AWS Public Sector Blog
How government agencies can vet external data in minutes with data interchange zones

The rapid digitalization of government services has transformed the way government agencies interact and exchange data with each other and with their communities. These data interchanges can take different forms; one example is how regulatory agencies can provide entities with a simple mechanism to ingest regulatory reporting. However, the manual processes agencies use to exchange data are no longer viable. Agencies are challenged by the volume of data, slow processes, and the potential for human error. Plus, government agencies are endeavouring to improve their customer service experience to meet the rapid change in their citizens’ behaviour and expectations in the digital age.
In this blog post, learn how government agencies can use Amazon Web Services (AWS) to build data interchange zones to automate their ability to ingest and validate data from other agencies or external entities in a secure manner. Automating this process can help agencies save time to focus on more strategic aspects of their mission.
Data interchange challenges for government agencies
Obtaining secure data from external entities poses many challenges for government agencies. These challenges include receiving datasets with different file formats and sizes; the need for multi-layer dataset vetting processes like malware checking and schema validation; and seamless integration with different internal platforms, such as protected data lakes and authentication and authorization systems. To address these obstacles, government agencies can establish a protected data interchange platform to create a multi-layered rigorous dataset vetting process between external entities and internal systems.
How to build data interchange zones on AWS
A data interchange zone acts as a public interface to a protected data lake, enabling external entities to simply and securely upload or download validated datasets or reports. In the following architecture framework (Figure 1) for a data interchange zone using AWS services, the solution is built on a serverless architecture. Using severless architecture can help agencies scale and meet workload demand during different data collection cycles. Serverless architecture features automatic scaling, built-in high availability, and an only-pay-for-what-you-use billing model to increase agility and optimize costs.
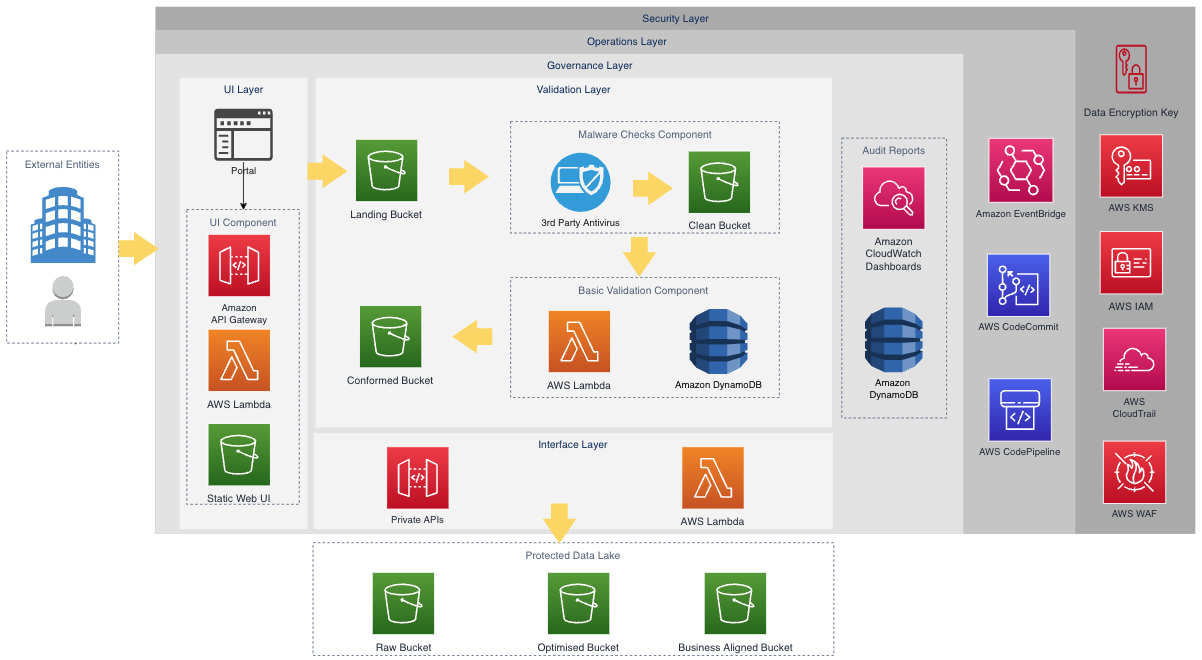
Figure 1. The high-level architecture for a data interchange zone.
This solution is composed of three key layers: the user interface (UI) layer, the validation layer, and the integration interface layer. For the UI layer, the platform has a UI component that communicates and integrates with the other systems (e.g., regulatory portals) to authenticate the users using Amazon API Gateway and AWS Lambda. Authenticated users can then upload files to the data interchange zone.
This is where services in the data validation layer take over. The solution uses AWS Step Functions as a workflow service to orchestrate Lambda functions, which perform malware checks (using third-party antivirus software) and basic data validations. This includes validations such as file format checks and schema validation.
To communicate with the platform, an interface layer uses private API Gateways to allow internal platforms, such as a protected data lake, to move the curated datasets to the raw bucket. In return, the protected data lake can provide reports on the quality of the datasets received from the external entities after further processing, and serve those reports back to end users, using API Gateway and Lambda supported by the interface and UI layer.
UI layer
To interact with the data interchange zone, external entities need to pass through authentication and authorization processes established in the UI layer. Figure 2 shows the high-level flow along with the different services involved to allow external entities to upload the data securely into the landing bucket.

Figure 2. The authentication and authorization high-level flow.
First, external entities can use the UI layer to log into the data interchange through an Amazon Cognito user pool or through the Amazon Cognito federated identify provider (IdP).
Once entities successfully log in, the entity client will receive valid Jason Web Tokens (JWT), such as an ID token, access token, and refresh tokens as part of the authentication response. Then the external entities make a REST API call to the API Gateway endpoint with the valid JWT ID token as an authorization header. API Gateway checks if the JWT token is valid, as it is configured with Amazon Cognito as the authorizer. If the token is valid, the API Gateway invokes the Lambda function to generate an Amazon Simple Storage Service (Amazon S3) pre-signed URL to upload the data.
Finally, the external entity can upload files to the data interchange via the pre-signed URL returned in the previous step. With Amazon Cognito integration with API gateway and Lambda, only authenticated and authorized entities can upload files into the landing bucket.
Validation and integration interface layer
The validation process starts with a file upload event triggered by Amazon S3. The event is picked up by an AWS Lambda, which routes it to the AWS Step Function where processing begins with malware check, as shown in Figure 3. Based on the malware check result, which can be either clean or infected, the file is moved to either quarantine or clean buckets in Amazon S3. If the file is clean, the basic validation triggers to run checks against the predefined validation rules stored in Amazon DynamoDB.
Once the validation is complete, the results persist in DynamoDB. By enabling Amazon DynamoDB Streams, you can capture a time-ordered sequence of item-level modifications. Lambda polls the stream and invokes the data interchange lambda function synchronously when it detects new stream records to update the UI using the WebSocket API call, as shown in Figure 3.
Once all the mandatory files have passed the validation, the private API waits for a signal from the other systems, like the protected data lake, to move the file from a conformed bucket to the data lake for further processing. All the processing steps throughout the flow are recorded in an DynamoDB table for audit and logging purposes.
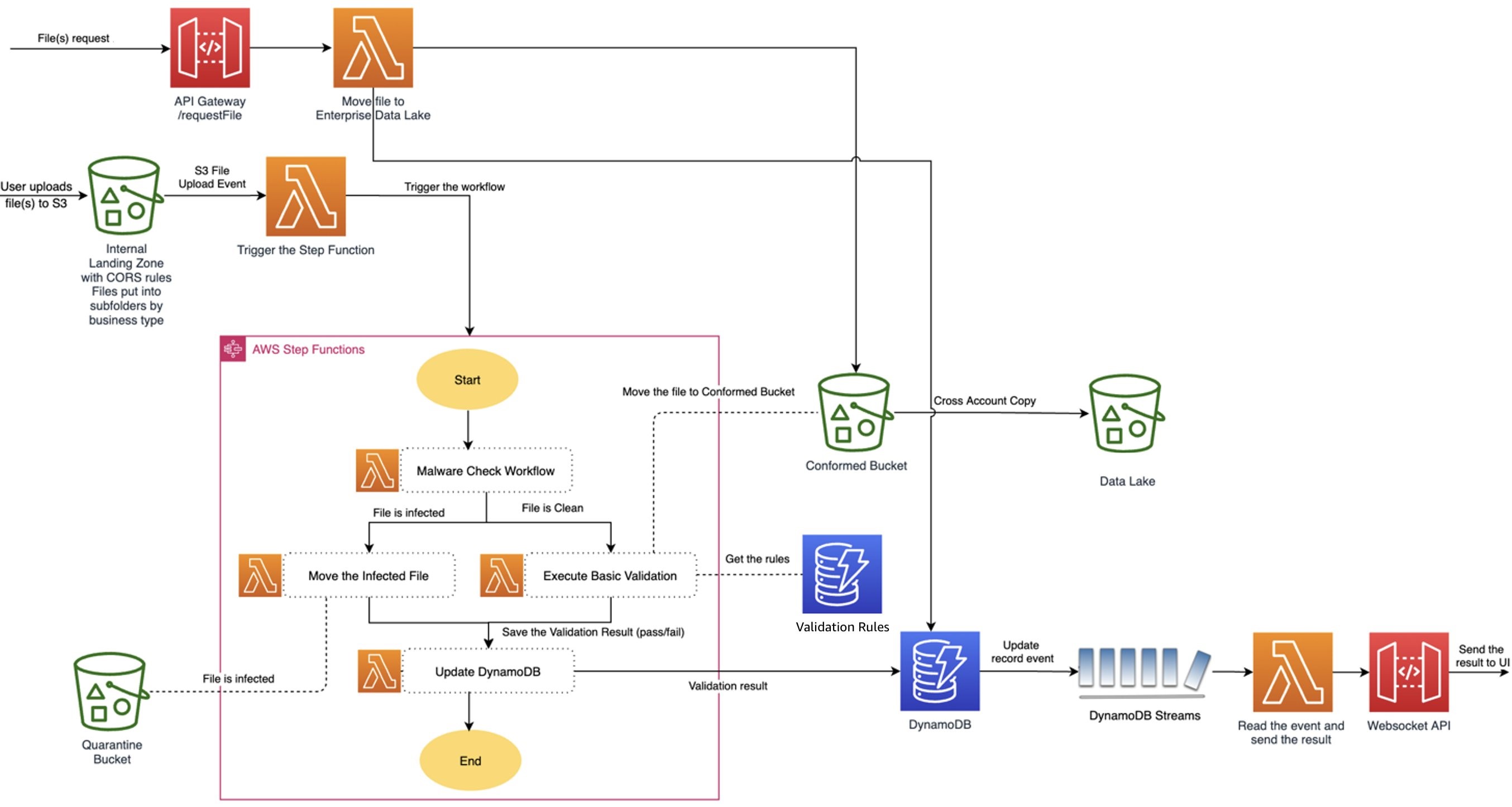
Figure 3. The validation and integration interfaces.
Get started with data interchange zones
Creating a data interchange zone as an extensible secure data acquisition pattern can provide government agencies with a secure, cost effective, and automated approach to onboard data sources from external entities. By running rigorous data validation and security checks in near real-time with AWS services, government agencies can expand their secure data acquisition cycle to external entities or the community in a simple and automated way.
If you want to learn more, reach out to your AWS Account Team or AWS Professional Services. Not yet an AWS customer and want to learn more? Send an inquiry to the AWS Public Sector Sales team.
Read more about AWS for government:
- How to improve government customer experience by building a modern serverless web application in AWS GovCloud (US)
- Enabling secure mission success with Wickr RAM in Department of Defense Cloud One
- How to implement CNAP for federal and defense customers in AWS
- Architecture framework for transforming federal customer experience and service delivery
- How public sector agencies can identify improper payments with machine learning
- Move data in and out of AWS GovCloud (US) with Amazon S3
Subscribe to the AWS Public Sector Blog newsletter to get the latest in AWS tools, solutions, and innovations from the public sector delivered to your inbox, or contact us.
Please take a few minutes to share insights regarding your experience with the AWS Public Sector Blog in this survey, and we’ll use feedback from the survey to create more content aligned with the preferences of our readers.