AWS Partner Network (APN) Blog
Optimizing Supply Chains Through Intelligent Revenue and Supply Chain (IRAS) Management
By Daisuke Tsukamoto, Sr. Manager, Applied Intelligence at Accenture
By Eunpyung Park, Manager, Applied Intelligence at Accenture
By Karthik Sonti, Principal Solutions Architect for AI/ML at AWS
 |
Fragmented supply-chain management systems can impair an enterprise’s ability to make informed, timely decisions. Accenture’s Intelligent Revenue and Supply Chain (IRAS) platform integrates insights generated by machine learning (ML) and artificial intelligence (AI) models into an enterprise’s technical and business ecosystems.
IRAS is an in-house solution developed by Accenture on the Amazon Web Services (AWS) Cloud. It enables a business to proactively optimize and automate complex business operations. For instance, they can forecast the quantity of individual stock keeping units (SKUs) that need to be ordered on a rolling basis to stock key inventories.
Multi-million dollar business investments to improve supply chains fail when they rely on heuristics derived from systems, tools, and processes that do not scale. Enterprises all too often optimize individual links within fragmented silos, doing nothing to improve the overall supply chain. Sometimes they break it entirely.
When data sharing across silos is severed, business operators are left without end-to-end visibility. They cannot dynamically adjust to disruptions upstream or downstream of the process. As a result, their production outputs exceed budgeted time and cost, they cannot standardize or automate repetitive decision making, and their stagnant procedures fail to undergo Kaizen.
In spite of their large investments, enterprises are left unable to operate efficiently, and with the granularity to meet the unique expectations of today’s fast-moving customers.
This post explains how Accenture’s IRAS solution is architected, how it can coexist with other ML forecasting models or statistical packages, and how you can consume its insights in an integrated way.
Accenture is an AWS Partner Network (APN) Premier Consulting Partner with AWS Competencies in Industrial Software and Machine Learning, among others. Accenture is also an AWS Managed Service Provider.
How IRAS Integrates Supply Chain Management
Currently, supply chain activities are driven by the planning cycles of static sales and operations, and are executed manually. By deploying Intelligent Revenue and Supply Chain (IRAS), supply chain operators gain access to multi-dimensional sales and supply chain data points provided by Amazon SageMaker Ground Truth.
The forecasting models activated by those data points enable operators to reposition themselves and assume higher-value tasks that leverage their industry expertise. Those operators can share qualitative insights backed by quantified, real-time data from supply chain systems. They can offload, to AI models, vetted downstream business actions such as adjusting procurement orders or capping sales campaign initiatives.
As they identify anomalies in attributes that impact the supply chain, AI models can recommend resolution options to the stakeholders to prevent logistical bottlenecks, and make a timely intervention. Using IRAS, sales and operational planning can evolve from linear execution to integrated dynamic execution.
The ML component of IRAS activates models that perform self-learning, prediction, and prescription of cross-functional “next steps.”
As an upstream system, AI algorithms can suggest predictive attributes to customer relationship management (CRM) and SCM systems. AI algorithms can also detect anomalies and trends, and forecast key attributes by sitting downstream to consume data from those enterprise systems. This enables supply chains to handle more complexity, making them more dynamic, flexible, adaptive, and efficient.
IRAS Reference Architecture
At Accenture, we selected the IRAS components best suited to carry out three objectives:
- Collecting and standardizing the data.
- Generating a forecast.
- Incorporating the forecast into the business process.
Figure 1 maps each component to its objective.
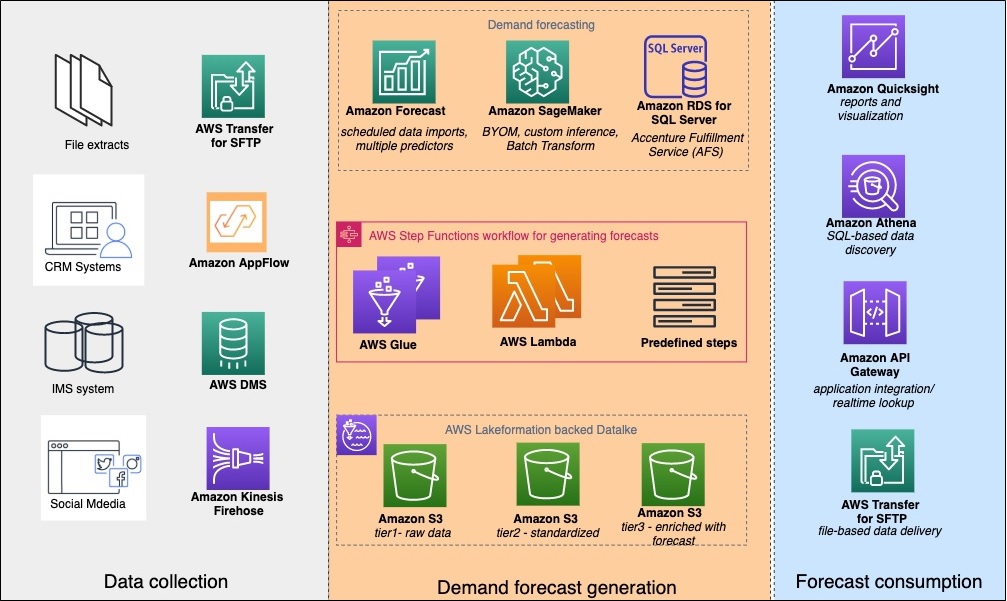
Figure 1 – IRAS objectives and their components.
IRAS uses Amazon Simple Storage Service (Amazon S3) as the data lake storage. The raw data collected from the sources is partitioned and formatted in Apache Parquet, and finally enriched with forecast insights.
We use AWS Database Migration Service (AWS DMS) to perform initial and ongoing replication from inventory management database sources. We use Amazon AppFlow to collect the data from CRM systems such as Salesforce or Zendesk.
Data from social media sources is crawled through AWS Lambda, and then delivered to Amazon S3 by Amazon Kinesis Data Firehose. We collect data from Secure File Transfer Protocol (SFTP) sources through AWS Transfer Family for SFTP.
We use AWS Glue to run Python- or PySpark-based extract, transfer, load (ETL) pipelines that prepare the data for Amazon Forecast. We build features for demand forecast ML models in Amazon SageMaker. We also train and deploy those models.
While these are the most common data sources for IRAS, you can extend the IRAS solution to collect data from other sources.
IRAS Workflow
Once the data is collected from source, AWS Lambda functions and AWS Glue jobs orchestrated by AWS Step Functions compress and organize the data into partitions. They also convert selected datasets into Parquet format for effective querying and processing by downstream applications.
Depending on the deployment style, a sequence of Lambda functions orchestrated by AWS Step Functions can import the data into Amazon Forecast. AWS Step Functions can build predictors and make API calls to retrain the custom forecast model on Amazon SageMaker. They can also export the forecasts to S3 for batch consumption.
You can query the generated forecasts using Amazon Athena, and you can incorporate them into other business applications via Amazon API Gateway. Or, you can export them to a file and deliver them by AWS Transfer Family for SFTP.
Deploying IRAS
You can deploy the IRAS solution in a greenfield setting or to complement any forecast models you may already have. Figure 2 shows the architecture for deploying IRAS when you have an existing forecasting ML model.
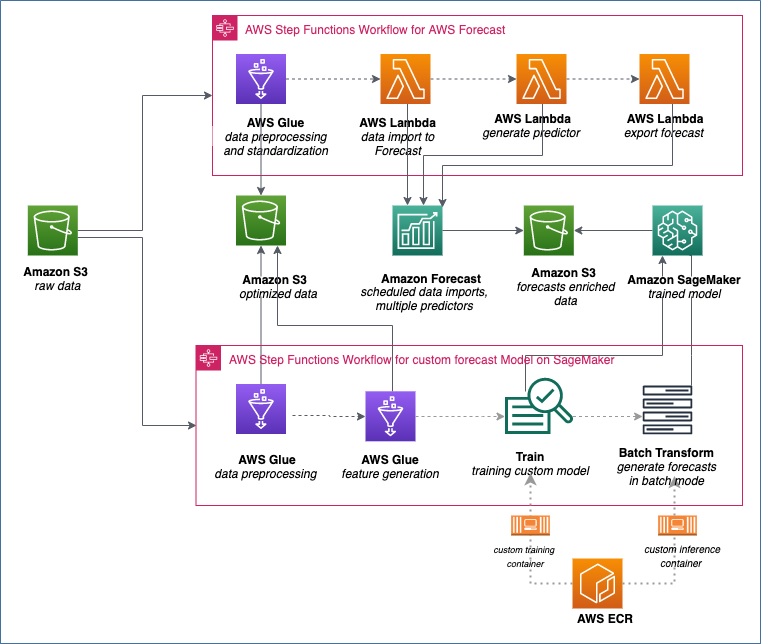
Figure 2 – Deploying IRAS into existing forecasting ML models.
Two AWS Step Function flows are key to this solution. At the top, AWS Glue jobs and AWS Lambda functions are orchestrated to convert the data from a “raw” zone into a format suitable for Amazon Forecast. They also use the Amazon Forecast API to import the data and create forecast predictors.
Depending on the use case, you could use more than one predictor. For example, an auto-regressive integrated moving average (ARIMA) model could be a popular choice for a certain class of products. A DeepAR algorithm would be more suitable for another class. Once a predictor is ready, the subsequent Lambda function calls CreateForecastExportJob to export the forecast for batch and real-time consumption.
The workflow of AWS Step Functions at the bottom of the illustration contains a sequence of AWS Glue jobs and predefined steps to pre-process the “raw” data. It serializes the data into a format required for the custom forecast models on Amazon SageMaker. Once the data is serialized, the AWS Step Functions make API calls to train the model, and call Batch transform to export the forecasts to Amazon S3.
You can deploy IRAS in a similar way for use cases where you have an existing statistical package such as Accenture Fulfilment Service (AFS), or a SAS-based solution. The next section describes how you can use IRAS to integrate the forecasts generated by these solutions into a business process.
Consuming Forecasts from IRAS
In use cases where you have an existing custom forecast ML model, it’s important to use the right forecast solution for the right item class. Figure 3 illustrates the approach IRAS adopts to incorporate forecasts from multiple systems into a business process.
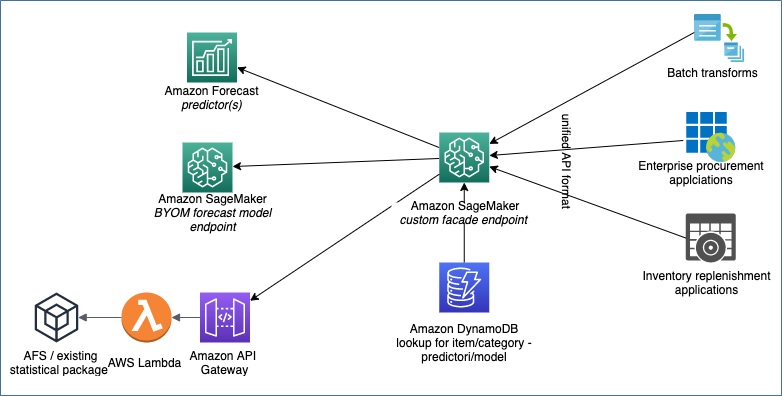
Figure 3 – How IRAS incorporates forecasts from multiple systems into a business process.
The facade endpoint on Amazon SageMaker looks up the forecast-system to item-class mapping table in Amazon DynamoDB to determine which system to call for which kind of forecasting need.
This table at its simplest form has three entries:
- item-class
- forecast-system-type
- forecast-system-endpoint
Here are some sample entries:
| Item-class | Forecast-system-type | Forecast-system-endpoint |
| Watches | Amazon Forecast | arn:aws:forecast:us-east-1:123456:forecast/myforecastarn |
| Shoes | Amazon SageMaker | arn:aws:sagemaker:us-east-1:123456:endpoint/mycustomforecastmodel |
In the initial stages of IRAS, the lookup is done deterministically in Amazon DynamoDB with the help of the previously mentioned mapping table. Eventually, once there are enough insights on each forecast system’s performance and accuracy, an ensemble ML model replaces the mapping table approach.
Amazon SageMaker Ground Truth labels the right forecast system for the right item class. The labeling is performed by the teams who are familiar with the organization’s product, inventory, procurement, and sales channels. The labels are consolidated to build an ensemble classification model that dynamically calls the right underlying forecast system for the right item class.
Figure 4 shows how an ensemble classification model can replace a deterministic lookup table approach.
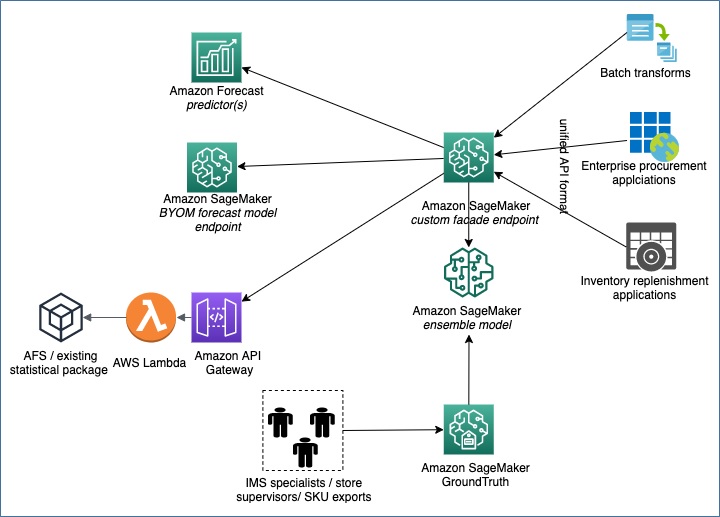
Figure 4 – How an ensemble classification model can replace a deterministic lookup table approach.
Conclusion
We have described how Accenture built an IRAS solution that you can leverage to optimize your inventory replenishment and procurement operations. You can deploy this solution in a greenfield setting where you don’t have an existing forecasting system, or you can use it to optimize your existing forecasting models or statistical packages.
To get started, engage Accenture to deploy IRAS for optimizing your inventory management operations.
.

.
Accenture – APN Partner Spotlight
Accenture is an APN Premier Consulting Partner and Managed Service Provider. A global professional services company that provides an end-to-end solution to migrate to and manage operations on AWS, Accenture’s staff of 440,000+ includes more than 4,000 trained and 2,000 AWS Certified professionals.
Contact Accenture | Practice Overview
*Already worked with Accenture? Rate this Partner
*To review an APN Partner, you must be an AWS customer that has worked with them directly on a project.