AWS Partner Network (APN) Blog
Building with Cells: High Availability and Disaster Recovery Strategies for ADP’s Globally Distributed Enterprise Platforms
By Jesse White, Senior Director – ADP
By John Majarwitz, Sr. Manager Solutions Architecture – AWS
By Aish Gopalan, Sr. Global Accounts Solutions Architect – AWS
 |
| ADP |
 |
Lifion by ADP is building the Next Generation HCM, a comprehensive solution that combines advanced cloud-based technology, data-driven insights, and deep human capital management (HCM) expertise to create a flexible platform that empowers businesses to evolve and grow.
Lifion is an Amazon Web Services (AWS)-qualified software offering that builds human capital management (HCM) software to help large, international enterprises manage their workforce.
Next Gen HCM customers are globally distributed organizations with diverse locality requirements and governmental controls that often change. To meet these demands, Next Gen HCM requires a platform and operating model that allows it to ship software quickly, safely, and securely around the world.
Working with AWS, Lifion’s engineering team built a Kubernetes and cloud-native platform comprised of 250+ microservices, with hundreds of backing databases and other stateful data management infrastructure.
By using AWS managed services, Lifion is able to reduce operational overhead on its DevOps, security, and site reliability engineering (SRE) teams.
In addition, Lifion uses a global reliability operating model (GROM)—a comprehensive approach created at ADP, an AWS Partner—to develop complex software in the cloud. This is powered by document-driven, self-service onboarding capabilities that enable autonomous software engineering teams.
In this post, we will discuss Lifion’s Kubernetes availability strategy, the datastore design principles used to provide high reliability, and their approach to cell-based reliability engineering (CBRE), which provides mechanisms to compose and re-compose ADP systems against interruptions.
GROM and Cell-Based Engineering
CBRE is Lifion’s general availability strategy, which relies on choosing the right level of infrastructure abstraction and pairing it with an operating model that builds on the basic principles of DevOps, security, and SRE. The result: a hyper-productive platform engineering group working 24×7 across geographies, while avoiding customer downtime and service interruptions.
Next Gen HCM’s active-isolated approach enables client data, client configuration, and the copy of the infrastructure to be isolated within a region, creating a failure domain that encapsulates a set of clients in a given geographic area.
Lifion provides reliability for both internal application development and external customer usage 24×7 across multiple regions, giving it little or no time to bring the systems offline.
To meet client SLAs while allowing for downtime associated with complex distributed systems, Lifion created a unified strategy for the following two types of outages:
- Planned maintenance activities.
- Unplanned service interruptions.
Lifion buckets these outage types (also referred to as breakage) together because both are expected disturbances within a given quarter. Each needs to be planned and accounted for automation machinery, and be transparent to customers.
While continuous deployment is another culprit that can cause downtime, this post will not focus on that. In the Next Generation HCM system, all of the builds are through code and automated pipelines, which should be considered as a requirement for cellularizing your infrastructure.
As with any software system, there’s an expected change in failure rate in the cloud that impacts end users (Lifion’s, in this case). As a result, it’s essential to build fault-tolerant systems to succeed when breakage occurs. Breakage has a direct correlation to KPIs: systems with functionality breaks during planned or unplanned windows cause an interruption of service with decreased availability.
Lifion uses four architectural strategies to manage breakage through CBRE, including:
- Cloud abstractions.
- Kubernetes availability strategy.
- Centralized, core infrastructure datastores.
- Decentralized, service-driven datastores.
Cloud Abstractions
If you’re managing an enterprise workload responsible for safeguarding billions of dollars’ worth of revenue or millions of peoples’ personally identifiable information (PII), you need to design the core of your computational execution system with the right technologies, appropriately controlled processes, and the right level of abstraction with AWS.
This dimension of GROM is predicated on choosing the right level of abstraction within AWS. To learn about abstraction in-depth, read this AWS blog post.
It’s important to note here that as the abstraction level rises, the number of incidents lowers, but incident management gets more difficult due to the abstraction—a challenge and reward in itself.
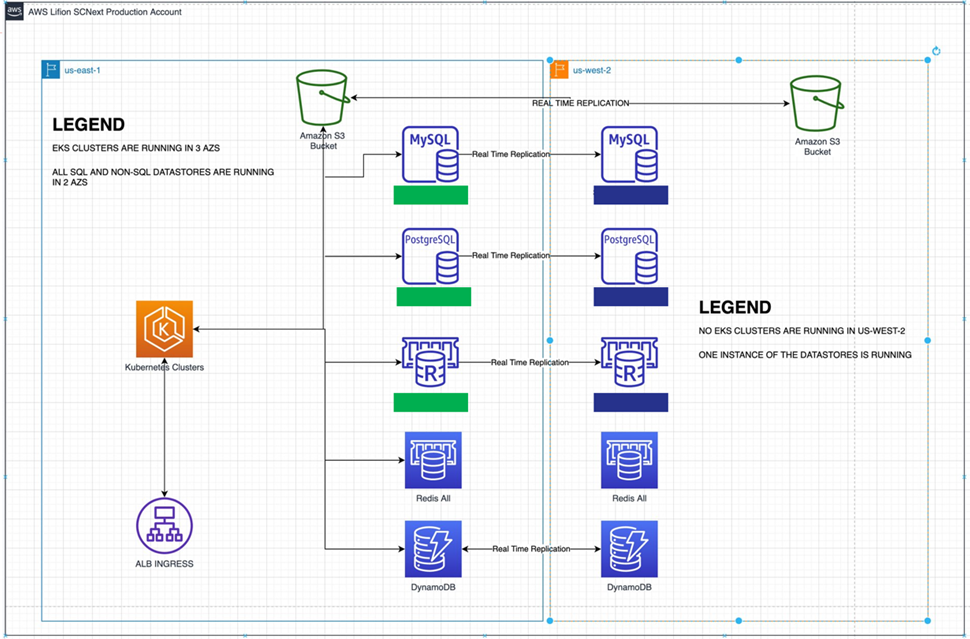
Figure 1 – Lifion during normal operations.
Kubernetes Availability Strategy
Lifion’s Amazon Elastic Kubernetes Service (Amazon EKS) container strategy is the first dimension of CBRE that helps manage breakage.
An early investor in the container ecosystem, Lifion relies heavily on the networking, storage, security, deployment, availability, and scheduling capabilities of the Kubernetes platform.
As ADP Chief Architect, Jesse White noted in his book, Getting Started with Kubernetes, choosing the right APIs and capabilities within Kubernetes can drastically reduce the operational burden on teams.
For example, you may use deployments, network policies, tagging, service limits and reservations, and taints as the core contracts available for your developers. This is a good list of APIs for your team to offer developers as you mature your platform.
Amazon EKS provides Lifion with a matrixed set of tradeoffs for reliability and abstraction. It provides container abstraction and manages Lifion’s control plane in exchange for an acceptance of some downtime to that layer. Lifion does not have similar allowances for data plane worker nodes.
Lifion does require the container orchestration platform to be always on or 100% available. In some cases, offering high availability can be expensive. However, at Lifion, downtime typically involves the control plane going offline, which prevents the organization from being able to make state changes to its system.
It doesn’t upset or prevent the application from being served to their customers. Unavailability of the data plane, which happens at the microscopic level, is managed through multiple DevOps and SRE principles.
Lifion applies these principles in several reliability strategies that allows the team to maintain nearly 100% availability at the data plane worker level. The worker fleet is designed to span multiple AWS Availability Zones (AZs). Each AZ is provisioned with enough CPU and memory to support applications in the case of a failed AZ. Further, the memory is provided with elastic dimensionality to cluster with an autoscaler (horizontal or vertical).
The result is that Lifion is guaranteed enough computational horsepower to keep serving its application to customers, despite severe outages.

Figure 2 – Lifion during all resources failover.
Centralized, Core Infrastructure Datastores
Managing core, mission-critical datastores is another key area of a cellularization strategy. Some believe a shared datastore is an anti-pattern in the distributed systems and microservices world. However, the reality is that enterprise resource planning (ERP) applications often require a system of record (SoR) to provide core business functionality.
In the HCM ecosystem, companies are required to track sensitive employee data and activities, and maintain a strict timeline of data access and movement. While the minor datastores may degrade or disappear, reducing the capability of a given business feature, the core datastores and the information they track must be either real-time or eventually consistent.
There are several strategies for managing core datastores to a higher level of availability and steps to reduce the effect of breakage, including:
Application Degradation
Graceful degradation, a well-established distributed services pattern, should be a requirement of any application running in the cloud. Breakage in the form of maintenance or outages should result in your application going into a read-only state compartmentalized by business functionality, such as functionality that allows users to interact with viewing and changing organization hierarchy.
If your microservice detects a backing datastore is unavailable, potentially through a failing Kubernetes health check, it can disable the change functionality from the application and rely on browser or container cached results to display a read-only organizational chart.
Retries, Exponential Backoff, and Circuit Breakers
An application running in the cloud cannot consider a perfect layer two of the Open Systems Interconnection (OSI) model. While the stability of the network, storage, and virtualization in the cloud has grown tremendously over the last 10 years, it’s still a shared tenancy virtualization layer where failure has a measurable impact on the availability of applications.
Applications should be built with various mechanisms for managing failure at the physical layer, including simple retries to fill in the blanks for any dropped or lost service requests.
The addition of retries can add a lot of traffic to a system, potentially overwhelming subsystems or aggravating system issues. Adding exponential backoff parameters to a system can lengthen the time between retries and lower backpressure. Circuit breakers can also help an application change behavior, and are often used to switch into read-only modes.
Overall, these methods illustrate how centralized, core databases become eventually consistent with an application state. This is an important concept in high reliability cloud systems and is used by major cloud service providers (CSPs) to manage the backing infrastructure to the public cloud.
These logics can be managed at a software layer, such as within your NodeJS or Golang code, or within the infrastructure tier with tools, such as Istio, Ambassador, or AWS App Mesh.
Infrastructure Best Practices
When managing centralized datastores with high availability, there is overlap with Kubernetes horizontal scaling best practices, such as:
- Spreading out database infrastructure across multiple AZs and AWS regions.
- Using both reader and writer nodes.
- Sharding your data to spread the logical workload.
Vertical CPU and memory scaling can also be used to ensure worker nodes have enough capacity to avoid throttling.
Lifion uses a number of AWS cloud-native data products, such as Amazon Relational Database Service (Amazon RDS), Amazon Aurora, and Amazon Simple Storage Service (Amazon S3) to manage its centralized data footprint.
Lifion is also a heavy user of globally deployable databases, which are resistant to full region failures and rapidly deployable to other AWS regions. This approach is nimbler than redeployment, which requires a pilot light data strategy that is more complex and has a medium recovery point objective (RPO) and recovery time objective (RTO).
Regular query and data optimization exercises with software engineering teams can help streamline the costs of the aforementioned approach. It also enables show-back or charge-back database utilization to microservices teams, which can incentivize efficient consumption of on demand services.
Decentralized, Service-Driven Datastores
Teams building share-nothing, decentralized datastores are best supported by a self-service, document-driven onboarding process.
In practice, using a combination of a landing page to create pull requests and AWS CloudFormation to send the request through an automation pipeline results in a cloud-native cellularized infrastructure.
Services that work best with cellularization generally have a number of properties, including:
- Treated as dependencies by an application. When a given NodeJS application initializes, it pings an endpoint to see if there is a queue, or stream, or other resource available. If that resource is not available, it issues an API to create that resource. Kubernetes health checks are useful in creating this kind of dependency check.
- Transparent backing infrastructure or infrastructure that instantiates rapidly. Amazon DynamoDB, Amazon Kinesis, Amazon Simple Queue Service (Amazon SQS) and Amazon Simple Notification Service (Amazon SNS), and serverless applications such as AWS Lambda fit this paradigm. While Amazon S3 could be considered, Lifion hasn’t seen failures in this service to justify a cellularization strategy.
Once software development teams are building cloud-native stateful infrastructure through code and pipelines, and have health check-based dependency management, your organization can move on to the next step in cellularization: moving to another geographic region.
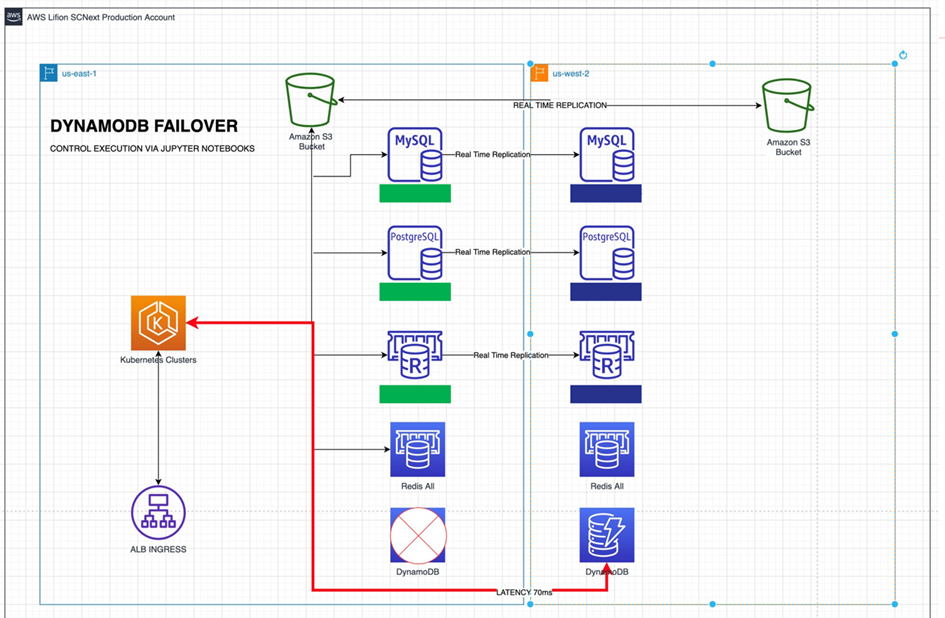
Figure 3 – Lifion during Amazon DynamoDB failover.
Putting it All Together
Next, let’s review an example of a typical production workload based on CBRE and go over the various factors that come into play to ensure resiliency during failures. For this example, we will assume the following:
- Kubernetes cluster across three AWS Availability Zones.
- Centralized datastores have been set up with global replication capabilities.
- Software development teams are using decentralized, service-driven datastores.
With a region-level failure of a cloud-native system, there are three types of major events that can happen, including:
- Isolated event in a specific AZ. This type of failure should be transparent based on your base architecture.
- Regional event that affects the entire region but doesn’t degrade your infrastructure performance. This type of failure can be handled by Amazon EKS, where the control plane fails, or Amazon Elastic Compute Cloud (Amazon EC2) instance creation is interrupted, but the impact is nominal due to the container orchestration paradigm.
- Full regional failure where the entire functionality of a cloud-native service goes offline or experiences intermittent failure that impacts your customers. This is where CBRE comes in.
Instead of maintaining cold, warm, or hot cloud-native infrastructure in another region, we are able to use our infrastructure as code (IaC) and pipelines to instantiate new, decentralized, service-driven datastores minutes after a region-level incident occurs.
As noted above, the Kubernetes and centralized datastores are resilient to region-level failures. What happens when we need to re-instantiate a piece of our infrastructure that requires a new cell?
First, the observability system and personal health dashboard notify you of a region-level failure. Second, service health checks should begin failing immediately as they are unable to reach their microservice infrastructure dependencies. This should trigger a semi-automatic or automatic process wherein your pipeline kicks off the build of a new copy of the cloud-native infrastructure in another region.
Finally, once the infrastructure has been completed, the build system should send a signal to the software to take a final step in cellularization strategy: re-routing application traffic.
Re-routing application traffic is beyond the scope of this introduction to cell-based reliability engineering, but general best practices include using the following:
- Feature flags in applications, which allow changes in DNS endpoints from failed region endpoints to active region endpoints (for example, from east.dynamodbTable.com to west.dynamodbTable.com).
- Environment variables in containers to switch DNS entries similar to feature flags.
- Load balancers to automatically route traffic to endpoints that show as healthy.
- Amazon Route 53 routing policies, which allow you to intelligently move traffic from one region to another based on health checks and application availability.
With the approach above, all of the pieces are in place to be able to weather a region-level failure. The application is resilient on the Kubernetes and central data planes, and microservices are able to re-instantiate their data dependencies in other regions in a semi- or full-automatic manner that is near-seamless to end users.
Conclusion
Today, reliability is the most sought-after parameter for any product. Abstracting and isolating the components (compute, storage, infrastructure) of the product architecture enables better cell-based control and ensures seamless failover to another AZ or region to deliver business continuity.
While orchestrating this methodology requires a great deal of planning and execution—and a cultural mindset shift for some organizations—CBRE and the principles of cellularization can save money, reduce the complexity of running active/passive or active/active infrastructure strategies, and allow your organization to leverage a solution built on AWS.
To learn more about Lifion by ADP, please visit the website.
.
 .
.
ADP – AWS Partner Spotlight
ADP is an AWS Partner and global provider of cloud-based human capital management (HCM) solutions that unite HR, payroll, talent, time, tax and benefits administration, and a leader in business outsourcing services, analytics and compliance expertise.
Contact ADP | Partner Overview
*Already worked with ADP? Rate the Partner
*To review an AWS Partner, you must be a customer that has worked with them directly on a project.