Artificial Intelligence
Build high-performance ML models using PyTorch 2.0 on AWS – Part 1
PyTorch is a machine learning (ML) framework that is widely used by AWS customers for a variety of applications, such as computer vision, natural language processing, content creation, and more. With the recent PyTorch 2.0 release, AWS customers can now do same things as they could with PyTorch 1.x but faster and at scale with improved training speeds, lower memory usage, and enhanced distributed capabilities. Several new technologies including torch.compile, TorchDynamo, AOTAutograd, PrimTorch, and TorchInductor have been included in the PyTorch2.0 release. Refer to PyTorch 2.0: Our next generation release that is faster, more Pythonic and Dynamic as ever for details.
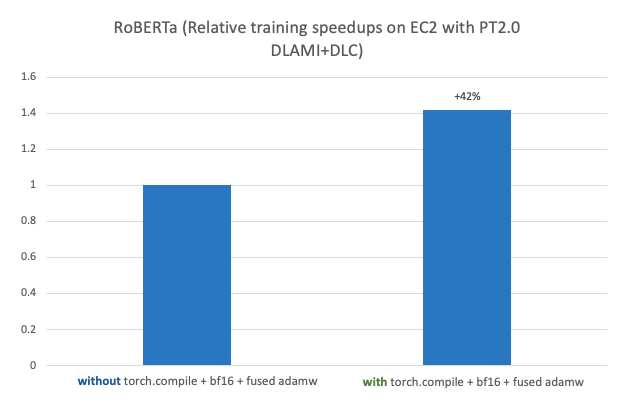
This post demonstrates the performance and ease of running large-scale, high-performance distributed ML model training and deployment using PyTorch 2.0 on AWS. This post further walks through a step-by-step implementation of fine-tuning a RoBERTa (Robustly Optimized BERT Pretraining Approach) model for sentiment analysis using AWS Deep Learning AMIs (AWS DLAMI) and AWS Deep Learning Containers (DLCs) on Amazon Elastic Compute Cloud (Amazon EC2 p4d.24xlarge) with an observed 42% speedup when used with PyTorch 2.0 torch.compile + bf16 + fused AdamW. The fine-tuned model is then deployed on AWS Graviton-based C7g EC2 instance on Amazon SageMaker with an observed 10% speedup compared to PyTorch 1.13.
The following figure shows a performance benchmark of fine-tuning a RoBERTa model on Amazon EC2 p4d.24xlarge with AWS PyTorch 2.0 DLAMI + DLC.
Refer to Optimized PyTorch 2.0 inference with AWS Graviton processors for details on AWS Graviton-based instance inference performance benchmarks for PyTorch 2.0.
Support for PyTorch 2.0 on AWS
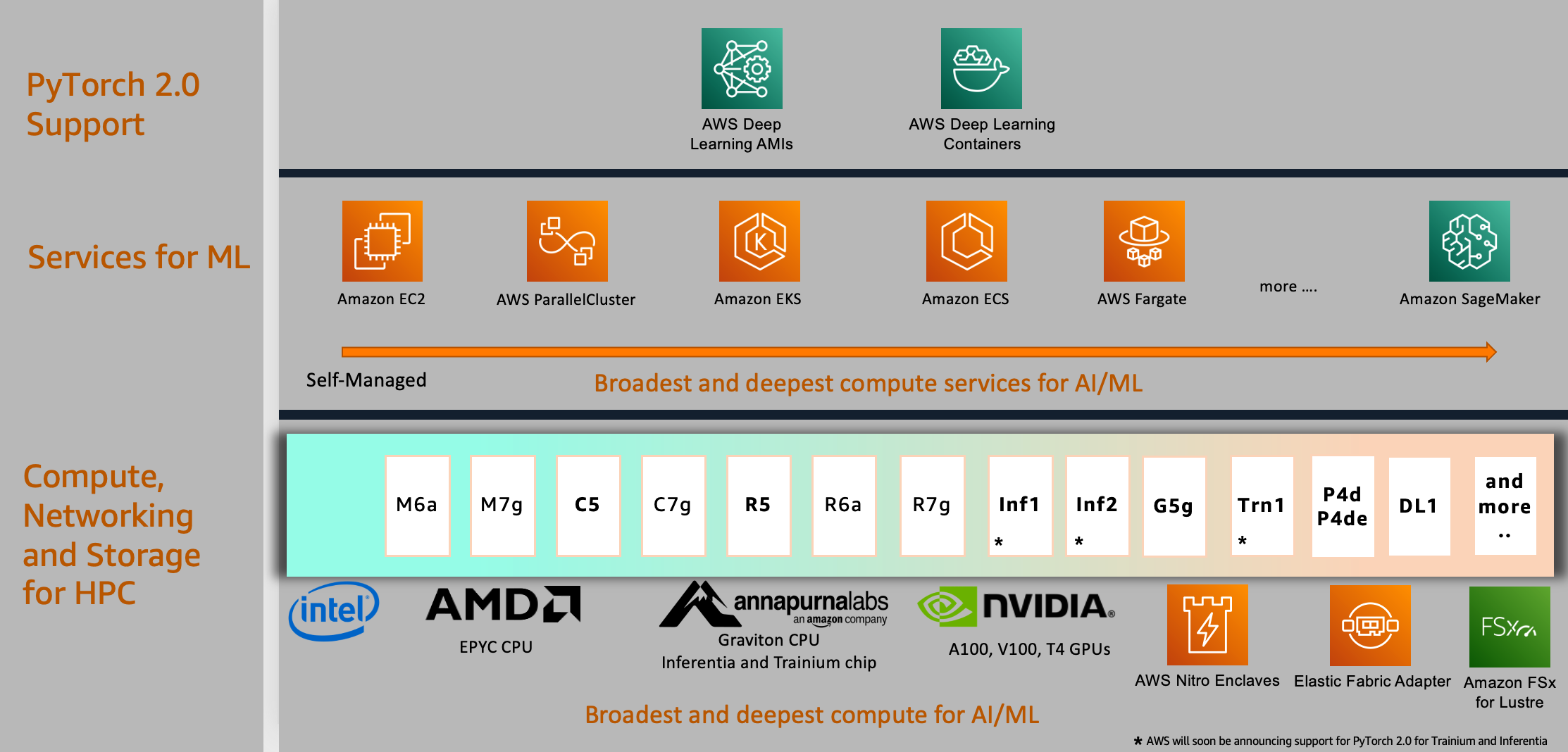
PyTorch2.0 support is not limited to the services and compute shown in example use-case in this post; it extends to many others on AWS, which we discuss in this section.
Business requirement
Many AWS customers, across a diverse set of industries, are transforming their businesses by using artificial intelligence (AI), specifically in the area of generative AI and large language models (LLMs) that are designed to generate human-like text. These are basically big models based on deep learning techniques that are trained with hundreds of billions of parameters. The growth in model sizes is increasing training time from days to weeks, and even months in some cases. This is driving an exponential increase in training and inference costs, which requires, more than ever, a framework such as PyTorch 2.0 with built-in support of accelerated model training and the optimized infrastructure of AWS tailored to the specific workloads and performance needs.
Choice of compute
AWS provides PyTorch 2.0 support on the broadest choice of powerful compute, high-speed networking, and scalable high-performance storage options that you can use for any ML project or application and customize to fit your performance and budget requirements. This is manifested in the diagram in the next section; in the bottom tier, we provide a broad selection of compute instances powered by AWS Graviton, Nvidia, AMD, and Intel processors.
For model deployments, you can use ARM-based processors such as the recently announced AWS Graviton-based instance that provides inference performance for PyTorch 2.0 with up to 3.5 times the speed for Resnet50 compared to the previous PyTorch release, and up to 1.4 times the speed for BERT, making AWS Graviton-based instances the fastest compute-optimized instances on AWS for CPU-based model inference solutions.
Choice of ML services
To use AWS compute, you can select from a broad set of global cloud-based services for ML development, compute, and workflow orchestration. This choice allows you to align with your business and cloud strategies and run PyTorch 2.0 jobs on the platform of your choice. For instance, if you have on-premises restrictions or existing investments in open-source products, you can use Amazon EC2, AWS ParallelCluster, or AWS UltraCluster to run distributed training workloads based on a self-managed approach. You could also use a fully managed service like SageMaker for a cost-optimized, fully managed, and production-scale training infrastructure. SageMaker also integrates with various MLOps tools, which allows you to scale your model deployment, reduce inference costs, manage models more effectively in production, and reduce operational burden.
Similarly, if you have existing Kubernetes investments, you can also use Amazon Elastic Kubernetes Service (Amazon EKS) and Kubeflow on AWS to implement an ML pipeline for distributed training or use an AWS-native container orchestration service like Amazon Elastic Container Service (Amazon ECS) for model training and deployments. Options to build your ML platform are not limited to these services; you can pick and choose depending on your organizational requirements for your PyTorch 2.0 jobs.
Enabling PyTorch 2.0 with AWS DLAMI and AWS DLC
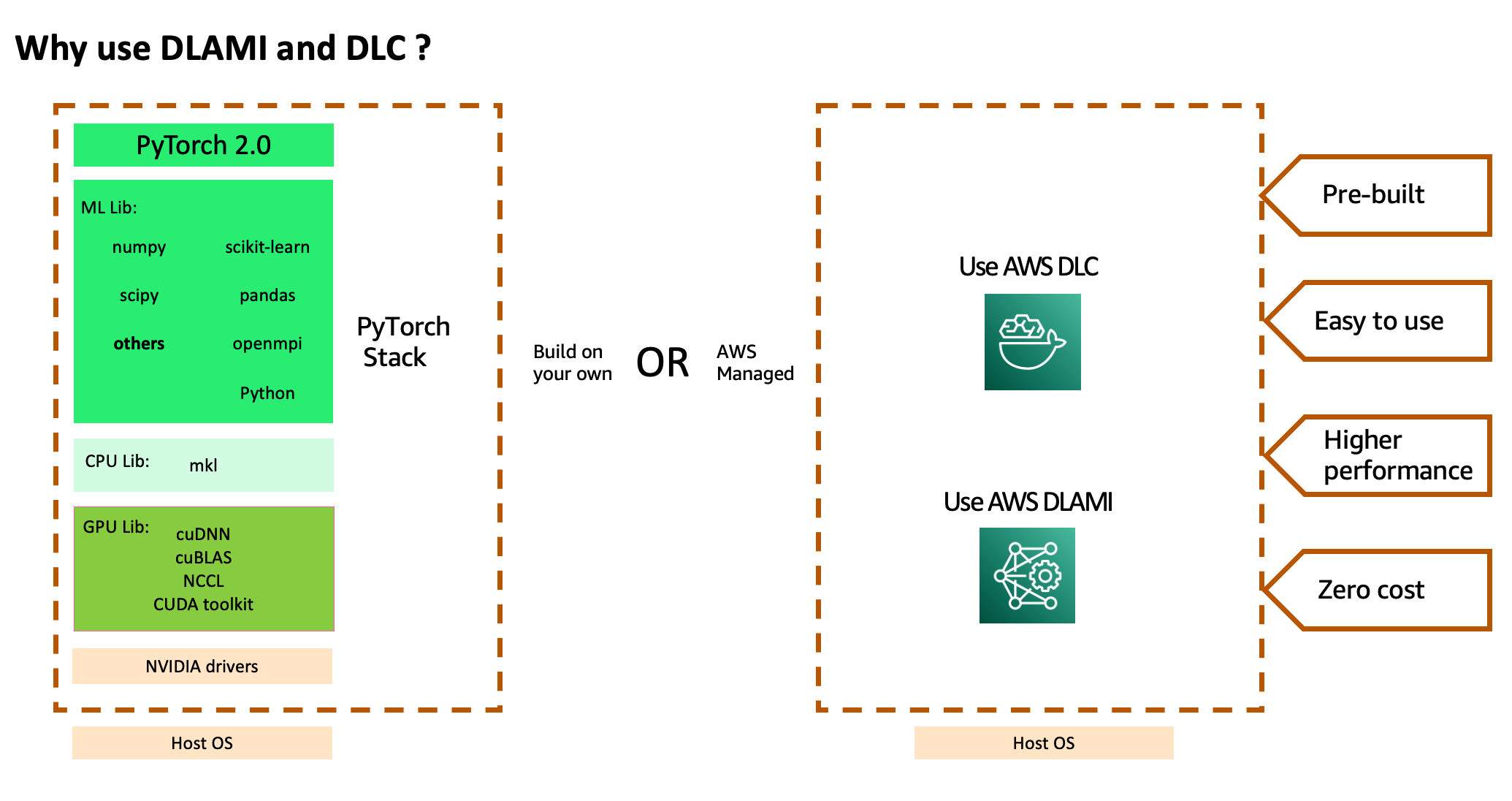
To use the aforementioned stack of AWS services and powerful compute, you have to install an optimized compiled version of the PyTorch2.0 framework and its required dependencies, many of which are independent projects, and test them end to end. You may also need CPU-specific libraries for accelerated math routines, GPU-specific libraries for accelerated math and inter-GPU communication routines, and GPU drivers that need to be aligned with the GPU compiler used to compile the GPU libraries. If your jobs require large-scale multi-node training, you need an optimized network that can provide lowest latency and highest throughput. After you build your stack, you need to regularly scan and patch them for security vulnerabilities and rebuild and retest the stack after every framework version upgrade.
AWS helps reduce this heavy lifting by offering a curated and secure set of frameworks, dependencies, and tools to accelerate deep learning in the cloud though AWS DLAMIs and AWS DLCs. These pre-built and tested machine images and containers are optimized for deep learning on EC2 Accelerated Computing Instance types, allowing you to scale out to multiple nodes for distributed workloads more efficiently and easily. It includes a pre-built Elastic Fabric Adapter (EFA), Nvidia GPU stack, and many deep learning frameworks (TensorFlow, MXNet, and PyTorch with latest release of 2.0) for high-performance distributed deep learning training. You don’t need to spend time installing and troubleshooting deep learning software and drivers or building ML infrastructure, nor do you have to incur the recurring cost of patching these images for security vulnerabilities or recreating the images after every new framework version upgrade. Instead, you can focus on the higher value-added effort of training jobs at scale in a shorter amount of time and iterating on your ML models faster.
Solution overview
Considering that training on GPU and inference on CPU is a popular use case for AWS customers, we have included as part of this post a step-by-step implementation of a hybrid architecture (as shown in the following diagram). We will explore the art-of-the-possible and use a P4 EC2 instance with BF16 support initialized with Base GPU DLAMI including NVIDIA drivers, CUDA, NCCL, EFA stack, and PyTorch2.0 DLC for fine-tuning a RoBERTa sentiment analysis model that gives you control and flexibility to use any open-source or proprietary libraries. Then we use SageMaker for a fully managed model hosting infrastructure to host our model on AWS Graviton3-based C7g instances. We picked C7g on SageMaker because it’s proven to reduce inference costs by up to 50% relative to comparable EC2 instances for real-time inference on SageMaker. The following diagram illustrates this architecture.
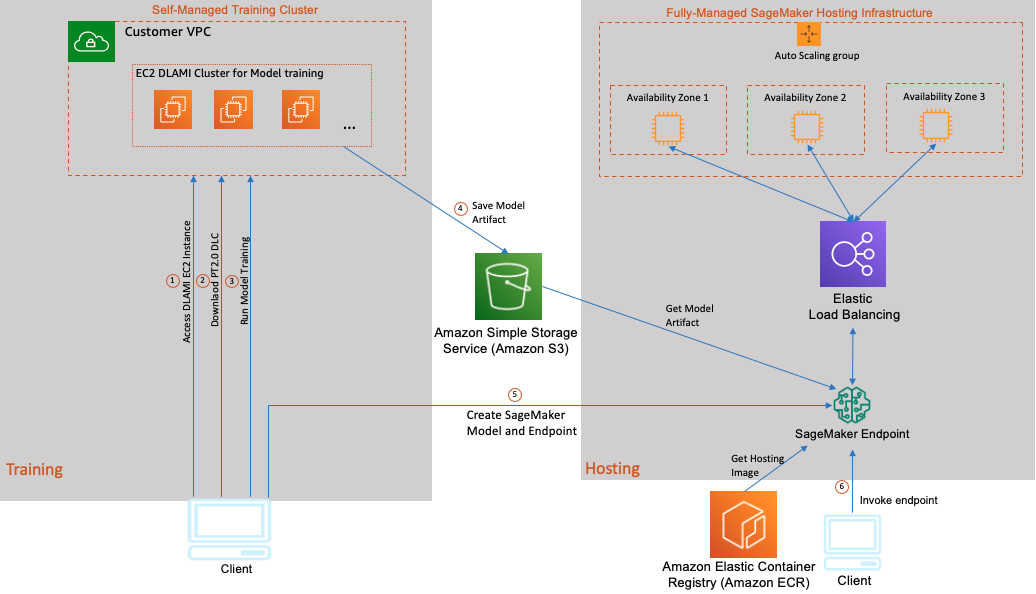
The model training and hosting in this use case consists of the following steps:
- Launch a GPU DLAMI-based EC2 Ubuntu instance in your VPC and connect to your instance using SSH.
- After you log in to your EC2 instance, download the AWS PyTorch 2.0 DLC.
- Run your DLC container with a model training script to fine-tune the RoBERTa model.
- After model training is complete, package the saved model, inference scripts, and a few metadata files into a tar file that SageMaker inference can use and upload the model package to an Amazon Simple Storage Service (Amazon S3) bucket.
- Deploy the model using SageMaker and create an HTTPS inference endpoint. The SageMaker inference endpoint holds a load balancer and one or more instances of your inference container in different Availability Zones. You can deploy either multiple versions of the same model or entirely different models behind this single endpoint. In this example, we host a single model.
- Invoke your model endpoint by sending it test data and verify the inference output.
In the following sections, we showcase fine-tuning a RoBERTa model for sentiment analysis. RoBERTa is developed by Facebook AI, improving on the popular BERT model by modifying key hyperparameters and pre-training on a larger corpus. This leads to improved performance compared to vanilla BERT.
We use the transformers library by Hugging Face to get the RoBERTa model pre-trained on approximately 124 million tweets, and we fine-tune it on the Twitter dataset for sentiment analysis.
Prerequisites
Make sure you meet the following prerequisites:
- You have an AWS account.
- Make sure you’re in the
us-west-2Region to run this example. (This example is tested inus-west-2; however, you can run in any other Region.) - Create a role with the name
sagemakerrole. Add managed policiesAmazonSageMakerFullAccessandAmazonS3FullAccessto give SageMaker access to S3 buckets. - Create an EC2 role with the name
ec2_role. Use the following permission policy:
1. Launch your development instance
We create a p4d.24xlarge instance that offers 8 NVIDIA A100 Tensor Core GPUs in us-west-2:
When selecting the AMI, follow the release notes to run this command using the AWS Command Line Interface (AWS CLI) to find the AMI ID to use in us-west-2:
Make sure the size of the gp3 root volume is 200 GiB.
EBS volume encryption is not enabled by default. Consider changing this when moving this solution to production.
2. Download a Deep Learning Container
AWS DLCs are available as Docker images in Amazon Elastic Container Registry Public, a managed AWS container image registry service that is secure, scalable, and reliable. Each Docker image is built for training or inference on a specific deep learning framework version, Python version, with CPU or GPU support. Select the PyTorch 2.0 framework from the list of available Deep Learning Containers images.
Complete the following steps to download your DLC:
a. SSH to the instance. By default, security group used with EC2 opens up SSH port to all. Please consider this if you are moving this solution to production:
By default, the security group used with Amazon EC2 opens up the SSH port to all. Consider changing this if you are moving this solution to production.
b. Set the environment variables required to run the remaining steps of this implementation:
Amazon ECR supports public image repositories with resource-based permissions using AWS Identity and Access Management (IAM) so that specific users or services can access images.
c. Log in to the DLC registry:
d. Pull the latest PyTorch 2.0 container with GPU support in us-west-2
If you get the error “no space left on device”, make sure you increase the EC2 EBS volume to 200 GiB and then extend the Linux file system.
3. Clone the latest scripts adapted to PyTorch 2.0
Clone the scripts with the following code:
Because we’re using the Hugging Face transformers API with the latest version 4.28.1, it has already enabled PyTorch 2.0 support. We added the following argument to the trainer API in train_sentiment.py to enable new PyTorch 2.0 features:
- Torch compile – Experience an average 43% speedup on Nvidia A100 GPUs with single line of change.
- BF16 datatype – New data type support (Brain Floating Point) for Ampere or newer GPUs.
- Fused AdamW optimizer – Fused AdamW implementation to further speed up training. This stochastic optimization method modifies the typical implementation of weight decay in Adam by decoupling weight decay from the gradient update.
4. Build a new Docker image with dependencies
We extend the pre-built PyTorch 2.0 DLC image to install the Hugging Face transformer and other libraries that we need to fine-tune our model. This allows you to use the included tested and optimized deep learning libraries and settings without having to create an image from scratch. See the following code:
5. Start training using the container
Run the following Docker command to begin fine-tuning the model on the tweet_eval sentiment dataset. We’re using the Docker container arguments (shared memory size, max locked memory, and stack size) recommend by Nvidia for deep learning workloads.
You should expect the following output. The script first downloads the TweetEval dataset, which consists of seven heterogenous tasks in Twitter, all framed as multi-class tweet classification. The tasks include irony, hate, offensive, stance, emoji, emotion, and sentiment.
The script then downloads the base model and starts the fine-tuning process. Training and evaluation metrics are reported at the end of each epoch.
Performance statistics
With PyTorch 2.0 and the latest Hugging Face transformers library 4.28.1, we observed a 42% speedup on a single p4d.24xlarge instance with 8 A100 40GB GPUs. Performance improvements comes from a combination of torch.compile, the BF16 data type, and the fused AdamW optimizer. The following code is the final result of two training runs with and without new features:
6. Test the trained model locally before preparing for SageMaker inference
You can find the following files under $ml_working_dir/saved_model/ after training:
Let’s make sure we can run inference locally before preparing for SageMaker inference. We can load the saved model and run inference locally using the test_trained_model.py script:
You should expect the following output with the input “Covid cases are increasing fast!”:
7. Prepare the model tarball for SageMaker inference
Under the directory where the model is located, make a new directory called code:
In the new directory, create the file inference.py and add the following to it:
In the end, you should have the following folder structure:
The model is ready to be packaged and uploaded to Amazon S3 for use with SageMaker inference:
8. Deploy the model on a SageMaker AWS Graviton instance
New generations of CPUs offer a significant performance improvement in ML inference due to specialized built-in instructions. In this use case, we use the SageMaker fully managed hosting infrastructure with AWS Graviton3-based C7g instances. AWS has also measured up to a 50% cost savings for PyTorch inference with AWS Graviton3-based EC2 C7g instances across Torch Hub ResNet50, and multiple Hugging Face models relative to comparable EC2 instances.
To deploy the models to AWS Graviton instances, we use AWS DLCs that provide support for PyTorch 2.0 and TorchServe 0.8.0, or you can bring your own containers that are compatible with the ARMv8.2 architecture.
We use the model we trained earlier: s3://<your-s3-bucket>/twitter-roberta-base-sentiment-latest.tar.gz. If you haven’t used SageMaker before, review Get Started with Amazon SageMaker.
To start, make sure the SageMaker package is up to date:
Because this is an example, create a file called start_endpoint.py and add the following code. This will be the Python script to start a SageMaker inference endpoint with the mode:
We’re using ml.c7g.4xlarge for the instance and are retrieving PT 2.0 with an image scope inference_graviton. This is our AWS Graviton3 instance.
Next, we create the file that runs the prediction. We do these as separate scripts so we can run the predictions as many times as we want. Create predict.py with the following code:
With the scripts generated, we can now start an endpoint, do predictions against the endpoint, and clean up when we’re done:
9. Clean up
Lastly, we want to clean up from this example. Create cleanup.py and add the following code:
Conclusion
AWS DLAMIs and DLCs have become the go-to standard for running deep learning workloads on a broad selection of compute and ML services on AWS. Along with using framework-specific DLCs on AWS ML services, you can also use a single framework on Amazon EC2, which removes the heavy lifting necessary for developers to build and maintain deep learning applications. Refer to Release Notes for DLAMI and Available Deep Learning Containers Images to get started.
This post showed one of many possibilities to train and serve your next model on AWS and discussed several formats that you can adopt to meet your business objectives. Give this example a try or use our other AWS ML services to expand the data productivity for your business. We have included a simple sentiment analysis problem so that customers new to ML can understand how simple it is to get started with PyTorch 2.0 on AWS. We will be covering more advanced use cases, models, and AWS technologies in upcoming blog posts.
About the authors
 Kanwaljit Khurmi is a Principal Solutions Architect at Amazon Web Services. He works with the AWS customers to provide guidance and technical assistance helping them improve the value of their solutions when using AWS. Kanwaljit specializes in helping customers with containerized and machine learning applications.
Kanwaljit Khurmi is a Principal Solutions Architect at Amazon Web Services. He works with the AWS customers to provide guidance and technical assistance helping them improve the value of their solutions when using AWS. Kanwaljit specializes in helping customers with containerized and machine learning applications.
 Mike Schneider is a Systems Developer, based in Phoenix AZ. He is a member of Deep Learning containers, supporting various Framework container images, to include Graviton Inference. He is dedicated to infrastructure efficiency and stability.
Mike Schneider is a Systems Developer, based in Phoenix AZ. He is a member of Deep Learning containers, supporting various Framework container images, to include Graviton Inference. He is dedicated to infrastructure efficiency and stability.
 Lai Wei is a Senior Software Engineer at Amazon Web Services. He is focusing on building easy to use, high-performance and scalable deep learning frameworks for accelerating distributed model training. Outside of work, he enjoys spending time with his family, hiking, and skiing.
Lai Wei is a Senior Software Engineer at Amazon Web Services. He is focusing on building easy to use, high-performance and scalable deep learning frameworks for accelerating distributed model training. Outside of work, he enjoys spending time with his family, hiking, and skiing.