AWS Partner Network (APN) Blog
How nClouds Helps Accelerate Data Delivery with Apache Hudi on Amazon EMR
By Deepu Mathew, Sr. DevOps Engineer at nClouds
By Fernando Gonzalez, Sr. DevOps Engineer at nClouds
By Kireet Kokala, VP Big Data & Analytics at nClouds
 |
At nClouds, customers often ask us for help with their data and analytics platform when their business decisions depend on access to near real-time data. Yet, the amount of data created and collected accelerates daily, making data analysis a daunting task when using traditional technologies.
In this post, we’ll discuss how nClouds can help you with the challenges of data latency, data quality, system reliability, and data privacy compliance.
Apache Hudi on Amazon EMR is an ideal solution for large-scale and near real-time applications that require incremental data pipelines and processing. This post provides a step-by-step method to perform a proof of concept for Apache Hudi on Amazon EMR.
nClouds is an AWS Premier Consulting Partner with AWS Competencies in DevOps, Data & Analytics, and Migration, as well as a member of the AWS Managed Service Provider (MSP) and AWS Well-Architected Partner Programs.
Our mission at nClouds is to help you build and manage modern infrastructure solutions that deliver innovation faster.
Solution Overview
Apache Hudi is an open source data management framework used to simplify incremental data processing and data pipeline development. It was originally developed at Uber in 2016 to enable faster data for petabyte-scale data analytics, low latency database ingestion, and high efficiency.
Apache Hudi is often used for simplified data pipelines into data lakes and analytics services, Change Data Capture (CDC) with record-level granularity, and near real-time analytics of data sets by SQL query engines like Apache Hive and Presto. To see the baseline Hudi architecture, visit hudi.apache.org.
Amazon EMR is the leading cloud big data platform for processing vast amounts of data using open source tools such as Apache Hudi, Apache Spark, Apache Hive, Apache HBase, Apache Flink, and Presto. Apache Hudi is automatically installed in your Amazon EMR cluster when you choose Spark, Hive, or Presto as a deployment option.
In 2019, the Amazon EMR team began working closely with the Apache Hudi community to contribute patches and bug fixes and add support for AWS Glue Data Catalog.
Apache Hudi excels at rapid data ingestion onto Hadoop Distributed File System (HDFS) or cloud storage, and accelerating ETL/Hive/Spark jobs. Using Hudi, you can handle either read-heavy or write-heavy use cases, and it will manage the underlying data stored on Amazon Simple Storage Service (Amazon S3).
Data Latency
High data latency can hinder customers’ ability to achieve and sustain operational excellence, impacting the timely development and delivery of new products and services, profitability, and fact-based decision-making.
In such cases, we’ll recommend Apache Hudi, as its automated incremental update processing performed by the DeltaStreamer utility enables business-critical data pipelines to have high efficiency with near real-time latency. These incremental files are read and changes are published every time you query the table.
Apache Hudi saves time by handling queries for near real-time data, as well as queries that require an incremental pull for point-in-time data analysis (also known as “as-of” or “longitudinal” data analysis).
Data Quality
Time constraints resulting from the growing volume of data can cause difficulties when judging quality. Extracting high-quality data from massive, variable, and complicated data sets makes data integration problematic, especially when there’s a mix of unstructured, semi-structured, and structured data.
When data is rapidly changing, its quality depends on its timeliness. Apache Hudi’s ability to reconcile differential data structures, automate incremental data updates, and efficiently ingest streaming data contribute to the successful extraction and integration of high-quality data.
Hudi can be integrated with AWS services such as Amazon Simple Workflow (Amazon SWF), AWS Data Pipeline, and AWS Lambda to automate live data lake workflows.
System Reliability
When we perform an AWS Well-Architected Review (an architectural assessment using best-practices from the AWS Well-Architected Framework), one of the pillars we focus on is architectural reliability. System reliability can be at risk if data is ingested via ad hoc extract, transform, load (ETL) jobs, and there is no formal schema communication mechanism in place.
We like Apache Hudi’s ability to control and manage file layouts in the data lake. This capability is vital to maintaining a healthy data ecosystem because it improves reliability and query performance.
With Hudi, users don’t need to load new data and clean it using ETL. The newly ingested data and changes from the previous layers are automatically updated from the sources, triggering an automated workflow when the new data is saved.
AWS Database Migration Service (AWS DMS) then registers the update, creating an Apache Parquet file in the source location on Amazon Simple Storage Service (Amazon S3). It uses Apache Avro as the internal canonical representation for records, providing reliability in data ingestion or ETL pipelines.
Compliance with Data Privacy Regulations
All interaction with data in the data lake is managed exclusively by Apache Hudi and the services providing access to the data.
Apache Hudi provides a framework that enables Amazon S3-based data lakes to comply with data privacy laws. It enables record-level updates and deletes so users may choose to exercise their right to be forgotten or change their consent as to how their data can be used.
Building the Proof of Concept
At nClouds, we built a non-customer-facing proof-of-concept (PoC) to show how a change in a dataset can be applied using Hudi’s insert, update, and delete operations. The economic impact of COVID-19 inspired us to use data related to the pandemic for our PoC.
A recent TDWI study found that, due to the implications of the pandemic, more than half of data and analytics professionals are asked to answer new types of questions. About a third of respondents said they needed to update their models and other analytics to deal with changing customer behaviors by retraining models or recasting customer segments.
Our PoC shows simple data from Amazon Relational Database Service (Amazon RDS) > Amazon S3 Record Set Change > Hudi to quickly apply delta changes. We needed an environment to run our test, including Amazon RDS, an AWS DMS task, an Amazon EMR cluster, and an S3 bucket.
Finally, as a step to quickly visualize the dataset and data changes, we opted to use Amazon QuickSight to showcase reports.
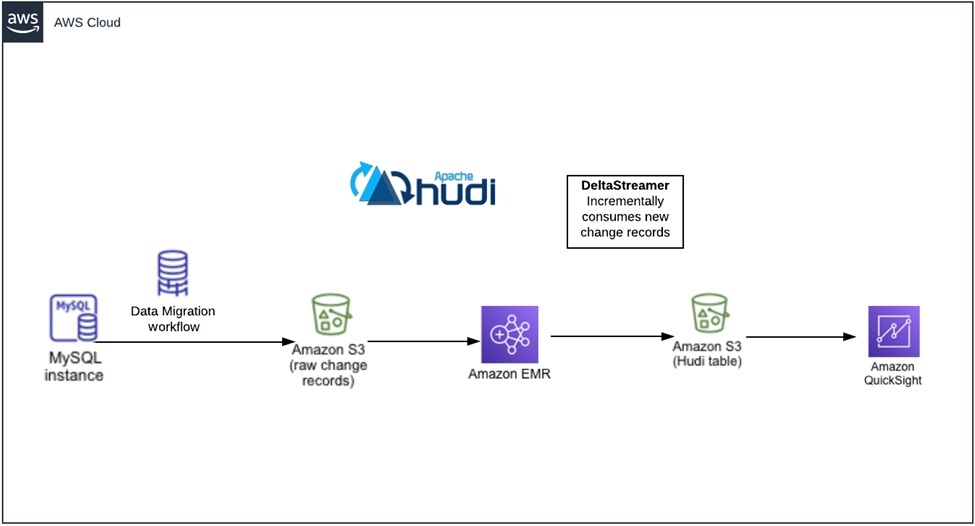
Figure 1 – High-level view of the final end-to-end architecture.
Using the approach we took to create the PoC, here is a step-by-step guide to how you can apply the same approach to your projects.
Step 1: Amazon RDS Setup
- In the Amazon RDS dashboard, go to DB Parameter groups section and create a new parameter group. Set the binlog format to ROW.
. - Create a new Amazon RDS instance. Make sure you select the DB Parameter group you set up and enable automatic backups.
. - Once this is created, connect to it and create the following MySQL schema:
Step 2: AWS DMS Setup
Next, you need to start replicating this data to Amazon S3 using AWS DMS tasks. You’ll need a replication instance to run the endpoint test and replication task.
- Go to the AWS DMS dashboard and create a new replication instance. Wait until it’s available.
. - Start with two endpoints—one for the Amazon RDS source, and another for the S3 target.
. - Check the status of the test; it must be successful for a task to start.
. - Create an AWS Identity and Access Management (IAM) role with the following policy:
- Create the Amazon S3 target. Be sure to write it in Apache Parquet file format with the following settings:

- Test it to check if it works. The image below shows the result of a successful test of the AWS DMS) endpoint.

Step 3: AWS DMS Task Setup
- Now, you can create the task and run it. Make sure you select your schema from the drop-down menu. If it doesn’t appear, then you need to fill out the table mapping.
. - Click Create task and wait until it begins to replicate the data.
Step 4: Amazon EMR Cluster Setup
Amazon EMR (release version 5.28.0 and later) installs Apache Hudi components by default when Apache Spark, Apache Hive, or Presto are installed.
Apache Spark or the Apache Hudi DeltaStreamer utility can create or update Apache Hudi datasets. Apache Hive, Apache Spark, or Presto can query an Apache Hudi dataset interactively or build data processing pipelines using incremental pull (pulling only the data that changed between two actions).
Following is a tutorial on how to run a new Amazon EMR cluster and process data using Apache Hudi.
- Go to the Amazon EMR dashboard.
. - Fill out the configuration as follows:

- Once the cluster is running, execute the following script to set up the database. Run the Apache Spark command to see the current database state with two rows of initial inserts.
Step 5: Applying Change Logs Using Apache Hudi DeltaStreamer
- To start consuming the change logs, use the Apache Hudi DeltaStreamer running as an Apache Spark job on your favorite workflow schedule. For example, start an Apache Spark shell as follows:
- Here’s the Apache Hudi table with the same records as the upstream table (with all the
_hoodiefields as well):
- Make a database change to see the additional row and updated value.
. - AWS DMS will pick it up immediately and then rerun the same Apache Hudi job once the updates are in the source Amazon S3 bucket, adding a new Apache Parquet file to the AWS DMS output folder.
- When the Apache Hudi DeltaStreamer command is rerun, it will apply the Apache Parquet file to the Apache Hudi table.
. - Here are the Apache Hudi results after running the Apache Spark job:
- Convert the data to csv format so it can be easily read from Amazon QuickSight:
Once data is converted to .csv using the above command, it presents Amazon QuickSight with an easy to read data format that can be visualized. Figure 2 shows one representation of the data from the raw (.csv) source in QuickSight.
This view of the data breaks down the number of cases on a certain date by state. As Hudi makes updates to tables with new data (that can be directly streamed in), near real-time or real-time reporting via QuickSight is enabled.

Figure 2 – This view of the data breaks down the number of cases on a certain date by state.
Conclusion
In this post, we stepped you through our non-customer-facing PoC solution to set up a new data and analytics platform using Apache Hudi on Amazon EMR and other managed services, including Amazon QuickSight for data visualization.
If your business decisions depend on access to near real-time data, and you’re facing challenges such as data latency, high data quality, system reliability, and compliance with data privacy regulations, we recommend implementing this solution from nClouds. It’s designed to accelerate data delivery in large-scale and near real-time applications that require incremental data pipelines and processing.
Need help with data and analytics on AWS? Contact nClouds for help with all of your AWS infrastructure requirements.
The content and opinions in this blog are those of the third party author and AWS is not responsible for the content or accuracy of this post.
.

.
nClouds – AWS Partner Spotlight
nClouds is an AWS Premier Consulting Partner and Managed Service Provider that helps customers build and manage modern infrastructure solutions that deliver innovation faster.
Contact nClouds | Practice Overview
*Already worked with nClouds? Rate the Partner
*To review an AWS Partner, you must be a customer that has worked with them directly on a project.