AWS Big Data Blog
Category: AWS Step Functions

Cross-account integration between SaaS platforms using Amazon AppFlow
Implementing an effective data sharing strategy that satisfies compliance and regulatory requirements is complex. Customers often need to share data between disparate software as a service (SaaS) platforms within their organization or across organizations. On many occasions, they need to apply business logic to the data received from the source SaaS platform before pushing it […]

Build event-driven data pipelines using AWS Controllers for Kubernetes and Amazon EMR on EKS
An event-driven architecture is a software design pattern in which decoupled applications can asynchronously publish and subscribe to events via an event broker. By promoting loose coupling between components of a system, an event-driven architecture leads to greater agility and can enable components in the system to scale independently and fail without impacting other services. […]

How BookMyShow saved 80% in costs by migrating to an AWS modern data architecture
This is a guest post co-authored by Mahesh Vandi Chalil, Chief Technology Officer of BookMyShow. BookMyShow (BMS), a leading entertainment company in India, provides an online ticketing platform for movies, plays, concerts, and sporting events. Selling up to 200 million tickets on an annual run rate basis (pre-COVID) to customers in India, Sri Lanka, Singapore, […]

Accelerate orchestration of an ELT process using AWS Step Functions and Amazon Redshift Data API
Extract, Load, and Transform (ELT) is a modern design strategy where raw data is first loaded into the data warehouse and then transformed with familiar Structured Query Language (SQL) semantics leveraging the power of massively parallel processing (MPP) architecture of the data warehouse. When you use an ELT pattern, you can also use your existing […]

Use an event-driven architecture to build a data mesh on AWS
In this post, we take the data mesh design discussed in Design a data mesh architecture using AWS Lake Formation and AWS Glue, and demonstrate how to initialize data domain accounts to enable managed sharing; we also go through how we can use an event-driven approach to automate processes between the central governance account and […]

Introducing runtime roles for Amazon EMR steps: Use IAM roles and AWS Lake Formation for access control with Amazon EMR
You can use the Amazon EMR Steps API to submit Apache Hive, Apache Spark, and others types of applications to an EMR cluster. You can invoke the Steps API using Apache Airflow, AWS Steps Functions, the AWS Command Line Interface (AWS CLI), all the AWS SDKs, and the AWS Management Console. Jobs submitted with the […]

Run a data processing job on Amazon EMR Serverless with AWS Step Functions
Update Feb 2023: AWS Step Functions adds direct integration for 35 services including Amazon EMR Serverless. In the current version of this blog, we are able to submit an EMR Serverless job by invoking the APIs directly from a Step Functions workflow. We are using the Lambda only for polling the status of the job […]
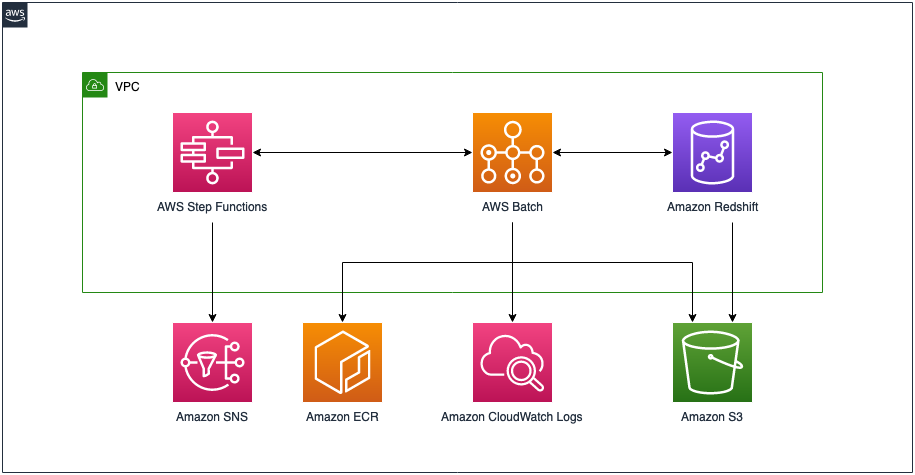
Develop an Amazon Redshift ETL serverless framework using RSQL, AWS Batch, and AWS Step Functions
Amazon Redshift RSQL is a command-line client for interacting with Amazon Redshift clusters and databases. You can connect to an Amazon Redshift cluster, describe database objects, query data, and view query results in various output formats. You can use enhanced control flow commands to replace existing extract, transform, load (ETL) and automation scripts. This post […]
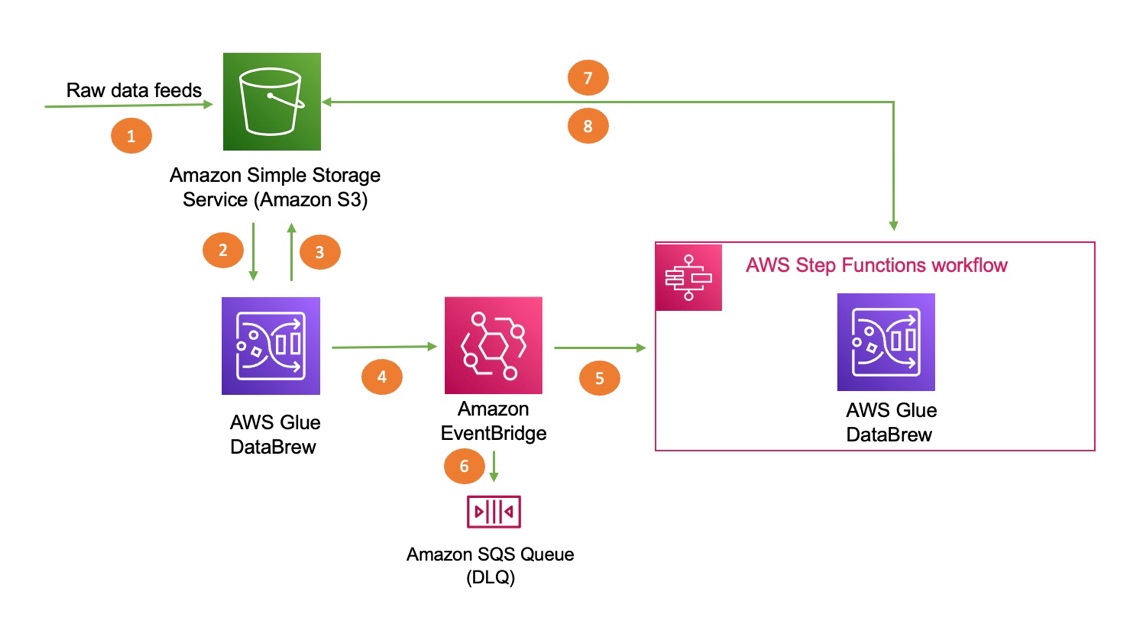
Trigger an AWS Glue DataBrew job based on an event generated from another DataBrew job
Organizations today have continuous incoming data, and analyzing this data in a timely fashion is becoming a common requirement for data analytics and machine learning (ML) use cases. As part of this, you need clean data in order to gain insights that can enable enterprises to get the most out of their data for business […]

Orchestrate big data jobs on on-premises clusters with AWS Step Functions
Customers with specific needs to run big data compute jobs on an on-premises infrastructure often require a scalable orchestration solution. For large-scale distributed compute clusters, the orchestration of jobs must be scalable to maximize their utilization, while at the same time remain resilient to any failures to prevent blocking the ever-growing influx of data and […]