AWS Partner Network (APN) Blog
Warming Amazon EC2 Instances Using AWS Lambda to Improve Application Availability
By Dr. Stefan Jurack, Sr. IT Architect – IBM
By Dhana Vadivelan, Sr. Manager, EMEA Partner Solutions Architecture Leader – AWS
 |
One of the challenges faced by a rail manufacturer’s business application while migrating to Amazon Web Services (AWS) was the legacy nature of its Windows application. It was taking a long time to start up in the event of any unplanned downtime.
Refactoring the business application to leverage AWS cloud-native features was not a viable option in this case, as the application vendor had stopped their software maintenance and support.
This post details how AWS Premier Consulting Partner IBM leveraged AWS to improve the application’s long startup time by implementing a warming functionality using AWS Lambda and AWS Systems Manager.
The application was being used for production planning and control systems in the rail manufacturing industry. It consisted of tightly coupled legacy Windows server components, most of which used C++, .NET, and Java and were based on proprietary TCP-based communication protocols.
IBM’s top priority was improving high availability (HA) for the customer by resolving the long startup times. This issue was paired up with singular execution constraints of Windows server components, such as exclusive database locks and file handles.
Let’s deep dive on the solution architecture used to resolve the challenge. We’ll share a short brief of the approach, the AWS building blocks we used, and the code structure and logic used in an AWS Lambda function.
Challenges in Singleton Components
The customer’s legacy application running on Windows Server is often executable once at a time.
This is due to reasons such as exclusive access locks in shared file systems or databases, the storage of cursors, and intermediate results in databases to represent current processing or general states. This type of application design is referred to as a singleton component.
The basic design pattern that comes to mind when talking about improving the HA of an application is using redundant Windows Server components. In general, redundancy along with load balancers provides system availability in an event any single Windows Server component fails.
The load balancer redirects user traffic from the failed server component to the active server seamlessly. The traffic routing may be within the same data center and/or between two different data centers depending on the placement of servers.
The design below illustrates the redundant Windows Server design pattern by using Elastic Load Balancing and AWS Auto Scaling Group services.
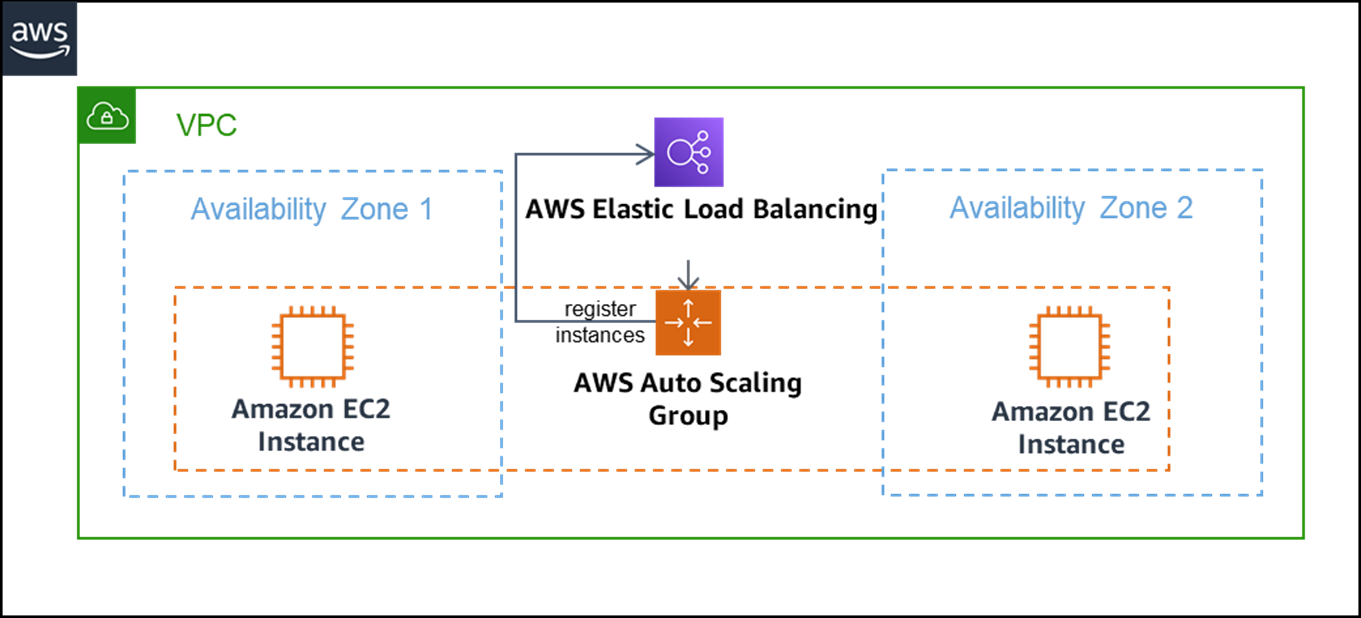
Figure 1 – Redundant server components pattern using AWS.
The Auto Scaling Group is responsible for automatic provisioning of redundant Amazon Elastic Compute Cloud (Amazon EC2) instances to satisfy a configured desired instance count, and then registering them with associated Elastic Load Balancers.
These EC2 instances are running a legacy application on Windows Server based on predefined images.
Elastic Load Balancing forwards the traffic to one of the registered instances based on the instance’s health status. Further, the Auto Scaling Group allows provisioning of instances in different AWS Availability Zones (AZs) representing both locally and logically independent data centers, therefore reducing the likelihood of outages are even more.
However, the major assumption for this pattern is that the application components are generally available and even intended to run concurrently at multiple times. Modern web frontend application components are mostly designed to satisfy that assumption; for example, by implementing stateless microservices-based applications.
The rationale behind this design pattern is to allow HA of an application. This also enables scalability, improves modularization, and supports separation of concern while striving for flexible deployments.
In the scenario we discussed above, the legacy Windows instance (running the singleton component) crashes or becomes unavailable due to a disruption. A new instance is automatically provisioned in the AZs, and Elastic Load Balancing forwards the user requests to the new instance automatically.
If the instance startup time takes longer than the acceptable time, the redundant Windows Server design pattern described above does not meet the HA requirement.
Approach to Improve Startup Time
In cases where you have Windows instances running legacy applications (with singleton components) only permitted to run once at a time, they will have a longer startup time.
A reasonable approach to address this challenge is to consider warming strategies for Windows Server. This means a new instance is started already, generally available, and ready to go while the remaining instances are in passive state.
More precisely, in the Windows operating system that includes associated services, drivers are fully loaded and working, and the application-specific critical parts, which may conflict with other actively running components, are not.
Obviously, the Elastic Load Balancer is not allowed to forward requests to a passive instance.
Solution Architecture
The design pattern below shows how a dedicated AWS Lambda function takes over registering new instances to the Elastic Load Balancer, while this is usually handled by the Auto Scaling Group.
Hence, the automatic Elastic Load Balancer registration, named Add to Load Balancer, is suspended in Auto Scaling Group configurations as a prerequisite for this design pattern.
Instead, an Amazon CloudWatch rule listens to the Auto Scaling Group and triggers the Lambda function on instance launch and terminate events.
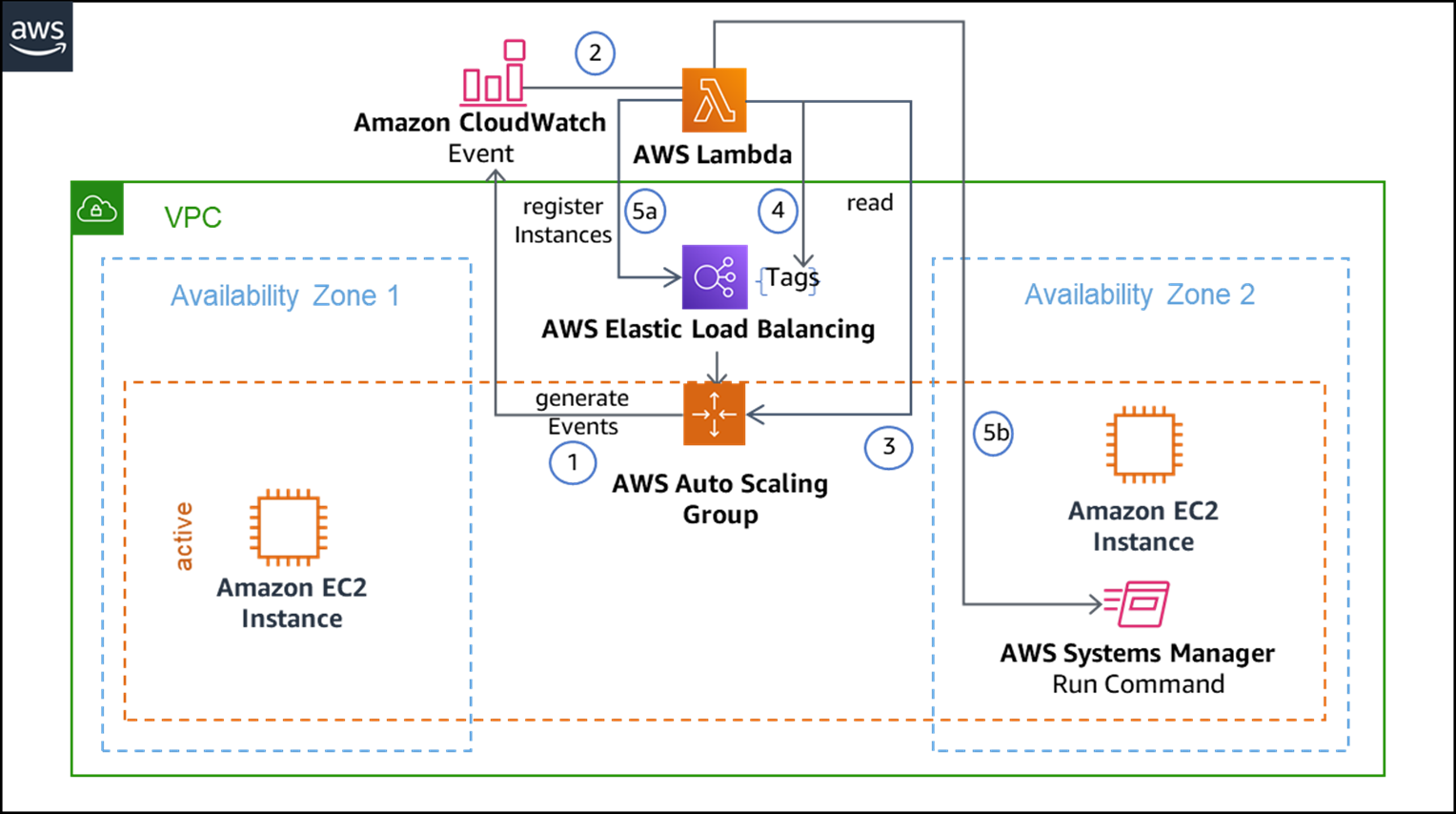
Figure 2 – Solution architecture for warming EC2 instance using AWS.
A tag appended to the associated Elastic Load Balancer declares the desired capacity. This could be the maximum number of instances to be registered simultaneously in the Elastic Load Balancer, regardless of the number of available instances in the underlying Auto Scaling Group. In the singleton component scenario, of course, this number is 1.
If the desired capacity state does not match the current state, the Lambda function takes care of the adaptation (as shown in Figure 4) by registering another instance available by the Auto Scaling Group.
Beside the actual registration of instances with an Elastic Load Balancer, passive instances may need to be activated, such as starting application-specific jobs or services. This is implemented in the form of an activation script remotely called by the Lambda function in combination with AWS Systems Manager run command.
For this to work, the instance needs to be managed by AWS Systems Manager with a running agent inside the instance.
The main idea for considering the above approach is to quickly replace a failing singleton component instance with a ready-to-go instance in the shortest possible time.
Having a passive instance in place eliminates the time needed for provisioning the Windows virtual machine and the operating system startup, as well as further preparatory load.
Code Structure and Logic
To implement this solution architecture, IBM used the Python 3.8 and well-known boto3 library for making AWS API calls. The Python code files and their relations are depicted below.
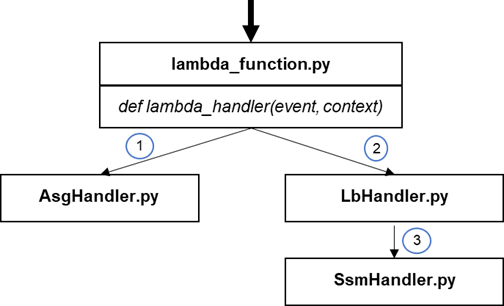
Figure 3 – Code structure.
The lambda_handler function in the ‘lambda_function.py’ files serves as the Lambda function entry point and is called by AWS due to a dedicated CloudWatch rule.
The ‘event’ parameter passes information about the triggering Auto Scaling Group, which is incorporated in the main control flow diagram, as illustrated in Figure 4.
The ‘AsgHandler.py’ file contains code responsible for Auto Scaling Group-related API calls and collects information like the list of managed instances together with their availability state and linked Elastic Load Balancer.
These values are then utilized to calculate the most suitable instance to be registered in a linked Elastic Load Balancer, implemented in ‘LbHandler.py’.
Finally, the ‘SsmHandler.py’ file encapsulates the implementation for the remote activation script execution by utilizing the AWS Systems Manager API.
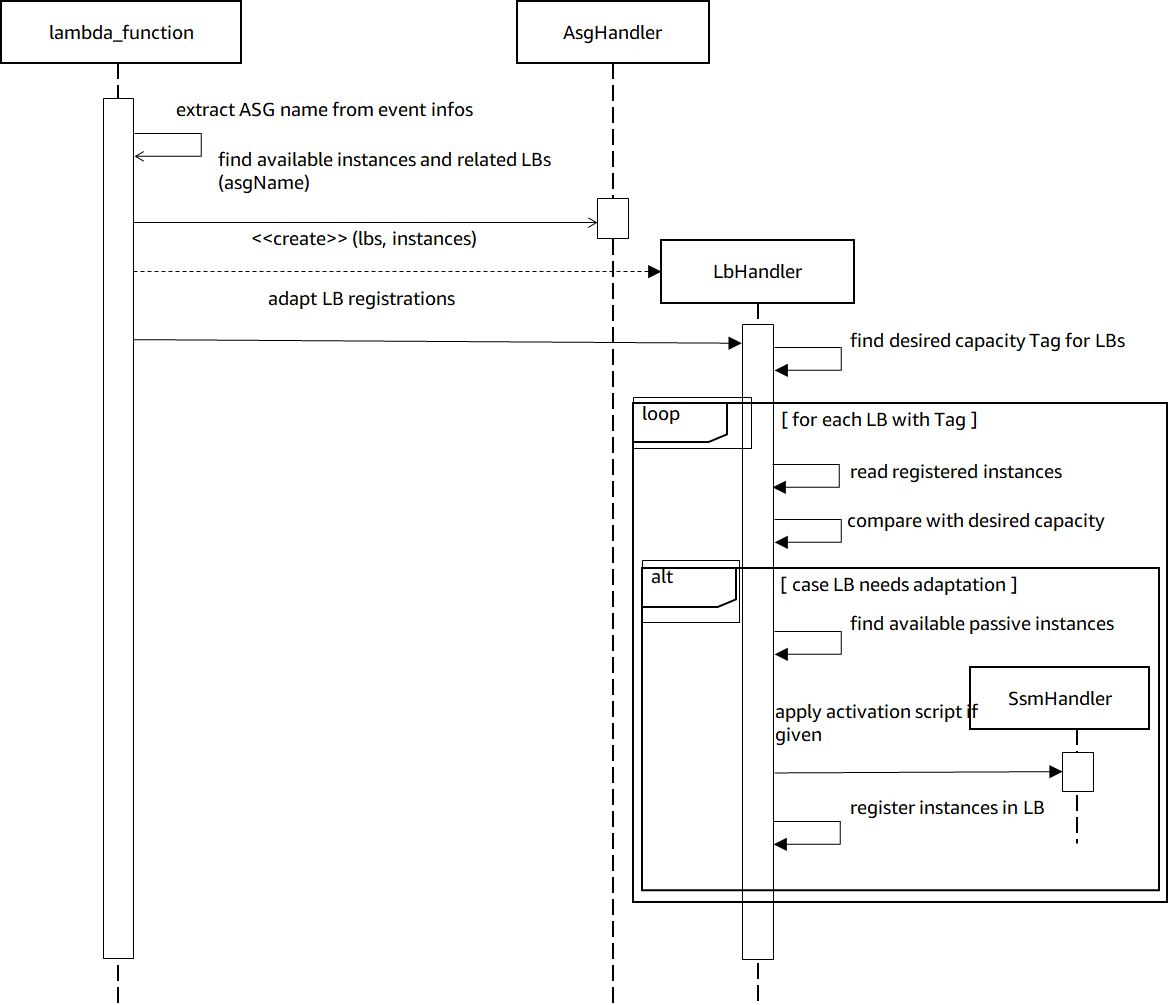
Figure 4 – Control flow logic.
The Lambda function must be granted access to communicate with other AWS services (via boto3 library, in this case). The same can be achieved by creating and assigning a resource-based access policy.
When multiple terminations and launches happen at the same time in the Auto Scaling Group, multiple Lambda functions may be triggered concurrently as a result. This situation is known as ‘race condition’ and to prevent potential race conditions, the implementation must be limited to maximum one concurrent Lambda execution.
If needed, this limitation could be addressed by adding a synchronization mechanism or enforcing order by using a message queue with FIFO logic available in Amazon Simple Queue Service (SQS).
Note that it’s highly unlikely that you’d need to warm up thousands of EC2 instances for the legacy applications. If that scenario occurs, there will be multiple Lambda functions triggered, which will lead to race condition. To avoid the racing condition of Lambda functions, our recommendation is to add SQS FIFO logic into the design.
To trigger the Lambda function, a CloudWatch rule must be created pointing to the Lambda function.
An appropriate rule event pattern could look like this:
Since there is no Auto Scaling Group directly addressed, the Lambda function will be invoked for any of these events for all groups in the AWS account.
Accordingly, the Lambda function must recognize the relevance of an event by finding the desired capacity ‘tag’ attached to a related Elastic Load Balancer. This may also be accomplished by adding only relevant Auto Scaling Group to that CloudWatch rule.
For the rail manufacturer working with IBM, the solution approach described in this post has helped to improve startup time of the Windows legacy application from 10 minutes to 3 minutes, thus achieving high availability.
IBM has avoided third-party discovery and registry services by leveraging other capabilities of AWS Systems Manager, such as Systems Manager Automation and Patch Manager.
Conclusion
In this post, we have discussed one of the challenges involved in migrating a customer’s legacy Windows application to AWS. Specifically, we discussed how singleton components cannot run redundantly and have long startup times, thus making high availability difficult for IT admins.
IBM Global Business Services was able to address this migration challenge by warming Amazon EC2 instances using AWS Lambda and AWS Systems Manager. They increased the HA of the Windows legacy application and startup time by 3x.
IBM also enabled the rail manufacturer to migrate similar Windows legacy applications to AWS so they could attain the benefits of business agility and operational efficiency.
IBM has a dedicated team of specialists available to help customers understand how on-premises Microsoft server workloads can be optimally run on AWS with significant cost savings and improving availability. Visit the IBM-AWS website to learn more or to engage with IBM.
.

.
IBM – AWS Partner Spotlight
IBM is an AWS Premier Consulting Partner that offers comprehensive service capabilities addressing both business and technology challenges that clients face today.
Contact IBM | Partner Overview
*Already worked with IBM? Rate the Partner
*To review an AWS Partner, you must be a customer that has worked with them directly on a project.