AWS Big Data Blog
Tag: AWS Glue
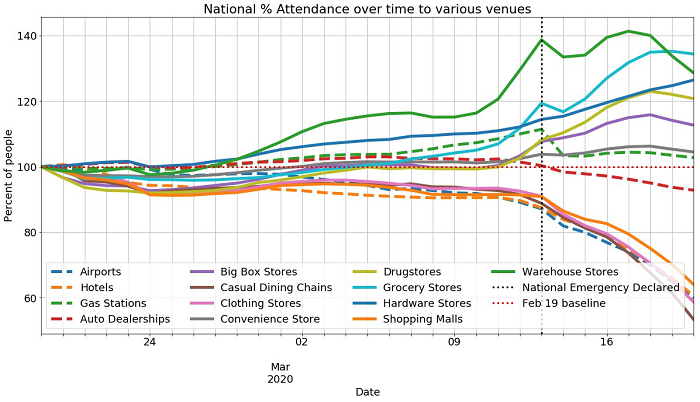
Exploring the public AWS COVID-19 data lake
This post walks you through accessing the AWS COVID-19 data lake through the AWS Glue Data Catalog via Amazon SageMaker or Jupyter and using the open-source AWS Data Wrangler library. AWS Data Wrangler is an open-source Python package that extends the power of Pandas library to AWS and connects DataFrames and AWS data-related services (such as Amazon Redshift, Amazon S3, AWS Glue, Amazon Athena, and Amazon EMR). For more information about what you can build by using this data lake, see the associated public Jupyter notebook on GitHub.

Query, visualize, and forecast TruFactor web session intelligence with AWS Data Exchange
This post showcases TruFactor Intelligence-as-a-Service data on AWS Data Exchange. TruFactor’s anonymization platform and proprietary AI ingests, filters, and transforms more than 85 billion high-quality raw signals daily from wireless carriers, OEMs, and mobile apps into a unified phygital consumer graph across physical and digital dimensions. TruFactor intelligence is application-ready for use within any AWS analytics or ML service to power your models and applications running on AWS, with no additional processing required.

Build a cloud-native network performance analytics solution on AWS for wireless service providers
February 9, 2024: Amazon Kinesis Data Firehose has been renamed to Amazon Data Firehose. Read the AWS What’s New post to learn more. This post demonstrates a serverless, cloud-based approach to building a network performance analytics solution using AWS services that can provide flexibility and performance while keeping costs under control with pay-per-use AWS services. […]

A public data lake for analysis of COVID-19 data
April 2024: This post was reviewed for accuracy. As the COVID-19 pandemic continues to threaten and take lives around the world, we must work together across organizations and scientific disciplines to fight this disease. Innumerable healthcare workers, medical researchers, scientists, and public health officials are already on the front lines caring for patients, searching for […]

Load data incrementally and optimized Parquet writer with AWS Glue
October 2022: This post was reviewed for accuracy. AWS Glue provides a serverless environment to prepare (extract and transform) and load large amounts of datasets from a variety of sources for analytics and data processing with Apache Spark ETL jobs. The first post of the series, Best practices to scale Apache Spark jobs and partition […]

Analyze your Amazon S3 spend using AWS Glue and Amazon Redshift
The AWS Cost & Usage Report (CUR) tracks your AWS usage and provides estimated charges associated with that usage. You can configure this report to present the data at hourly or daily intervals, and it is updated at least one time per day until it is finalized at the end of the billing period. The […]
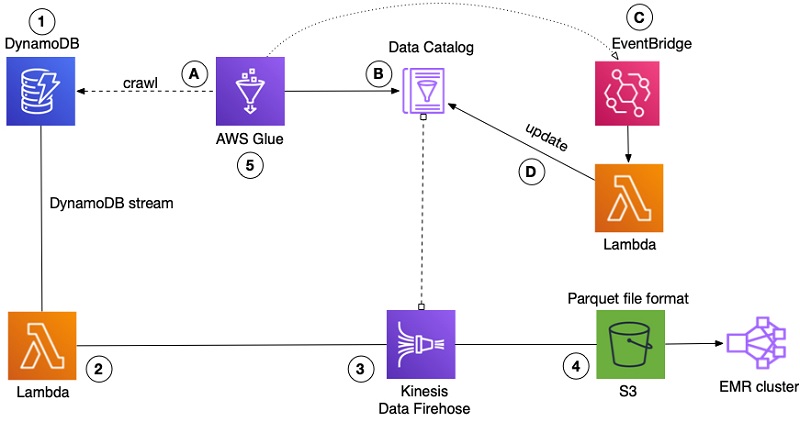
How FactSet automated exporting data from Amazon DynamoDB to Amazon S3 Parquet to build a data analytics platform
February 9, 2024: Amazon Kinesis Data Firehose has been renamed to Amazon Data Firehose. Read the AWS What’s New post to learn more. This is a guest post by Arvind Godbole, Lead Software Engineer with FactSet and Tarik Makota, AWS Principal Solutions Architect. In their own words “FactSet creates flexible, open data and software solutions […]

Best practices to scale Apache Spark jobs and partition data with AWS Glue
The first post of this series discusses two key AWS Glue capabilities to manage the scaling of data processing jobs. The first allows you to horizontally scale out Apache Spark applications for large splittable datasets. The second allows you to vertically scale up memory-intensive Apache Spark applications with the help of new AWS Glue worker types. The post also shows how to use AWS Glue to scale Apache Spark applications with a large number of small files commonly ingested from streaming applications using Amazon Kinesis Data Firehose. Finally, the post shows how AWS Glue jobs can use the partitioning structure for large datasets in Amazon S3 to provide faster execution times for Apache Spark applications.

Orchestrate Amazon Redshift-Based ETL workflows with AWS Step Functions and AWS Glue
In this post, I show how to use AWS Step Functions and AWS Glue Python Shell to orchestrate tasks for those Amazon Redshift-based ETL workflows in a completely serverless fashion. AWS Glue Python Shell is a Python runtime environment for running small to medium-sized ETL tasks, such as submitting SQL queries and waiting for a response. Step Functions lets you coordinate multiple AWS services into workflows so you can easily run and monitor a series of ETL tasks. Both AWS Glue Python Shell and Step Functions are serverless, allowing you to automatically run and scale them in response to events you define, rather than requiring you to provision, scale, and manage servers.
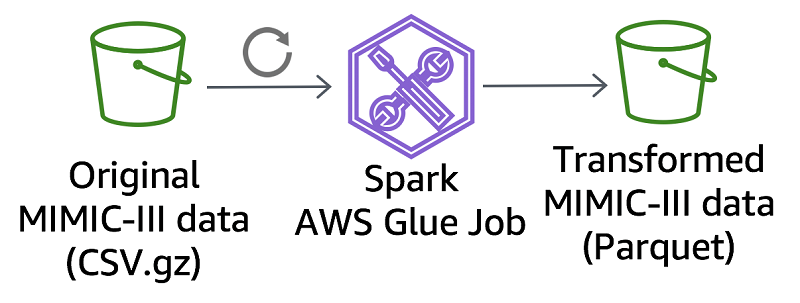
Perform biomedical informatics without a database using MIMIC-III data and Amazon Athena
This post describes how to make the MIMIC-III dataset available in Athena and provide automated access to an analysis environment for MIMIC-III on AWS. We also compare a MIMIC-III reference bioinformatics study using a traditional database to that same study using Athena.