Amazon Web Services ブログ
Category: Industries

【開催報告&資料公開】AWS メディア業界向け勉強会開催報告
2025 年 7 月 4 日(金)および 2025 年 12 月 17 日(水)に、メディア業界のお客様向けに […]

自動車および製造業界むけ AWS re:Invent 2025 のダイジェスト
AWS の年次フラッグシップイベントである AWS re:Invent 2025 は、 2025 年 12 月 […]

月刊AWS製造 2026年1月号
3号目となった月間 AWS 製造ブログでは、re:Invent 2025 の注目セッションを中心に、re:Invent 特集としてお届けします。先月号はこちらです。未読の方はあわせてご覧ください。
このブログでは開催予定のイベントや直近1カ月に発表された製造関連のブログ・サービスのアップデート・事例などをお届けしています。国内だけでなく海外の情報も含めていますので、リンク先には英語の記事・動画も含まれていますが、解説を加えていますのでご興味あればぜひご覧ください。

Amazon Kinesis Video Streams の warm ストレージ階層で長期動画保存コストを最適化
本記事は 2026年 1 月 4 日に公開された Optimize long-term video stora […]
smart EuropeがAmazon Bedrockでカスタマーサポート業務を変革した方法
自動車メーカーにとって、新型車のリリース、無線通信(OTA)によるソフトウェアアップデート、コネクテッドサービスの開始は、新鮮な顧客体験を生み出します。これらのイノベーションは運転体験の向上に役立つ一方で、自動車所有者から車両の機能、充電機能、メンテナンス手順、デジタルサービスに関する多数の問い合わせを生み出します。
AWSはsmart Europeと協力し、smart.AI Case Handlerを開発しました。このツールは、問い合わせに関するインサイトとカスタマイズされた対応を提案することで、サポート担当者の効率を大幅に向上させます。
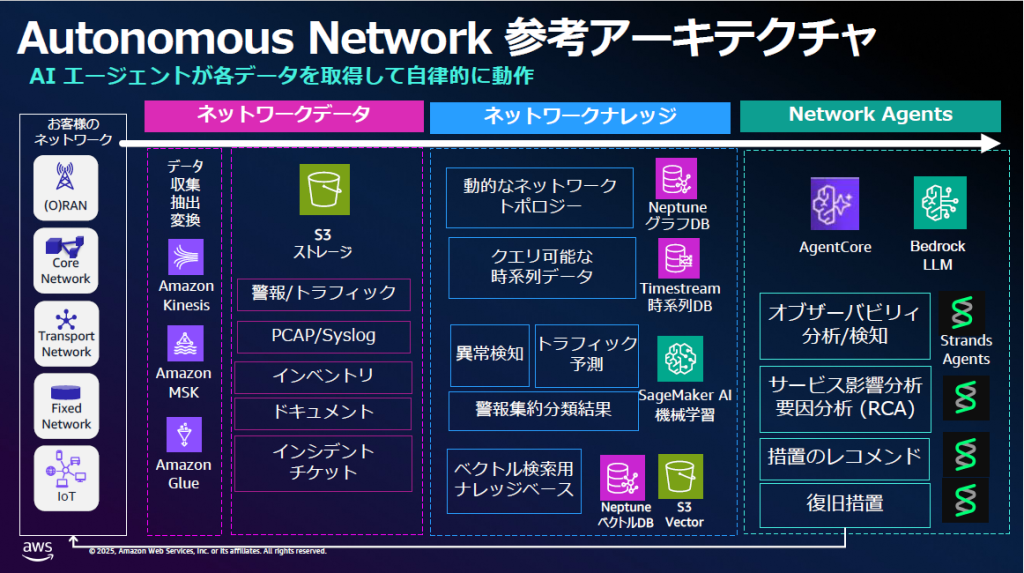
【開催報告】通信ネットワーク運用向け AI エージェントワークショップ開催しました! ( 2025 年 11 月 27 日 )
通信業界のネットワーク運用ではより安定した通信ネットワークを提供するために、障害の検知、要因特定、復旧を早期に […]

第 45 回 医療情報学連合大会 (JCMI 45th) 出展レポート
2025 年 11 月 12 日(水)~ 11 月 15 日(土)の 4 日間、兵庫県姫路市のアクリエひめじにて第 45 回医療情報学連合大会が開催されました。大会テーマは「医療 DX がもたらす医療情報新時代」。参加登録者数は 3,800 名を超え、現地では 2,900 名が参加されました。AWS は本大会において、スポンサードセッション「生成AIとヘルステックの融合が拓く、次世代の医療サービス」と展示ブースでの情報提供を通じて、医療関係者・研究者の皆様と医療 DX と生成 AI 活用の最新動向を共有する機会をいただきました。本ブログでは、セッションの登壇内容と展示ブースでの取り組みについてご報告します。

回復力のあるサプライチェーンの構築: Amazon Bedrock を活用した小売・消費財向けマルチエージェント AI アーキテクチャー
午前2時。携帯電話に緊急のアラートが届きます: 主要港湾の閉鎖、47件の入荷便への影響、そして72時間後に迫ったプロモーション開始。急いでノートパソコンを開き、在庫ダッシュボード、物流プラットフォーム、サプライヤーポータルといった十数個の異なるシステムを確認します。これらは今起きている状況の一部しか伝えておらず、必要な答えは得られません。市場シェアを競合他社に奪われる前に、どのように出荷を再ルーティングし、在庫を再配分し、プロモーションでコミットした出荷量を維持できるのでしょうか?

お客様事例をベースとした金融アーキテクチャ解説を公開(金融リファレンスアーキテクチャ日本版 2025)
「AWS金融リファレンスアーキテクチャ日本版」では、2022年の初版公開以来、継続的にコンテンツの拡充を進めています。今回のアップデートでは、特定のユースケースにおける具体的なお客様事例をもとに、より詳細な考慮点やアーキテクチャ上の決定根拠を知りたいというニーズに対応しました。国内のみならずグローバルも含めた先進事例を分析し、アーキテクチャ上の重要ポイントを整理したドキュメントとして公開しています。

AWS re:Invent 2025:ヘルスケア・ライフサイエンスにおける変革の瞬間
このブログは、 “AWS re:Invent 2025: A transformative moment fo […]