AWS Public Sector Blog
How public sector agencies can identify improper payments with machine learning

Many government agencies employ rules-based systems to identify improper payments. Improper payments are those that either should not be made, or are made in the incorrect amount, due to fraud or other errors. Rules-based techniques involve manually researching, understanding, and identifying patterns and heuristics that are then applied as business rules to flag potential issues. However, this approach increases the amount of time taken to identify improper payments due to the heavy dependence on continuously adding and updating rules based on ever changing and newly emerging patterns. In addition, traditional techniques fail to capture emerging threats such as synthetic ID fraud.
In synthetic ID fraud, a fraudster applies for government benefits or services using a real Social Security number combined with fake transaction information and an address or a bank account where they can receive funds. To mitigate this type of fraud, agencies need to complement their rules-based improper payment detection systems with machine learning (ML) techniques. By using ML on a large number of disparate but related data sources, including social media, agencies can formulate a more comprehensive risk score for each individual or transaction to help investigators identify improper payments efficiently.
In “Fighting fraud and improper payments in real-time at the scale of federal expenditures,” we described how public sector agencies can use Amazon Web Services (AWS) to solve multi-sided issues of payment integrity and fight improper payments. In this blog post, we provide a foundational reference architecture for an ML-powered improper payment detection solution using AWS ML services. We then explore the different types of ML techniques that can be used, and discuss techniques to identify and limit bias and explain predictions generated by models. Agencies can leverage code we developed for an example use case of detecting fraud in Medicare providers’ data released by the Centers for Medicare & Medicaid Services (CMS) to understand these techniques and apply them to their own data and use cases.
Reference architecture for ML-powered improper payment detection solution
The reference architecture in the following Figure 1 illustrates some of the foundational components of an ML-powered improper payment detection solution using AWS services. The same reference architecture can also be extended to other types of payment and identity fraud.
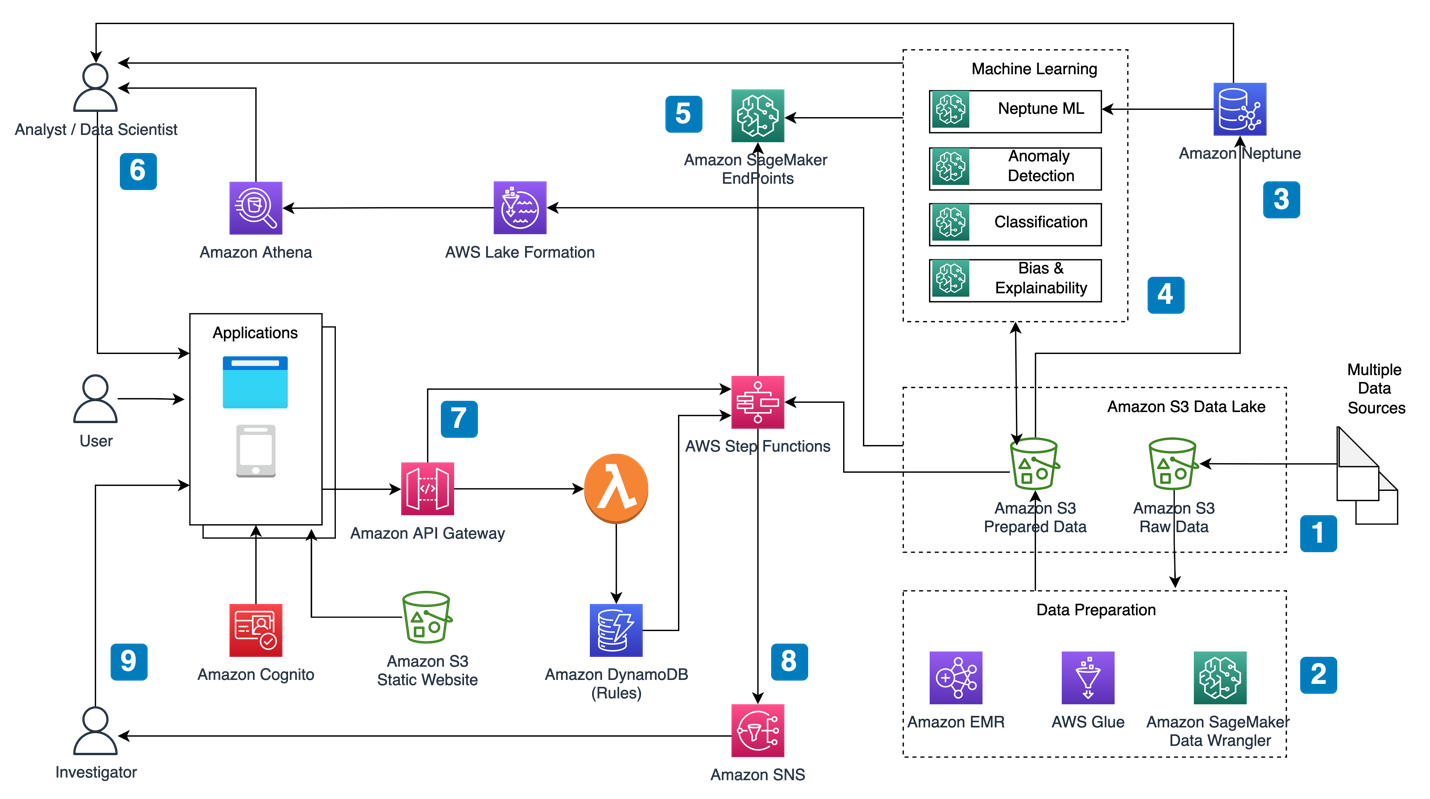
Figure 1. Sample AWS reference architecture for improper payment detection using machine learning, described in detail in the following section.
The following section describes the architecture components labelled in Figure 1 and how each service functions within the solution:
1. Gather data from multiple sources
To effectively identify improper payments, agencies need to gather data from diverse sources, including social media and customer feedback. ML algorithms can mine a complex data terrain to establish outlying activities and identify potential instances of misconduct. AWS Lake Formation can be used to set up a secure data lake that hosts this data. A data lake is a centralized, curated, and secured repository of Amazon Simple Storage Service (Amazon S3) buckets that stores all your data, both in its original form and prepared for analysis.
2. Prepare data needed for ML model development
Data from the source Amazon S3 buckets needs to be transformed into required formats for ML- and rules-based analysis. Agencies can choose between a number of different options such as Amazon SageMaker Data Wrangler, Amazon EMR, and AWS Glue to accomplish this. Transformed data is uploaded in to an Amazon S3 bucket in the data lake. AWS Lake Formation automatically enables the data in these buckets to be cataloged so that analysts and data scientists can find the data for analytics and modeling.
3. Load data for graph-based analytics
Transactional data has basic attribute information, but does not include relationships, such as those between people, shared addresses, and others. This makes it hard to identify fraud that is committed by groups of coordinated actors or by a single actor over time. Using Amazon Neptune, you can model relationships between people, places, and transactions, and discover additional relationships that may not be obvious. Transactional data from the raw Amazon S3 buckets can be transformed into required formats for Amazon Neptune using the services described in Step 2. The data can then be loaded into Amazon Neptune using the Neptune Bulk Loader.
4. Develop models
There are a number of different types of ML models that can be used to predict improper payments. The most commonly used techniques include unsupervised learning using anomaly detection, and supervised learning using classification. Amazon SageMaker is a comprehensive service that agencies can use for every step of ML model development and implementation using these techniques. Amazon SageMaker is integrated with Amazon Neptune ML to allow agencies to leverage machine learning techniques purpose-built for graphs for improved results. We explore details on the various modeling techniques in the next section.
5. Deploy ML models to endpoints
Once you have classified the data and developed the ML models, you can use Amazon SageMaker to deploy trained ML models for real-time inferences as well as batch inferences. In the case of improper payment detection, deploying the model for real-time inferences accelerates the timeframe available for investigators to research and identify fraud cases. Real-time inferences are obtained through persistent HTTPS endpoints, which can be configured to support the entire spectrum of inference needs, from low latency (a few milliseconds) and/or high throughput (hundreds of thousands of inference requests per second).
6. Analyze data and setup business rules for rules-based detections
ML techniques alone are not sufficient to identify all types of improper payments. It is important to supplement ML with business rules developed previously using identified patterns and heuristics. To accomplish this, analysts and data scientists can discover business rules that need to be applied by analyzing data collected in the Amazon S3 data lake using Amazon Athena and also by performing queries in Amazon Neptune. The business rules can be stored with a serverless web application architecture using Amazon S3, Amazon Cognito, Amazon API Gateway, and Amazon DynamoDB. Alternatively, business rules can be housed in an open sourced or proprietary rules engine of choice, and integrated using the engine API.
7. User submits claims in application
Amazon API Gateway is also used to host a REST API that exposes a POST method that the user application invokes when a claim is submitted. The POST request on the API triggers an AWS Step Functions workflow. The workflow consists of a series of steps backed by AWS Lambda functions as necessary. The steps include transforming the input data as required to make calls to Amazon SageMaker endpoints as well as to perform business rules stored in Amazon DynamoDB. Additional steps also include parsing of external data stored in Amazon S3 to check known lists of fraudsters or IP addresses. Probability scores of improper payment activity returned from the SageMaker endpoints and rules-based calculations are saved in Amazon DynamoDB.
8. High scores trigger Amazon SNS alerts to Investigators
Depending on the business case, each agency can determine thresholds for each score. A lambda function in the Step Function workflow checks when a score crosses a threshold. If the score crosses a threshold, it publishes a message to an Amazon Simple Notification Service (Amazon SNS) topic. Investigators researching improper payments subscribe to the Amazon SNS topic so that whenever a high score is flagged, an alert is created for investigators. This process dramatically reduces the number of potential cases that investigators need to research and gives them a head start to make intervening decisions to minimize loss due to improper payments.
9. Investigators use application for research
Agencies can develop an application for investigators to review scores stored in Amazon DynamoDB as well as information about the claim. Different kinds of visualizations and dashboards can be developed to help investigators conduct research into the flagged claims.
ML techniques and considerations for synthetic fraud detection
In Step 4 of the reference architecture, we briefly discussed different types of ML techniques to predict improper payments using Amazon SageMaker. SageMaker enables agencies to quickly select the optimum infrastructure for their workloads, while simplifying the model building, deployment, and maintenance aspects with features such as SageMaker Automatic tuning, real-time monitoring of training metrics, distributed training, and MLOps. There are two broad categories of ML techniques that can be used to predict improper payments using Amazon SageMaker:
1. Unsupervised learning with anomaly detection
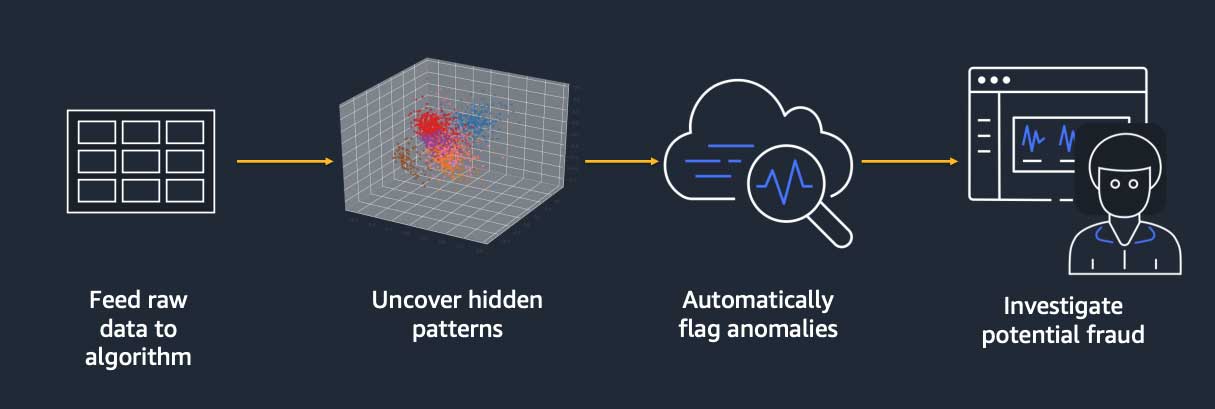
Figure 2. Unsupervised learning techniques for fraud detection.
Figure 2 illustrates the process for using unsupervised learning techniques to develop ML models. Anomaly detection is the most commonly used unsupervised learning technique in fraud analytics. In this approach, you feed in all data, and the model identifies “anomalies” which indicate something unusual about the data. Amazon SageMaker provides a built-in anomaly detection algorithm called Random Cut Forest which detects anomalous data points within a data set. Other options for anomaly detection include deep learning techniques such as AutoEncoders (AE). Amazon SageMaker provides bring-your-own-script and bring-your-own-container options to build these models in the framework of your choice and implement them in Amazon SageMaker.
The biggest advantage with this approach is that you do not need “labeled” data indicating an improper payment. The model creates anomaly scores for each record, with high values indicating the presence of a potentially improper payment. The best use of this method is to use the top scores to quickly identify a subset of the cases, and then use other techniques such as supervised learning to refine the model.
2. Supervised learning

Figure 3. Supervised learning techniques for fraud detection.
Figure 3 illustrates the process of using supervised learning techniques to develop ML models. Amazon SageMaker provides two built-in algorithms for applying supervised learning techniques on tabular data to identify improper payments: XGBoost (eXtreme Gradient Boosting) and the Linear Learner algorithm. You can also build models in the framework of your choice and implement them in Amazon SageMaker using bring-your-own-script and bring-your-own-container options.
Supervised learning techniques can often correctly predict a majority of improper payments, especially as compared to unsupervised learning methods. To deal with imbalanced data, utilize techniques like random over sampling and under sampling as discussed in the article, “Medicare fraud detection using neural networks.” Other techniques used include supplementing data with additional features that can contribute to model prediction, and adding penalties to the cost function for wrong prediction of the minority class.
ML using data in a tabular format can result in a lot of false positives, which can be problematic because it increases the amount of research and time spent by investigators. Techniques using Graph Neural Networks (GNN) can provide better performance with reduced false positives in some cases. Graph-based databases such as Amazon Neptune can be used to model the complex relationships between entities such as names, devices, IP addresses, zip codes, transaction codes, and more. ML with GNN provides the ability to incorporate the relationships between entities while developing machine models, thereby increasing the overall performance of ML models. Amazon SageMaker provides deep learning containers that are preconfigured with Deep Graph Library (DGL), an open-source library that enables training models on graph datasets. Agencies can also consider using Amazon Neptune ML to automate the heavy lifting of selecting and training the best ML model for graph data, and run machine learning on their graph directly using Neptune APIs and queries.
Agencies can leverage code we developed for an example use case of detecting fraud in Medicare providers’ data released by the Centers for Medicare & Medicaid Services (CMS) to understand some of the above techniques and apply them to their own data and use cases.
Bias and explainability in machine learning model prediction
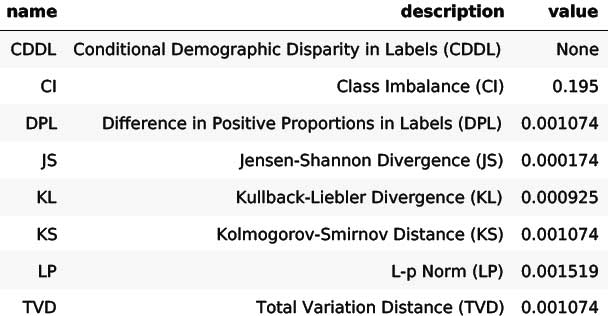
Public sector agencies applying ML need to understand the imbalances in the training data or prediction behavior of the model across different groups, as well as the reasoning behind the model’s predictions. Agencies can use Amazon SageMaker Clarify for greater visibility into training data and models to identify and limit bias and explain predictions. This tool provides standardized metrics to help determine pre-training bias and post-training data and model bias. Table 1 illustrates the results obtained with the Amazon SageMaker XGBoost built-in algorithm on the CMS-released Medicare fraud data on the feature indicating gender. In general, many of the metric values range from -1 to +1, and values closer to 0 represent lower bias. To understand more about the metrics in Table 1, refer to this whitepaper.
| Pre-Training | Post-Training |
 |
 |
Table 1: Pre-training and post-training bias metrics using SageMaker Clarify.
SageMaker Clarify also provides a report that shows the relative importance of all the features in the predictions of fraud using SHAP (SHapley Additive exPlanations) values. We show the report obtained on the CMS released Medicare fraud data in Figure 4.
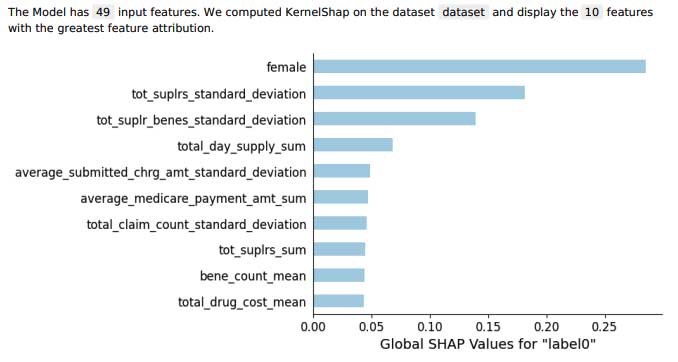
Figure 4. Explainability of predictions using SageMaker Clarify.
Figure 4 shows that a claim made by an entity that submitted their gender as female is the strongest variable towards a fraud prediction. These types of insights help investigators dig deeper into potential issues and trends. For example, this may indicate that fraudsters, especially those associated with synthetic fraud, use female IDs to throw off suspicion on claims.
One limitation to SageMaker Clarify is that it cannot be applied to explain predictions using GNNs currently. For explainability with GNNs, agencies can explore using custom libraries such as GNN Explainer.
Learn more about machine learning for public sector organizations
In this blog post, we discussed how public sector agencies can use AWS to address improper payments using ML. We also provided links to ML code for an example use case that agencies can use to review these techniques and apply them to their own data and use cases. To learn more about how you can use ML to address fraud and related public sector issues, read the white paper Machine Learning Best Practices for Public Sector Organizations, which describes how Amazon SageMaker provides public sector agencies a comprehensive toolkit to solve challenges of ML implementation.
Contact the public sector team directly, or reach out to your AWS account team to engage on a proof of concept of an ML fraud detection solution.
Read more related stories on the AWS Public Sector Blog:
- Fighting fraud and improper payments in real-time at the scale of federal expenditures
- AWS GovCloud (US) or standard? Selecting the right AWS partition
- Approaches in retail central bank digital currency: Aligning technology with policy
- Governments look to digital ID to modernize services and boost growth
- Taxes, governments, and great experiences using the cloud
- Using AI to rethink document automation and extract insights
Subscribe to the AWS Public Sector Blog newsletter to get the latest in AWS tools, solutions, and innovations from the public sector delivered to your inbox, or contact us.
Please take a few minutes to share insights regarding your experience with the AWS Public Sector Blog in this survey, and we’ll use feedback from the survey to create more content aligned with the preferences of our readers.