AWS Big Data Blog
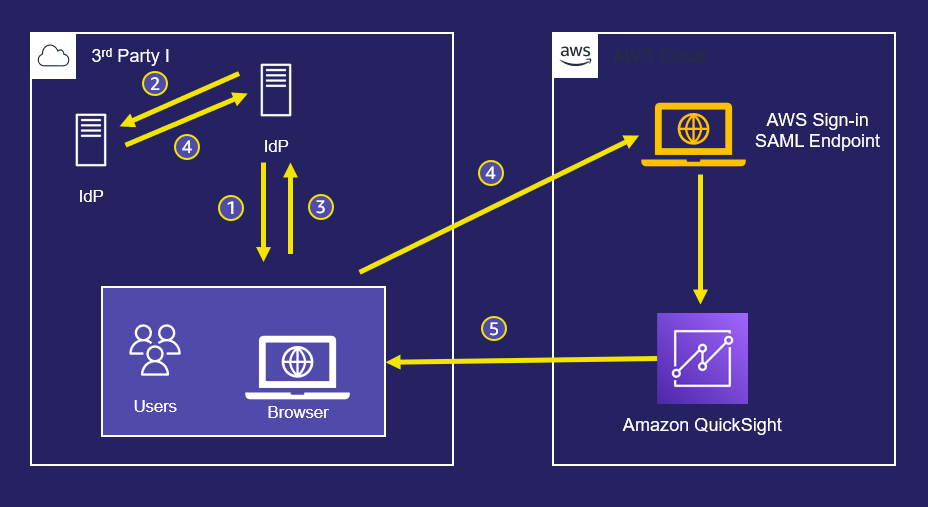
Enable Amazon Quick Sight federation with Google Workspace
October 2025: This post was reviewed for accuracy. Amazon Quick Sight is now an AWS IAM Identity Center enabled application. This capability allows administrators who subscribe to Quick Sight to use IAM Identity Center to enable their users to log in with Google Workspace and other external identity providers. For more information, see Simplify business intelligence […]

Tips and tricks for high-performant dashboards in Amazon QuickSight
August 2025: This post was reviewed and updated for accuracy. Amazon QuickSight is cloud-native business intelligence (BI) service. QuickSight automatically optimizes queries and execution to help dashboards load quickly, but you can make your dashboard loads even faster and make sure you’re getting the best possible performance by following the tips and tricks outlined in […]

Analyze Amazon Ion datasets using Amazon Athena
Amazon Athena is an interactive query service that makes it easy to analyze data in Amazon Simple Storage Service (Amazon S3) using standard SQL. Athena is serverless, so there is no infrastructure to manage, and you pay only for the queries that you run. Amazon Ion is a richly typed, self-describing, hierarchical data serialization format […]

Use Amazon Redshift RA3 with managed storage in your modern data architecture
Amazon Redshift is a fully managed, petabyte-scale data warehouse service in the cloud. You can start with just a few hundred gigabytes of data and scale to a petabyte or more. This enables you to use your data to acquire new insights for your business and customers. Over the years, Amazon Redshift has evolved a […]
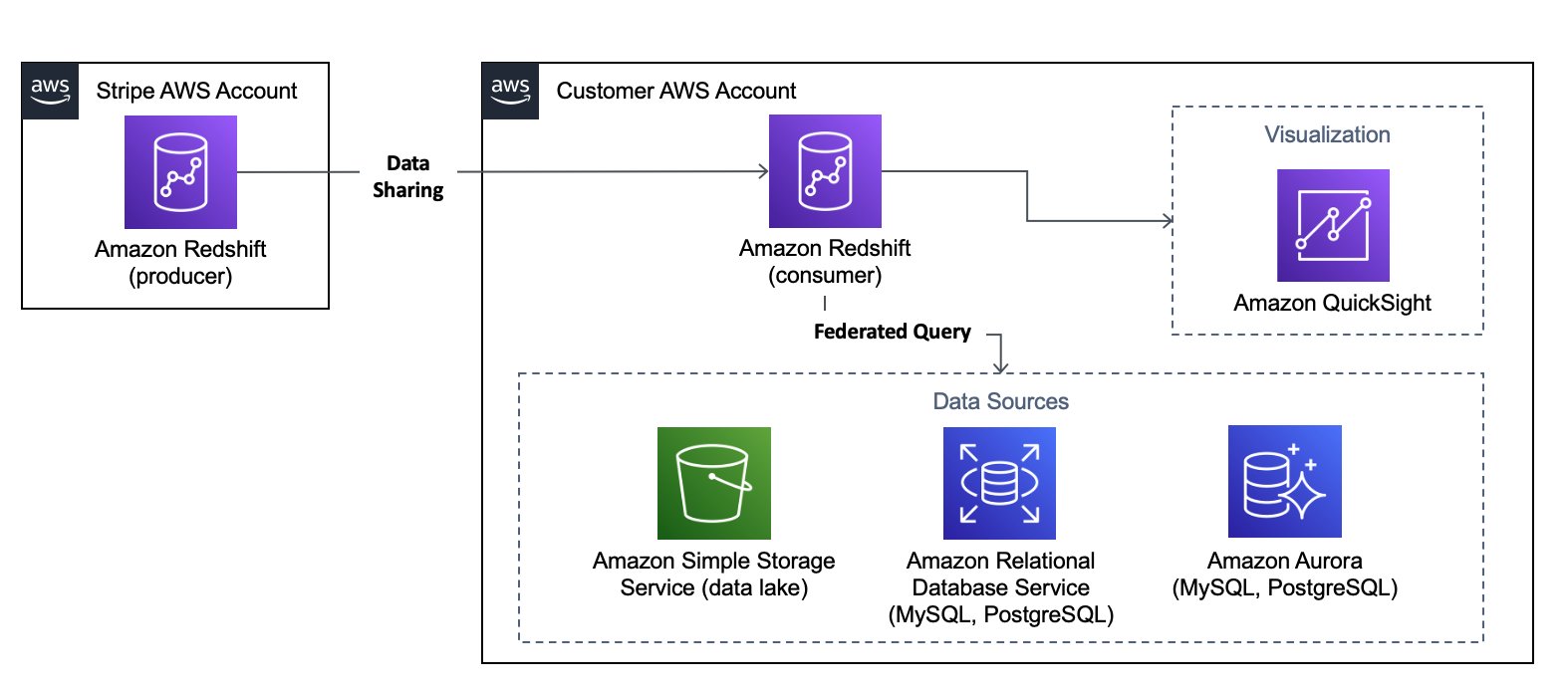
Ingest Stripe data in a fast and reliable way using Stripe Data Pipeline for Amazon Redshift
Enterprises typically host a myriad of business applications for varying data needs. As companies grow, so does the demand for insights from a complete set of business data. Having data from various applications that store data in disparate silos can delay the decision-making process. However, building and maintaining an API integration or a third-party extract, […]

Introducing new dashboard experience on Amazon QuickSight
This post was last updated August 2022, to include new experiences such as Analysis and Embedding. Amazon QuickSight launches the new look and feel for your dashboards. In this post, we will walk through the changes and improvements introduced with the new look. The new dashboard experience includes the following improvements: Simplified toolbar Discoverable visual […]

Use a linear learner algorithm in Amazon Redshift ML to solve regression and classification problems
July 2024: This post was reviewed and updated for accuracy. Amazon Redshift is a fast, petabyte-scale cloud data warehouse delivering the best price–performance. Tens of thousands of customers use Amazon Redshift to process exabytes of data every day to power their analytics workloads. Amazon Redshift ML, powered by Amazon SageMaker, makes it easy for SQL […]
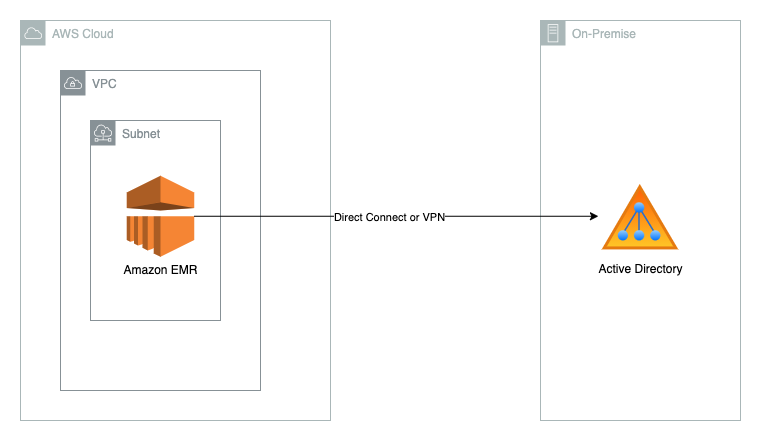
Deep dive into Amazon EMR Kerberos authentication integrated with Microsoft Active Directory
Many of our customers that use Amazon EMR as their big data platform need to integrate with their existing Microsoft Active Directory (AD) for user authentication. This integration requires the Kerberos daemon of Amazon EMR to establish a trusted connection with an AD domain, which involves a lot of moving pieces and can be difficult […]

Federate single sign-on access to Amazon Redshift query editor v2 with Okta
Amazon Redshift query editor v2 is a web-based SQL client application that you can use to author and run queries on your Amazon Redshift data warehouse. You can visualize query results with charts and collaborate by sharing queries with members of your team. You can use query editor v2 to create databases, schemas, tables, and […]
Federate access to Amazon Redshift query editor V2 with Active Directory Federation Services (AD FS): Part 3
In the first post of this series, Federate access to your Amazon Redshift cluster with Active Directory Federation Services (AD FS): Part 1, you set up Microsoft Active Directory Federation Services (AD FS) and Security Assertion Markup Language (SAML) based authentication and tested the SAML federation using a web browser. In Part 2, you learned […]