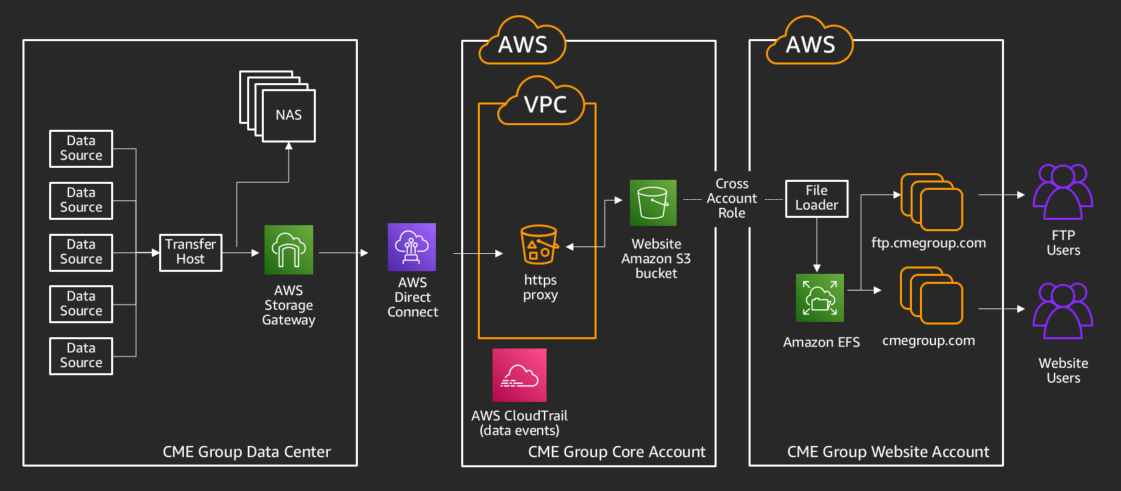
With this design, using cross-account Amazon S3 access enabled us to further isolate the web-facing assets to the perimeter. This simplified how we share data, without requiring any direct network access to our transferring AWS account. We also chose to use Amazon EFS as the storage for presenting data to our users in order to increase the speed and responsiveness of the website. Since Amazon EFS is elastic, automatically scaling up or down with usage, and adheres to expected file system directory structure, file naming conventions, and permissions, it easily integrates and scales with our website.
Phase 2: The early adopters
After our success in this initial project, other internal teams at CME came calling with similar requirements. Because of the initial investments we had made in automation and security, it was much simpler and faster to onboard new use cases to the solution. We could spin up AWS Storage Gateways quickly via automation, scoped to their specific datasets using IAM permissions, and give them to application teams for usage – in minutes.
Moving much more data
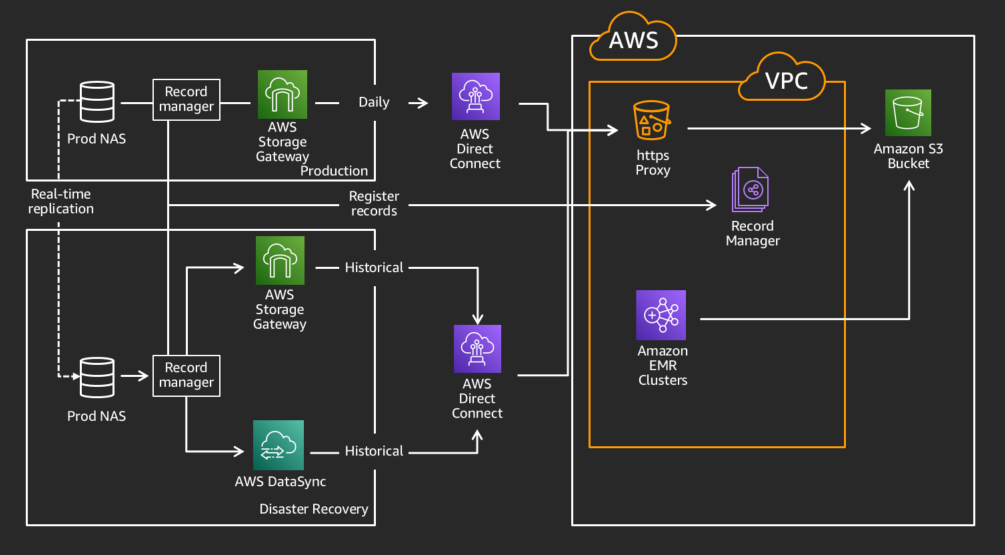
The next use case that presented itself as a good fit for moving to the cloud involved a data processing solution that was outgrowing its existing footprint on premises. In order to meet our business requirements, we would need to migrate a historical dataset, support ongoing daily data loads, and allow querying across the full dataset. The datasets we needed to migrate had two distinct patterns. In one pattern, we would need to transfer a small number of large files daily, and in the other pattern, we would need to transfer a large number of very small files daily. For the large files, the existing AWS Storage Gateway solution worked well in testing, and we were able to quickly implement that into production. However, for the very large number of small files (~1 million per day) use case, it did not meet the performance we needed due to the number of API calls being made to AWS. This was around the time of the AWS DataSync launch in November 2018. DataSync is an online data transfer service that simplifies, automates, and accelerates moving data between on-premises storage systems and AWS Storage services, in addition to between AWS Storage services. We partnered with AWS technical resources to validate a solution using DataSync, allowing for the writes of the large number of files to be expedited significantly. Similar to Storage Gateway, DataSync also enables choosing the S3 storage class that the data is written to, and supports transferring data from on premises while staying within the same VPC, without sending data over the public internet.
Moving these different datasets using AWS Storage Gateway and AWS DataSync enabled us to migrate our historical data without disrupting our production workloads, which used AWS Direct Connect circuits for real-time data replication. To assure we did not have any impact on those flows, we used our redundant, mostly idle, disaster recovery (DR) AWS Direct Connect circuits for the migration, leaving the primary production paths for real-time traffic. This setup allowed us to migrate over a petabyte of data without affecting our production workload.
Using the data
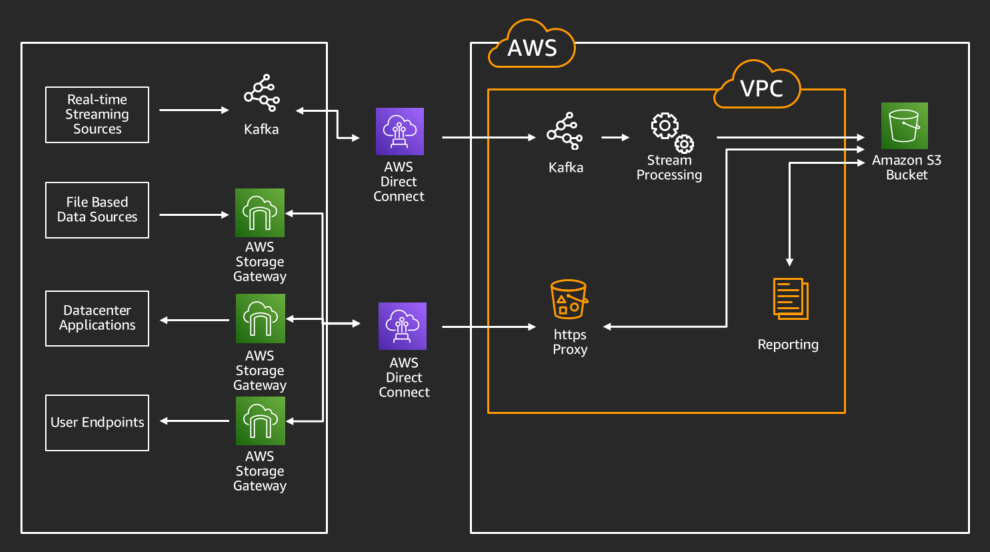
Alongside the static datasets we were moving via a daily cadence, we also implemented a real-time streaming data solution using Kafka MirrorMaker as the primary transport mechanism. This, along with the processing capabilities offered via Amazon EMR, allowed our data science and development teams to have access to unprecedented on-demand compute power. This meant more data and more insights on our data. However, we needed a way for these results and datasets to be migrated back to our internal datacenters and users for easier consumption.
Given our prior investments in automation around AWS Storage Gateway, bringing data back to the datacenter was easy, and we were able to implement a solution quickly. It was simply a reverse of the existing workflows, mounting file shares presented by Storage Gateways on the new hosts, and we were done – or so we thought. The last hurdle that we identified in testing was assuring the AWS Storage Gateways would be refreshed at the right cadence. This was important because we needed updates made in Amazon S3 (say, from an Amazon EMR process) to show up on the NFS mounts on our datacenter-based machines. We initially implemented this as an AWS Lambda function, driven by an S3 bucket notification on the specific prefixes we needed to share back. More recently, thanks to the work of the AWS Storage Gateway service team, we have begun migration to the automatic refresh capability now available on the gateways themselves.
For our data science community, there was a need to get reports and datasets now living in Amazon S3 back to Windows workstations for distribution to other business users. For this, we implemented AWS Storage Gateway with an SMB file share, which enabled us to use Active Directory integration to provide user groups with access to the specific datasets they had permission to access. Using Active Directory integration allows us to use our existing enterprise credentialing tools to enable access to departmental-based shares, enabling business users to get to the results of their analytics without needing to involve technology teams each time they needed data retrieved. Users can provide those reports and metrics to their colleagues and management, all without needing to understand the intricacies of the solution behind the scenes.
Phase 3: The early majority
In the time since we have implemented the preceding solutions, we have identified new business requirements where cloud-based solutions meet the need. Although some of these requirements need new services to be on-boarded, this core set of data storage and data transfer capabilities has continued to be a key element in bridging the gap between our datacenters and AWS. As more and more teams at CME Group have adopted AWS Storage Gateway as part of their solution, we have continued to evolve our automation to support new features, in addition to allowing for more rapid deployment of new gateways and file shares. As AWS continues to evolve Storage Gateway and deliver on our feature requests, we have updated our internal offerings to take advantage of the new capabilities. As an example, prefix-based file shares have allowed us to reuse a single gateway virtual machine for multiple applications that share an S3 bucket, while allowing us to permission each gateway to a unique prefix (and thus, create a unique dataset).
Conclusion
Overall, AWS Storage Gateway, AWS DataSync, and the entire portfolio of AWS Storage solutions, have been a key part of our success in our early cloud migrations. These managed services allowed us to complete application migrations in a secure, reliable way, while minimizing the impact on other teams across the organization. Without these offerings, the lift to update dozens of applications would have elongated project timelines, and increased complexity in undesirable ways. Much of the success we experienced is a credit to the continued efforts of our AWS Support team, and the engineering teams behind these services. These AWS teams listened to our feedback and provided solutions that reduce our overhead and increase our ability to focus on delivering for the business.
Thank you for reading. If you have any comments or questions, please don’t hesitate to leave them in the comment.