AWS Big Data Blog
Category: Compute

How a blockchain startup built a prototype solution to solve the need of analytics for decentralized applications with AWS Data Lab
February 9, 2024: Amazon Kinesis Data Firehose has been renamed to Amazon Data Firehose. Read the AWS What’s New post to learn more. This post is co-written with Dr. Quan Hoang Nguyen, CTO at Fantom Foundation. Here at Fantom Foundation (Fantom), we have developed a high performance, highly scalable, and secure smart contract platform. It’s […]

How ZS created a multi-tenant self-service data orchestration platform using Amazon MWAA
This is post is co-authored by Manish Mehra, Anirudh Vohra, Sidrah Sayyad, and Abhishek I S (from ZS), and Parnab Basak (from AWS). The team at ZS collaborated closely with AWS to build a modern, cloud-native data orchestration platform. ZS is a management consulting and technology firm focused on transforming global healthcare and beyond. We […]

Build a pseudonymization service on AWS to protect sensitive data: Part 1
According to an article in MIT Sloan Management Review, 9 out of 10 companies believe their industry will be digitally disrupted. In order to fuel the digital disruption, companies are eager to gather as much data as possible. Given the importance of this new asset, lawmakers are keen to protect the privacy of individuals and […]
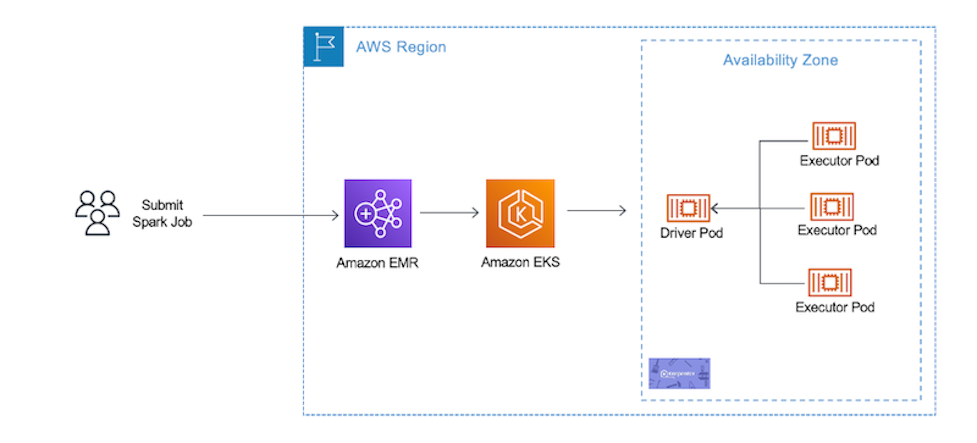
Design patterns to manage Amazon EMR on EKS workloads for Apache Spark
Amazon EMR on Amazon EKS enables you to submit Apache Spark jobs on demand on Amazon Elastic Kubernetes Service (Amazon EKS) without provisioning clusters. With EMR on EKS, you can consolidate analytical workloads with your other Kubernetes-based applications on the same Amazon EKS cluster to improve resource utilization and simplify infrastructure management. Kubernetes uses namespaces to provide isolation between […]
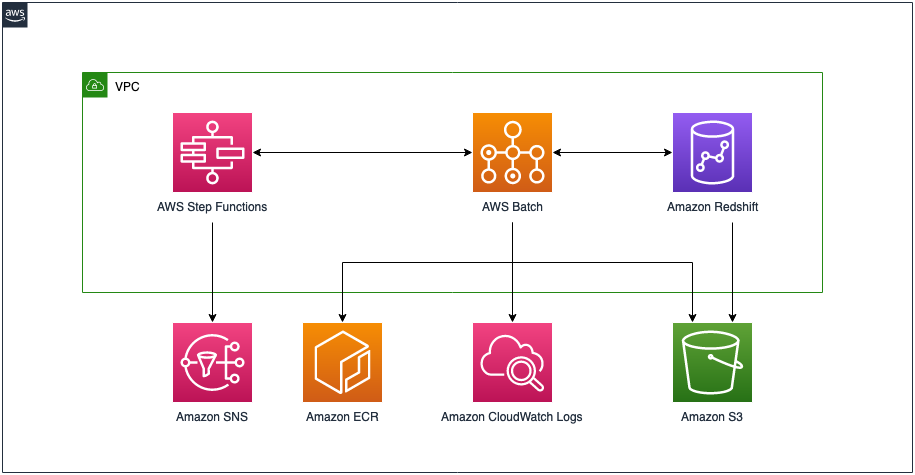
Develop an Amazon Redshift ETL serverless framework using RSQL, AWS Batch, and AWS Step Functions
Amazon Redshift RSQL is a command-line client for interacting with Amazon Redshift clusters and databases. You can connect to an Amazon Redshift cluster, describe database objects, query data, and view query results in various output formats. You can use enhanced control flow commands to replace existing extract, transform, load (ETL) and automation scripts. This post […]

How Epos Now modernized their data platform by building an end-to-end data lake with the AWS Data Lab
Epos Now provides point of sale and payment solutions to over 40,000 hospitality and retailers across 71 countries. Their mission is to help businesses of all sizes reach their full potential through the power of cloud technology, with solutions that are affordable, efficient, and accessible. Their solutions allow businesses to leverage actionable insights, manage their […]

Stream Amazon EMR on EKS logs to third-party providers like Splunk, Amazon OpenSearch Service, or other log aggregators
Spark jobs running on Amazon EMR on EKS generate logs that are very useful in identifying issues with Spark processes and also as a way to see Spark outputs. You can access these logs from a variety of sources. On the Amazon EMR virtual cluster console, you can access logs from the Spark History UI. […]

How SailPoint solved scaling issues by migrating legacy big data applications to Amazon EMR on Amazon EKS
This post is co-written with Richard Li from SailPoint. SailPoint Technologies is an identity security company based in Austin, TX. Its software as a service (SaaS) solutions support identity governance operations in regulated industries such as healthcare, government, and higher education. SailPoint distinguishes multiple aspects of identity as individual identity security services, including cloud governance, […]

Develop and test AWS Glue version 3.0 and 4.0 jobs locally using a Docker container
Mar 2025: This post was written for AWS Glue 3.0 and 4.0. For AWS Glue 5.0, visit Develop and test AWS Glue 5.0 jobs locally using a Docker container. Apr 2023: This post was reviewed and updated with enhanced support for Glue 4.0 Streaming jobs. Jan 2023: This post was reviewed and updated with enhanced […]

Improved performance with AWS Graviton2 instances on Amazon OpenSearch Service
Amazon OpenSearch Service is a fully managed service at AWS for OpenSearch. It’s an open-source search and analytics suite used for a broad set of use cases, like real-time application monitoring, log analytics, and website search. While running an OpenSearch Service domain, you can choose from a variety of instances for your primary nodes and […]