Artificial Intelligence
Implement checkpointing with TensorFlow for Amazon SageMaker Managed Spot Training
Customers often ask us how can they lower their costs when conducting deep learning training on AWS. Training deep learning models with libraries such as TensorFlow, PyTorch, and Apache MXNet usually requires access to GPU instances, which are AWS instances types that provide access to NVIDIA GPUs with thousands of compute cores. GPU instance types can be more expensive than other Amazon Elastic Compute Cloud (Amazon EC2) instance types, so optimizing usage of these types of instances is a priority for customers as well as an overall best practice for well-architected workloads.
Amazon SageMaker is a fully managed service that provides every developer and data scientist with the ability to prepare, build, train, and deploy machine learning (ML) models quickly. SageMaker removes the heavy lifting from each step of the ML process to make it easier to develop high-quality models. SageMaker provides all the components used for ML in a single toolset so models get to production faster with less effort and at lower cost.
Amazon EC2 Spot Instances offer spare compute capacity available in the AWS Cloud at steep discounts compared to On-Demand prices. Amazon EC2 can interrupt Spot Instances with 2 minutes of notification when the service needs the capacity back. You can use Spot Instances for various fault-tolerant and flexible applications. Some examples are analytics, containerized workloads, stateless web servers, CI/CD, training and inference of ML models, and other test and development workloads. Spot Instance pricing makes high-performance GPUs much more affordable for deep learning researchers and developers who run training jobs.
One of the key benefits of SageMaker is that it frees you of any infrastructure management, no matter the scale you’re working at. For example, instead of having to set up and manage complex training clusters, you simply tell SageMaker which EC2 instance type to use and how many you need. The appropriate instances are then created on-demand, configured, and stopped automatically when the training job is complete. As SageMaker customers have quickly understood, this means that they pay only for what they use. Building, training, and deploying ML models are billed by the second, with no minimum fees, and no upfront commitments. SageMaker can also use EC2 Spot Instances for training jobs, which optimize the cost of the compute used for training deep-learning models.
In this post, we walk through the process of training a TensorFlow model with Managed Spot Training in SageMaker. We walk through the steps required to set up and run a training job that saves training progress in Amazon Simple Storage Service (Amazon S3) and restarts the training job from the last checkpoint if an EC2 instance is interrupted. This allows our training jobs to continue from the same point before the interruption occurred. Finally, we see the savings that we achieved by running our training job on Spot Instances using Managed Spot Training in SageMaker.
Managed Spot Training in SageMaker
SageMaker makes it easy to train ML models using managed EC2 Spot Instances. Managed Spot Training can optimize the cost of training models up to 90% over On-Demand Instances. With only a few lines of code, SageMaker can manage Spot interruptions on your behalf.
Managed Spot Training uses EC2 Spot Instances to run training jobs instead of On-Demand Instances. You can specify which training jobs use Spot Instances and a stopping condition that specifies how long SageMaker waits for a training job to complete using EC2 Spot Instances. Metrics and logs generated during training runs are available in Amazon CloudWatch.
Managed Spot Training is available in all training configurations:
- All instance types supported by SageMaker
- All models: built-in algorithms, built-in frameworks, and custom models
- All configurations: single instance training and distributed training
Interruptions and checkpointing
There’s an important difference when working with Managed Spot Training. Unlike On-Demand Instances that are expected to be available until a training job is complete, Spot Instances may be reclaimed any time Amazon EC2 needs the capacity back.
SageMaker, as a fully managed service, handles the lifecycle of Spot Instances automatically. It interrupts the training job, attempts to obtain Spot Instances again, and either restarts or resumes the training job.
To avoid restarting a training job from scratch if it’s interrupted, we strongly recommend that you implement checkpointing, a technique that saves the model in training at periodic intervals. When you use checkpointing, you can resume a training job from a well-defined point in time, continuing from the most recent partially trained model, and avoiding starting from the beginning and wasting compute time and money.
To implement checkpointing, we have to make a distinction on the type of algorithm you use:
- Built-in frameworks and custom models – You have full control over the training code. Just make sure that you use the appropriate APIs to save model checkpoints to Amazon S3 regularly, using the location you defined in the
CheckpointConfigparameter and passed to the SageMakerEstimator. TensorFlow uses checkpoints by default. For other frameworks, see our sample notebooks and Use Machine Learning Frameworks, Python, and R with Amazon SageMaker. - Built-in algorithms – Computer vision algorithms support checkpointing (object detection, semantic segmentation, and image classification). Because they tend to train on large datasets and run for longer than other algorithms, they have a higher likelihood of being interrupted. The XGBoost built-in algorithm also supports checkpointing.
TensorFlow image classification model with Managed Spot Training
To demonstrate Managed Spot Training and checkpointing, I guide you through the steps needed to train a TensorFlow image classification model. To make sure that your training scripts can take advantage of SageMaker Managed Spot Training, we need to implement the following:
- Frequent saving of checkpoints, thereby saving checkpoints each epoch
- The ability to resume training from checkpoints if checkpoints exist
Save checkpoints
SageMaker automatically backs up and syncs checkpoint files generated by your training script to Amazon S3. Therefore, you need to make sure that your training script saves checkpoints to a local checkpoint directory on the Docker container that’s running the training. The default location to save the checkpoint files is /opt/ml/checkpoints, and SageMaker syncs these files to the specific S3 bucket. Both local and S3 checkpoint locations are customizable.
Saving checkpoints using Keras is very easy. You need to create an instance of the ModelCheckpoint callback class and register it with the model by passing it to the fit() function.
You can find the full implementation code on the GitHub repo.
The following is the relevant code:
The names of the checkpoint files saved are as follows: checkpoint-1.h5, checkpoint-2.h5, checkpoint-3.h5, and so on.
For this post, I’m passing initial_epoch, which you normally don’t set. This lets us resume training from a certain epoch number and comes in handy when you already have checkpoint files.
The checkpoint path is configurable because we get it from args.checkpoint_path in the main function:
Resume training from checkpoint files
When Spot capacity becomes available again after Spot interruption, SageMaker launches a new Spot Instance, instantiates a Docker container with your training script, copies your dataset and checkpoint files from Amazon S3 to the container, and runs your training scripts.
Your script needs to implement resuming training from checkpoint files, otherwise your training script restarts training from scratch. You can implement a load_model_from_checkpoints function as shown in the following code. It takes in the local checkpoint files path (/opt/ml/checkpoints being the default) and returns a model loaded from the latest checkpoint and the associated epoch number.
You can find the full implementation code on the GitHub repo.
The following is the relevant code:
Managed Spot Training with a TensorFlow estimator
You can launch SageMaker training jobs from your laptop, desktop, EC2 instance, or SageMaker notebook instances. Make sure you have the SageMaker Python SDK installed and the right user permissions to run SageMaker training jobs.
To run a Managed Spot Training job, you need to specify few additional options to your standard SageMaker Estimator function call:
- use_spot_instances – Specifies whether to use SageMaker Managed Spot Training for training. If enabled, you should also set the
train_max_waitautomated reasoning group (ARG). - max_wait – Timeout in seconds waiting for Spot training instances (default:
None). After this amount of time, SageMaker stops waiting for Spot Instances to become available or the training job to finish. From previous runs, I know that the training job will finish in 4 minutes, so I set it to 600 seconds. - max_run – Timeout in seconds for training (default:
24 * 60 * 60). After this amount of time, SageMaker stops the job regardless of its current status. I am willing to stand double the time a training with On-Demand takes, so I assign 20 minutes of training time in total using Spot. - checkpoint_s3_uri – The S3 URI in which to persist checkpoints that the algorithm persists (if any) during training.
You can find the full implementation code on the GitHub repo.
The following is the relevant code:
Those are all the changes you need to make to significantly lower your cost of ML training.
To monitor your training job and view savings, you can look at the logs on your Jupyter notebook.
Towards the end of the job, you should see two lines of output:
- Training seconds: X – The actual compute time your training job spent
- Billable seconds: Y – The time you are billed for after Spot discounting is applied.
If you enabled use_spot_instances, you should see a notable difference between X and Y, signifying the cost savings you get for using Managed Spot Training. This is reflected in an additional line:
- Managed Spot Training savings – Calculated as (1-Y/X)*100 %
The following screenshot shows the output logs for our Jupyter notebook:
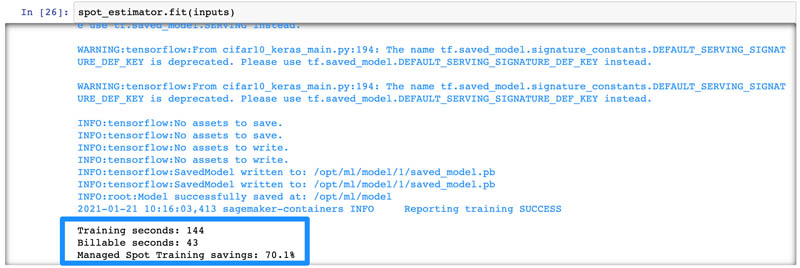
When the training is complete, you can also navigate to the Training jobs page on the SageMaker console and choose your training job to see how much you saved.

For this example training job of a model using TensorFlow, my training job ran for 144 seconds, but I’m only billed for 43 seconds, so for a 5 epoch training on a ml.p3.2xlarge GPU instance, I was able to save 70% on training cost!
Confirm that checkpoints and recovery works for when your training job is interrupted
How can you test if your training job will resume properly if a Spot Interruption occurs?
If you’re familiar with running EC2 Spot Instances, you know that you can simulate your application behavior during a Spot Interruption by following the recommended best practices. However, because SageMaker is a managed service, and manages the lifecycle of EC2 instances on your behalf, you can’t stop a SageMaker training instance manually. Your only option is to stop the entire training job.
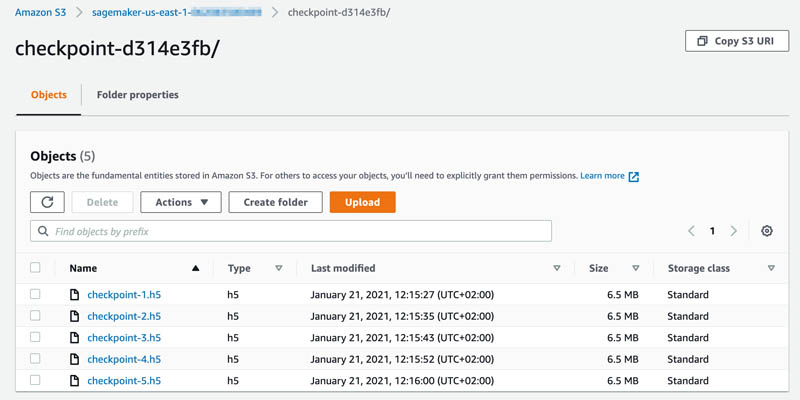
You can still test your code’s behavior when resuming an incomplete training by running a shorter training job, and then using the outputted checkpoints from that training job as inputs to a longer training job. To do this, first run a SageMaker Managed Spot Training job for a specified number of epochs as described in the previous section. Let’s say you run training for five epochs. SageMaker would have backed up your checkpoint files to the specified S3 location for the five epochs.
You can navigate to the training job details page on the SageMaker console to see the checkpoint configuration S3 output path.

Choose the S3 output path link to navigate to the checkpointing S3 bucket, and verify that five checkpoint files are available there.
Now run a second training run with 10 epochs. You should provide the first job’s checkpoint location to checkpoint_s3_uri so the training job can use those checkpoints as inputs to the second training job.
You can find the full implementation code in the GitHub repo.
The following is the relevant code:
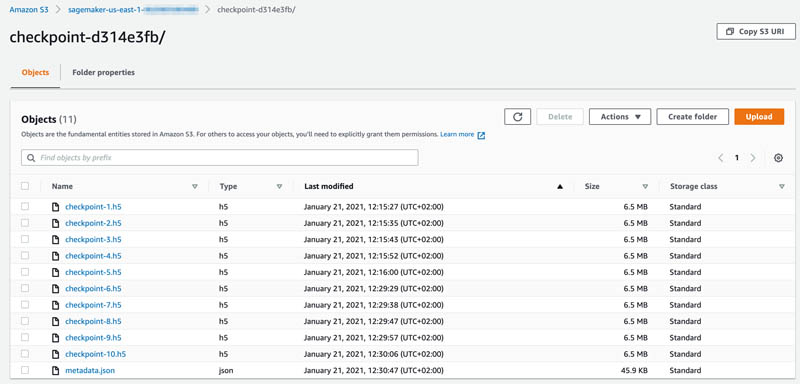
By providing checkpoint_s3_uri with your previous job’s checkpoints, you’re telling SageMaker to copy those checkpoints to your new job’s container. Your training script then loads the latest checkpoint and resumes training. The following screenshot shows that the training resumes resume from the sixth epoch.

To confirm that all checkpoint files were created, navigate to the same S3 bucket. This time you can see that 10 checkpoint files are available.
The key difference between simulating an interruption this way and how SageMaker manages interruptions is that you’re creating a new training job to test your code. In the case of Spot Interruptions, SageMaker simply resumes the existing interrupted job.
Implement checkpointing with PyTorch, MXNet, and XGBoost built-in and script mode
The steps shown in the TensorFlow example are basically the same for PyTorch and MXNet. The code for saving checkpoints and loading them to resume training is different.
You can see full examples for TensorFlow 1.x/2.x, PyTorch, MXNet, and XGBoost built-in and script mode in the GitHub repo.
Conclusions and next steps
In this post, we trained a TensorFlow image classification model using SageMaker Managed Spot Training. We saved checkpoints locally in the container and loaded checkpoints to resume training if they existed. SageMaker takes care of synchronizing the checkpoints with Amazon S3 and the training container. We simulated a Spot interruption by running Managed Spot Training with 5 epochs, and then ran a second Managed Spot Training Job with 10 epochs, configuring the checkpoints’ S3 bucket of the previous job. This resulted in the training job loading the checkpoints stored in Amazon S3 and resuming from the sixth epoch.
It’s easy to save on training costs with SageMaker Managed Spot Training. With minimal code changes, you too can save over 70% when training your deep-learning models.
As a next step, try to modify your own TensorFlow, PyTorch, or MXNet script to implement checkpointing, and then run a Managed Spot Training in SageMaker to see that the checkpoint files are created in the S3 bucket you specified. Let us know how you do in the comments!
About the Author
 Eitan Sela is a Solutions Architect with Amazon Web Services. He works with AWS customers to provide guidance and technical assistance, helping them improve the value of their solutions when using AWS. Eitan also helps customers build and operate machine learning solutions on AWS. In his spare time, Eitan enjoys jogging and reading the latest machine learning articles.
Eitan Sela is a Solutions Architect with Amazon Web Services. He works with AWS customers to provide guidance and technical assistance, helping them improve the value of their solutions when using AWS. Eitan also helps customers build and operate machine learning solutions on AWS. In his spare time, Eitan enjoys jogging and reading the latest machine learning articles.