AWS Big Data Blog
Tag: Amazon Athena

How MEDHOST’s cardiac risk prediction successfully leveraged AWS analytic services
February 9, 2024: Amazon Kinesis Data Firehose has been renamed to Amazon Data Firehose. Read the AWS What’s New post to learn more. MEDHOST has been providing products and services to healthcare facilities of all types and sizes for over 35 years. Today, more than 1,000 healthcare facilities are partnering with MEDHOST and enhancing their […]
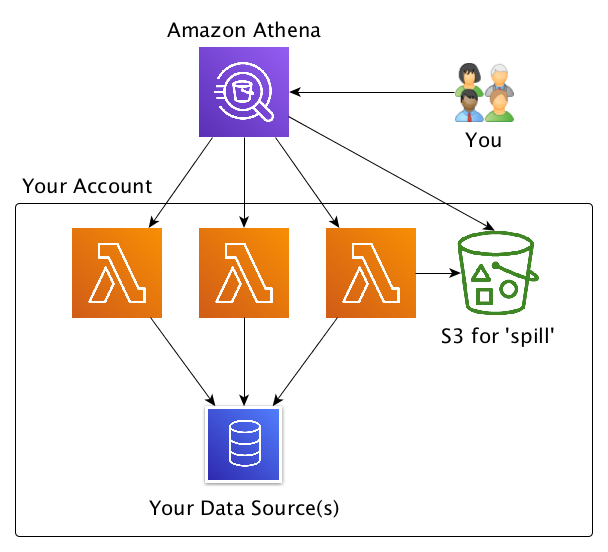
Configure and optimize performance of Amazon Athena federation with Amazon Redshift
This post provides guidance on how to configure Amazon Athena federation with AWS Lambda and Amazon Redshift, while addressing performance considerations to ensure proper use.

Enhancing customer safety by leveraging the scalable, secure, and cost-optimized Toyota Connected Data Lake
February 9, 2024: Amazon Kinesis Data Firehose has been renamed to Amazon Data Firehose. Read the AWS What’s New post to learn more. Toyota Motor Corporation (TMC), a global automotive manufacturer, has made “connected cars” a core priority as part of its broader transformation from an auto company to a mobility company. In recent years, […]

Optimize Python ETL by extending Pandas with AWS Data Wrangler
April 2024: This post was reviewed for accuracy. Developing extract, transform, and load (ETL) data pipelines is one of the most time-consuming steps to keep data lakes, data warehouses, and databases up to date and ready to provide business insights. You can categorize these pipelines into distributed and non-distributed, and the choice of one or […]
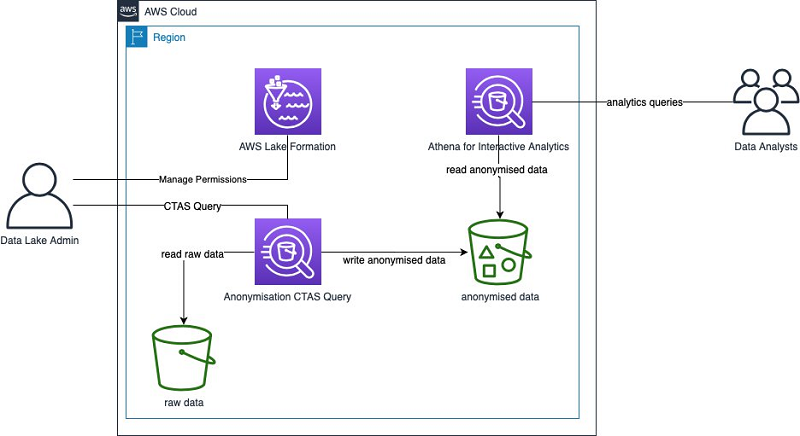
Anonymize and manage data in your data lake with Amazon Athena and AWS Lake Formation
Most organizations have to comply with regulations when dealing with their customer data. For that reason, datasets that contain personally identifiable information (PII) is often anonymized. A common example of PII can be tables and columns that contain personal information about an individual (such as first name and last name) or tables with columns that, if joined with another table, can trace back to an individual. You can use AWS Analytics services to anonymize your datasets. In this post, I describe how to use Amazon Athena to anonymize a dataset. You can then use AWS Lake Formation to provide the right access to the right personas.
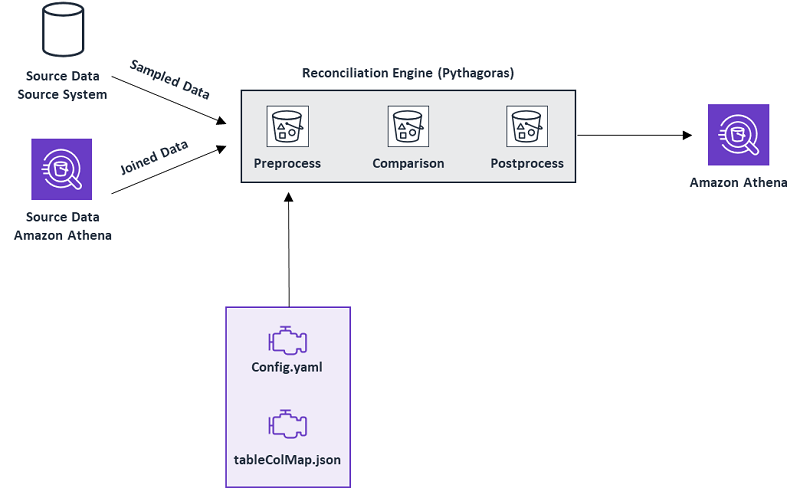
Build a distributed big data reconciliation engine using Amazon EMR and Amazon Athena
This is a guest post by Sara Miller, Head of Data Management and Data Lake, Direct Energy; and Zhouyi Liu, Senior AWS Developer, Direct Energy. Enterprise companies like Direct Energy migrate on-premises data warehouses and services to AWS to achieve fully manageable digital transformation of their organization. Freedom from traditional data warehouse constraints frees up […]

Enforce column-level authorization with Amazon QuickSight and AWS Lake Formation
Amazon QuickSight is a fast, cloud-powered, business intelligence service that makes it easy to deliver insights and integrates seamlessly with your data lake built on Amazon Simple Storage Service (Amazon S3). QuickSight users in your organization often need access to only a subset of columns for compliance and security reasons. Without having a proper solution […]
How Wind Mobility built a serverless data architecture
We parse through millions of scooter and user events generated daily (over 300 events per second) to extract actionable insight. We selected AWS Glue to perform this task. Our primary ETL job reads the newly added raw event data from Amazon S3, processes it using Apache Spark, and writes the results to our Amazon Redshift data warehouse. AWS Glue plays a critical role in our ability to scale on demand. After careful evaluation and testing, we concluded that AWS Glue ETL jobs meet all our needs and free us from procuring and managing infrastructure.

Extend your Amazon Redshift Data Warehouse to your Data Lake
Amazon Redshift is a fast, fully managed, cloud-native data warehouse that makes it simple and cost-effective to analyze all your data using standard SQL and your existing business intelligence tools. Many companies today are using Amazon Redshift to analyze data and perform various transformations on the data. However, as data continues to grow and become […]

Analyzing Google Analytics data with Amazon AppFlow and Amazon Athena
This post demonstrates how you can transfer Google Analytics data to Amazon S3 using Amazon AppFlow, and analyze it with Amazon Athena. You no longer need to build your own application to extract data from Google Analytics and other SaaS applications. Amazon AppFlow enables you to develop a fully automated data transfer and transformation workflow and an integrated query environment in one place.