AWS Big Data Blog
Category: Amazon Simple Storage Service (S3)

How ANZ Institutional Division built a federated data platform to enable their domain teams to build data products to support business outcomes
ANZ Institutional Division has transformed its data management approach by implementing a federated data platform based on data mesh principles. This shift aims to unlock untapped data potential, improve operational efficiency, and increase agility. The new strategy empowers domain teams to create and manage their own data products, treating data as a valuable asset rather than a byproduct. This post explores how the shift to a data product mindset is being implemented, the challenges faced, and the early wins that are shaping the future of data management in the Institutional Division.

Stream real-time data into Apache Iceberg tables in Amazon S3 using Amazon Data Firehose
In this post, we discuss how you can send real-time data streams into Iceberg tables on Amazon S3 by using Amazon Data Firehose. Amazon Data Firehose simplifies the process of streaming data by allowing users to configure a delivery stream, select a data source, and set Iceberg tables as the destination. Once set up, the Firehose stream is ready to deliver data.

Modernize your legacy databases with AWS data lakes, Part 2: Build a data lake using AWS DMS data on Apache Iceberg
This is part two of a three-part series where we show how to build a data lake on AWS using a modern data architecture. This post shows how to load data from a legacy database (SQL Server) into a transactional data lake (Apache Iceberg) using AWS Glue. We show how to build data pipelines using AWS Glue jobs, optimize them for both cost and performance, and implement schema evolution to automate manual tasks. To review the first part of the series, where we load SQL Server data into Amazon Simple Storage Service (Amazon S3) using AWS Database Migration Service (AWS DMS), see Modernize your legacy databases with AWS data lakes, Part 1: Migrate SQL Server using AWS DMS.

Simplify data ingestion from Amazon S3 to Amazon Redshift using auto-copy
Amazon Redshift is a fast, scalable, secure, and fully managed cloud data warehouse that makes it simple and cost-effective to analyze your data using standard SQL and your existing business intelligence (BI) tools. Tens of thousands of customers today rely on Amazon Redshift to analyze exabytes of data and run complex analytical queries, making it […]

Apache HBase online migration to Amazon EMR
Apache HBase is an open source, non-relational distributed database developed as part of the Apache Software Foundation’s Hadoop project. HBase can run on Hadoop Distributed File System (HDFS) or Amazon Simple Storage Service (Amazon S3), and can host very large tables with billions of rows and millions of columns. The followings are some typical use […]

Take manual snapshots and restore in a different domain spanning across various Regions and accounts in Amazon OpenSearch Service
This post provides a detailed walkthrough about how to efficiently capture and manage manual snapshots in OpenSearch Service. It covers the essential steps for taking snapshots of your data, implementing safe transfer across different AWS Regions and accounts, and restoring them in a new domain. This guide is designed to help you maintain data integrity and continuity while navigating complex multi-Region and multi-account environments in OpenSearch Service.

Unleash deeper insights with Amazon Redshift data sharing for data lake tables
Amazon Redshift now enables the secure sharing of data lake tables—also known as external tables or Amazon Redshift Spectrum tables—that are managed in the AWS Glue Data Catalog, as well as Redshift views referencing those data lake tables. By using granular access controls, data sharing in Amazon Redshift helps data owners maintain tight governance over who can access the shared information. In this post, we explore powerful use cases that demonstrate how you can enhance cross-team and cross-organizational collaboration, reduce overhead, and unlock new insights by using this innovative data sharing functionality.

Accelerate Amazon Redshift Data Lake queries with AWS Glue Data Catalog Column Statistics
Over the last year, Amazon Redshift added several performance optimizations for data lake queries across multiple areas of query engine such as rewrite, planning, scan execution and consuming AWS Glue Data Catalog column statistics. In this post, we highlight the performance improvements we observed using industry standard TPC-DS benchmarks. Overall execution time of TPC-DS 3 TB benchmark improved by 3x. Some of the queries in our benchmark experienced up to 12x speed up.

The AWS Glue Data Catalog now supports storage optimization of Apache Iceberg tables
The AWS Glue Data Catalog now enhances managed table optimization of Apache Iceberg tables by automatically removing data files that are no longer needed. Along with the Glue Data Catalog’s automated compaction feature, these storage optimizations can help you reduce metadata overhead, control storage costs, and improve query performance. Iceberg creates a new version called […]
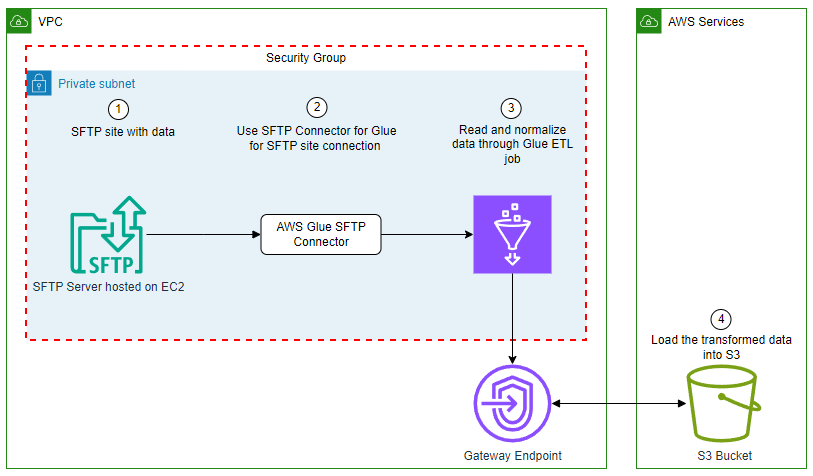
Use AWS Glue to streamline SFTP data processing
In this blog post, we explore how to use the SFTP Connector for AWS Glue from the AWS Marketplace to efficiently process data from Secure File Transfer Protocol (SFTP) servers into Amazon Simple Storage Service (Amazon S3), further empowering your data analytics and insights.