Artificial Intelligence
How Amp on Amazon used data to increase customer engagement, Part 1: Building a data analytics platform
Amp, the new live radio app from Amazon, is a reinvention of radio featuring human-curated live audio shows. It’s designed to provide a seamless customer experience to listeners and creators by debuting interactive live audio shows from your favorite artists, radio DJs, podcasters, and friends.
However, as a new product in a new space for Amazon, Amp needed more relevant data to inform their decision-making process. Amp wanted a scalable data and analytics platform to enable easy access to data and perform machine leaning (ML) experiments for live audio transcription, content moderation, feature engineering, and a personal show recommendation service, and to inspect or measure business KPIs and metrics.
This post is the first in a two-part series. Part 1 shows how data was collected and processed using the data and analytics platform, and Part 2 shows how the data was used to create show recommendations using Amazon SageMaker, a fully managed ML service. The personalized show recommendation list service has shown a 3% boost to customer engagement metrics tracked (such as liking a show, following a creator, or enabling upcoming show notifications) since its launch in May 2022.
Solution overview
The data sources for Amp can be broadly categorized as either streaming (near-real time) or batch (point in time). The source data is emitted from Amp-owned systems or other Amazon systems. The two different data types are as follows:
- Streaming data – This type of data mainly consists of follows, notifications (regarding users’ friends, favorite creators, or shows), activity updates, live show interactions (call-ins, co-hosts, polls, in-app chat), real-time updates on live show activities (live listen count, likes), live audio playback metrics, and other clickstream metrics from the Amp application. Amp stakeholders require this data to power ML processes or predictive models, content moderation tools, and product and program dashboards (for example, trending shows). Streaming data enables Amp customers to conduct and measure experimentation.
- Batch data – This data mainly consists of catalog data, show or creator metadata, and user profile data. Batch data enables more point-in-time reporting and analytics vs. real-time.
The following diagram illustrates the high-level architecture.

The Amp data and analytics platform can be broken down into three high-level systems:
- Streaming data ingestion, stream processing and transformation, and stream storage
- Batch data ingestion, batch processing and transformation, and batch storage
- Business intelligence (BI) and analytics
In the following sections, we discuss each component in more detail.
Streaming data ingestion, processing, transformation, and storage
Amp created a serverless streaming ingestion pipeline capable of tapping into data from sources without the need for infrastructure management, as shown in the following diagram.
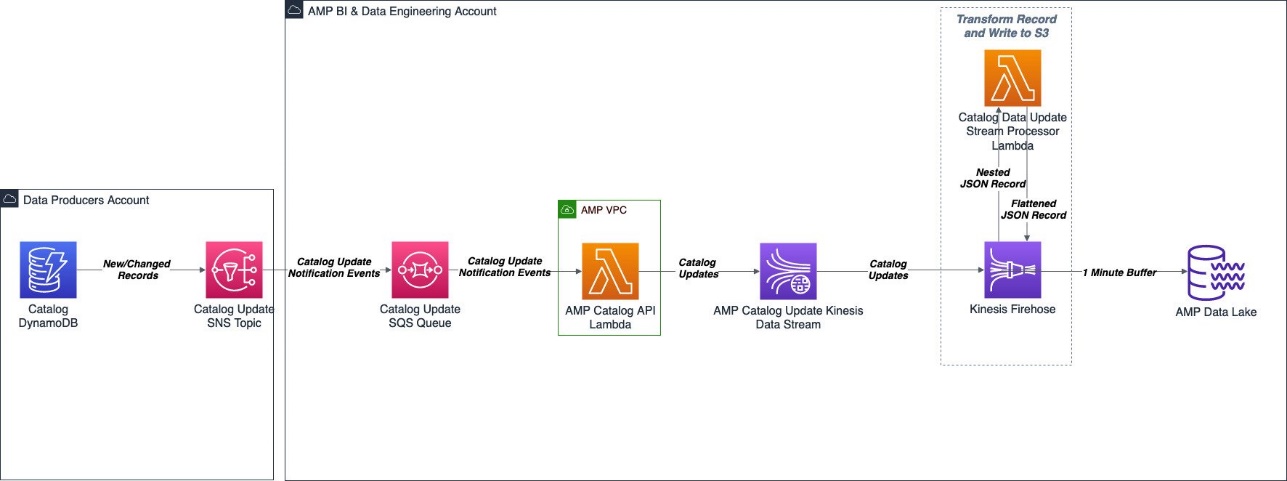
The pipeline was able to ingest the Amp show catalog data (what shows are available on Amp) and pass it to the data lake for two different use cases: one for near-real-time analytics, and one for batch analytics.
As part of the ingestion pipeline, the Amp team has an Amazon Simple Queue Service (Amazon SQS) queue that receives messages from an upstream Amazon Simple Notification Service (Amazon SNS) topic that contains information on changes to shows in the catalog. These changes could be the addition of new shows or adjustments to existing ones that have been scheduled.
When the message is received by the SQS queue, it triggers the AWS Lambda function to make an API call to the Amp catalog service. The Lambda function retrieves the desired show metadata, filters the metadata, and then sends the output metadata to Amazon Kinesis Data Streams. Amazon Kinesis Data Firehose receives the records from the data stream. Kinesis Data Firehose then invokes a secondary Lambda function to perform a data transformation that flattens the JSON records received and writes the transformed records to an Amazon Simple Storage Service (Amazon S3) data lake for consumption by Amp stakeholders.
Kinesis Data Firehose enabled buffering and writing data to Amazon S3 every 60 seconds. This helped Amp teams make near-real-time programming decisions that impacted external customers.
The streaming ingestion pipeline supported the following objectives: performance, availability, scalability, and flexibility to send data to multiple downstream applications or services:
- Kinesis Data Streams handles streaming data ingestion when necessary. Kinesis Data Streams supported these objectives by enabling the Amp team to quickly ingest data for analytics with minimal operational load. As a fully managed service, it reduced operational overhead, and Amp was able to scale with the product needs.
- Lambda enabled the team to create lightweight functions to run API calls and perform data transformations.
- Because Kinesis Data Firehose is a managed service, it was able to handle all the scaling, sharding, and monitoring needs of the streaming data without any additional overheard for the team.
Batch data ingestion, processing, transformation, and storage
Amp created a transient batch (point in time) ingestion pipeline capable of data ingestion, processing and transformation, and storage, as shown in the following diagram.
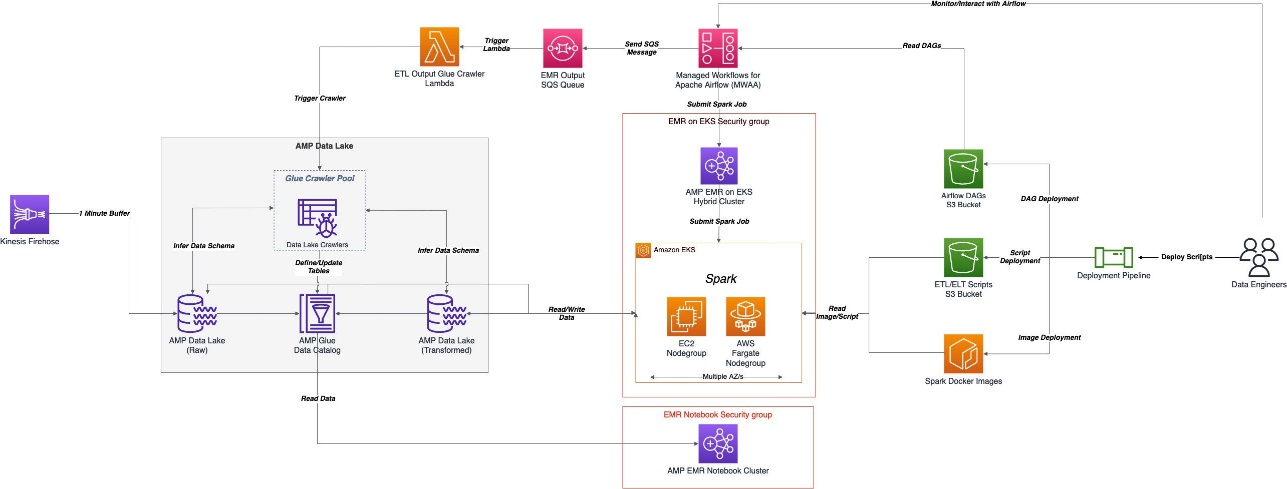
A transient extract, transform, and load (ETL) and extract, load, and transform (ELT) job approach was implemented because of the batch nature of these workloads and unknown data volumes. As a part of the workflow automation, Amazon SQS was used to trigger a Lambda function. The Lambda function then activated the AWS Glue crawler to infer the schema and data types. The crawler wrote the schema metadata to the AWS Glue Data Catalog, providing a unified metadata store for data sharing.
The ETL and ELT jobs were required to run on either a set schedule or event-driven workflow. To handle these needs, Amp used Amazon Managed Workflows for Apache Airflow (Amazon MWAA). Apache Airflow is an open-source Python-based workflow management platform. Amazon MWAA is a fully managed service that automatically handles scaling. It provides sequencing, error handling, retry logic, and state. With Amazon MWAA, Amp was able to take advantage of the the benefits of Airflow for job orchestration while not having to manage or maintain dedicated Airflow servers. Additionally, by using Amazon MWAA, Amp was able to create a code repository and workflow pipeline stored in Amazon S3 that Amazon MWAA could access. The pipeline allowed Amp data engineers to easily deploy Airflow DAGs or PySpark scripts across multiple environments.
Amp used Amazon EMR on Amazon Elastic Kubernetes Service (Amazon EKS) to configure and manage containers for their data processing and transformation jobs. Due to the unique nature of the Amp service, the initial expected data volumes that would be processed were relatively unknown. To provide flexibility as the service evolved, the team decided to go with Amazon EMR on EKS to eliminate any unnecessary operational overheard required to bootstrap and scale Amazon EMR for data processing. This approach allowed them to run transient hybrid EMR clusters backed by a mix of AWS Fargate and Amazon Elastic Compute Cloud (Amazon EC2) nodes, where all system tasks and workloads were offloaded to Fargate, while Amazon EC2 handled all the Apache Spark processing and transformation. This provided the flexibility to have a cluster with one node running, while the Amazon EKS auto scaler dynamically instantiated and bootstrapped any additional EC2 nodes that were required for the job. When the job was complete, they were automatically deleted by the cluster auto scaler. This pattern eliminated the need for the team to manage any of the cluster bootstrap actions or scaling required to respond to evolving workloads.
Amazon S3 was used as the central data lake, and data was stored in Apache Parquet (Parquet) format. Parquet is a columnar format, which speeds up data retrieval and provides efficient data compression. Amazon S3 provided the flexibility, scalability, and security needs for Amp. With Amazon S3, the Amp team was able to centralize data storage in one location and federate access to the data virtually across any service or tool within or outside of AWS. The data lake was split into two S3 buckets: one for raw data ingestion and one for transformed data output. Amazon EMR performed the transformation from raw data to transformed data. With Amazon S3 as the central data lake, Amp was able to securely expose and share the data with other teams across Amp and Amazon.
To simplify data definition, table access provisioning, and the addition and removal of tables, they used AWS Glue crawlers and the AWS Glue Data Catalog. Because Amp is a new service and constantly evolving, the team needed a way to easily define, access, and manage the tables in the data lake. The crawlers handled data definition (including schema changes) and the addition and removal of tables, while the Data Catalog served as a unified metadata store.
Business intelligence and analytics
The following diagram illustrates the architecture for the BI and analytics component.
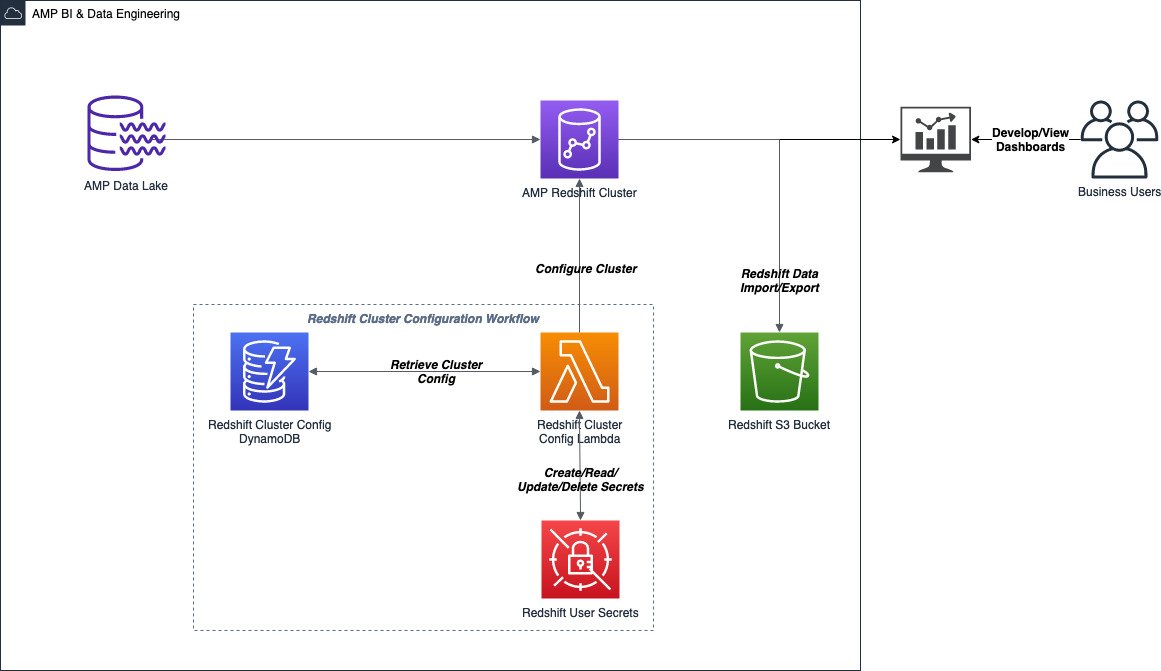
Amp chose to store the data in the S3 data lake, and not in the data warehouse. This enabled them to access it in a unified manner through the AWS Glue Data Catalog and provided greater flexibility for data consumers. This resulted in faster data access across a variety of services or tools. With data being stored in Amazon S3, it also reduced data warehouse infrastructure costs, because the costs are a function of the compute type and the amount of data stored.
The Amazon Redshift RA3 node type was used as the compute layer to enable stakeholders to query data stored in Amazon S3. Amazon Redshift RA3 nodes decouple storage and compute, and are designed for an access pattern through the AWS Glue Data Catalog. RA3 nodes introduce Amazon Redshift Managed Storage, which is Amazon S3 backed. The combination of these features enabled Amp to right-size the clusters and provide better query performance for their customers while minimizing costs.
Amazon Redshift configuration was automated using a Lambda function, which connected to a given cluster and ran parameterized SQL statements. The SQL statements contained the logic to deploy schemas, user groups, and users, while AWS Secrets Manager was used to automatically generate, store, and rotate Amazon Redshift user passwords. The underlying configuration variables were stored in Amazon DynamoDB. The Lambda function retrieved the variables and requested temporary Amazon Redshift credentials to perform the configuration. This process enabled the Amp team to set up Amazon Redshift clusters in a consistent manner.
Business outcomes
Amp was able to achieve the following business outcomes:
- Business reporting – Standard reporting required to run the business, such as daily flash reports, aggregated business review mechanisms, or project and program updates.
- Product reporting – Specific reporting required to enable the inspection or measurement of key product KPIs and Metrics. This included visual reports through dashboards such as marketing promotion effectiveness, app engagement metrics, and trending shows.
- ML experimentation – Enabled downstream Amazon teams to use this data to support experimentation or generate predictions and recommendations. For example, ML experimentations like a personalized show recommendation list, show categorization, and content moderation helped with Amp’s user retention.
Key benefits
By implementing a scalable, cost-efficient architecture, Amp was able to achieve the following:
- Limited operational complexity – They built a flexible system that used AWS managed services wherever possible.
- Use the languages of data – Amp was able to support the two most common data manipulation languages, Python and SQL, to perform platform operations, conduct ML experiments, and generate analytics. With this support, the developers with Amp were able to use languages they were familiar with.
- Enable experimentation and measurement – Amp allowed developers to quickly generate the datasets needed to conduct experiments and measure the results. This helps in optimizing the Amp customer experience.
- Build to learn but design to scale – Amp is a new product that is finding its market fit, and was able to focus their initial energy on building just enough features to get feedback. This enabled them to pivot toward the right product market fit with each launch. They were able to build incrementally, but plan for the long term.
Conclusion
In this post, we saw how Amp created their data analytics platform using user behavioral data from streaming and batch data sources. The key factors that drove the implementation were the need to provide a flexible, scalable, cost-efficient, and effort-efficient data analytics platform. Design choices were made evaluating various AWS services.
Part 2 of this series shows how we used this data and built out the personalized show recommendation list using SageMaker.
As next steps, we recommend doing a deep dive into each stage of your data pipeline system and making design choices that would be cost-effective and scalable for your needs. For more information, you can also check out other customer use cases in the AWS Analytics Blog.
If you have feedback about this post, submit it in the comments section.
About the authors
 Tulip Gupta is a Solutions Architect at Amazon Web Services. She works with Amazon to design, build, and deploy technology solutions on AWS. She assists customers in adopting best practices while deploying solution in AWS, and is a Analytics and ML enthusiast. In her spare time, she enjoys swimming, hiking and playing board games.
Tulip Gupta is a Solutions Architect at Amazon Web Services. She works with Amazon to design, build, and deploy technology solutions on AWS. She assists customers in adopting best practices while deploying solution in AWS, and is a Analytics and ML enthusiast. In her spare time, she enjoys swimming, hiking and playing board games.
 David Kuo is a Solutions Architect at Amazon Web Services. He works with AWS customers to design, build and deploy technology solutions on AWS. He works with Media and Entertainment customers and has interests in machine learning technologies. In his spare time, he wonders what he should do with his spare time.
David Kuo is a Solutions Architect at Amazon Web Services. He works with AWS customers to design, build and deploy technology solutions on AWS. He works with Media and Entertainment customers and has interests in machine learning technologies. In his spare time, he wonders what he should do with his spare time.
 Manolya McCormick is a Sr Software Development Engineer for Amp on Amazon. She designs and builds distributed systems using AWS to serve customer facing applications. She enjoys reading and cooking new recipes at her spare time.
Manolya McCormick is a Sr Software Development Engineer for Amp on Amazon. She designs and builds distributed systems using AWS to serve customer facing applications. She enjoys reading and cooking new recipes at her spare time.
 Jeff Christophersen is a Sr. Data Engineer for Amp on Amazon. He works to design, build, and deploy Big Data solutions on AWS that drive actionable insights. He assists internal teams in adopting scalable and automated solutions, and is a Analytics and Big Data enthusiast. In his spare time, when he is not on a pair of skis you can find him on his mountain bike.
Jeff Christophersen is a Sr. Data Engineer for Amp on Amazon. He works to design, build, and deploy Big Data solutions on AWS that drive actionable insights. He assists internal teams in adopting scalable and automated solutions, and is a Analytics and Big Data enthusiast. In his spare time, when he is not on a pair of skis you can find him on his mountain bike.