AWS Public Sector Blog
How to modernize legacy HL7 data in Amazon HealthLake

Healthcare providers and healthcare systems want to modernize their healthcare data exchanges so they can better analyze and gain more insight from their clinical data. These insights can help inform personalized and integrated patient care plans and more. But many healthcare systems still use legacy healthcare data transport standards that don’t support real-time analysis or exchange. Plus, much of their important clinical data resides in unstructured text formats that are challenging to effectively utilize as data. So how can healthcare systems modernize?
Amazon Web Services (AWS) provides a variety of services and solutions for healthcare providers to unlock the value of their data. In this walkthrough, learn how to use AWS to migrate legacy healthcare messaging data into Amazon HealthLake, which can use artificial intelligence (AI) and machine learning (ML) to discover meaningful and actionable healthcare information embedded in unstructured text.
Evolution of healthcare messaging standards
Health Level Seven (HL7) is a set of international standards meant to provide guidance with transferring and sharing data between various healthcare providers and the software applications they use in their practice. These standards are developed by Health Level Seven International, a nonprofit organization dedicated to providing a comprehensive framework for the exchange, integration, sharing, and retrieval of electronic health information to support clinical practice and the management, delivery, and evaluation of health services
Originally released in 1989, the HL7v2 standard became one of the most widely implemented healthcare messaging standards across the globe. According to HL7, 95% of US healthcare organizations and more than 35 countries still use a version of this standard. But customers that want insights into their healthcare data, or simply need a way to exchange it with partners or downstream applications, can find themselves restricted by HL7v2’s limited data exchange capabilities. It can be challenging to deal with legacy transport protocols like Minimum Lower Layer Protocol (MLLP) and the lack of reliable mechanisms for real-time query and response of data.
In 2014, HL7 introduced the Fast Healthcare Interoperability Resources (FHIR) standard. Based on emerging industry approaches and informed by years of lessons learned around requirements, FHIR aims to simplify implementation without sacrificing information integrity. FHIR also supports allowing patients to access their claims and clinical interaction information, including cost, as well as a defined subset of their clinical information through third-party applications of their choice.
Though the FHIR standard simplifies data exchange capabilities, many important health insights are embedded in data referred to as unstructured text. Studies have shown that over 80% of health data resides in unstructured text, which health information systems can’t directly use for predicting outcomes, recommending treatments, or analyzing trends. Unlike structured data, such as the demographic or treatment information on a patient’s electronic health record (EHR), unstructured data is hard to organize, categorize, and search. Some examples of unstructured data are laboratory and diagnostic imaging reports encoded in HL7v2 Observation Result (ORU) messages.
Modernizing HL7 data for insight analysis with Amazon HealthLake
Conversion between healthcare messaging transport layers is one of the first hurdles in the modernization and transformation journey from HL7v2 into FHIR. This blog post outlines a path from legacy HL7v2 ORU messaging into the HIPAA-eligible FHIR-supported service, Amazon HealthLake, using serverless services like AWS Lambda and Amazon API Gateway. Customers can migrate their legacy diagnostic imaging and laboratory results in HL7v2 ORU format and use Amazon HealthLake to provide insights into the unstructured data contained in the reports themselves. Using natural language processing (NLP) and ML, Amazon HealthLake maps information to ICD-10-CM and RxNorm terminology so it can become searchable and reportable.
Amazon HealthLake automatically uses the Amazon Comprehend Medical API operations DetectEntitiesV2, InferICD10CM, and InferRxNorm to detect entities found in the text of the DocumentReference FHIR resource.
The DocumentReference FHIR resource needs to be populated with a base64 encoded string representing the clinical note, diagnostic imaging report, or lab result in order to be ingested and analyzed by Amazon HealthLake. The proposed solution assists with this process in the following scenarios:
- Ingests HL7v2 ORU messages.
- When the inbound HL7 ORU message contains a single Observation/Result Segment (OBX) segment of type Text (TX), it will perform a base64 encode of field OBX-5, and a corresponding DocumentReference resource will be appended to the resulting FHIR Bundle.
- When the inbound HL7 ORU message contains multiple OBX segments of type TX, it will first join all instances of OBX-5, and a corresponding DocumentReference resource will be appended to the resulting FHIR Bundle.
- Only OBX segment types equal to TX will be modified.
At this time, only one Observation Request Segment (OBR) segment per HL7v2 ORU message is supported.
Solution walkthrough: How to migrate HL7v2 data into FHIR for AI and ML analysis in Amazon HealthLake
The following Figure 1 represents the high-level architecture of the proposed solution to migrate HL7v2 data into FHIR standards, and then move that data to Amazon HealthLake for AI and ML analysis. The steps of the architecture are described below:

Figure 1. This architecture diagram provides an overview of the end-to-end design. Individual steps are described below in the solution walkthrough section.
- An on-premises integration engine or clinical application with native HL7v2 ORU messaging capabilities wants to transmit HL7v2 data.
- An AWS Site-to-Site VPN encrypts traffic and secures the transmission of HL7v2 messages over public (and private) networks.
- A Network Load Balancer instance hosts the server side of the MLLP connection and distributes incoming messages across containers within its target group.
- AWS Fargate hosts container tasks running Apache Camel, whose main responsibility is to receive and acknowledge incoming HL7v2 messages. Once acknowledged, they are placed in an Amazon Simple Queue Service (Amazon SQS) standard queue.
- Amazon SQS provides decoupling of functions and allows for independent scalability of the message handling and message processing components of the solution.
- An AWS Lambda subscription to the Amazon SQS queue is invoked when a new HL7 message is available. It removes the message from the queue and begins the translation process.
- The FHIR converter AWS Lambda function takes an input in the form of an HL7v2 ORU message and returns a FHIR bundle that persists.
- Amazon HealthLake ingests the FHIR bundle, applies AI and ML on DocumentReference resources, and provides an endpoint for retrieval of healthcare data by downstream applications and consumers.
Prerequisites
For this walkthrough, you need the following prerequisites:
- An AWS account
- An AWS Cloud9 environment in the same region where you are planning on deploying the rest of the components. Amazon Healthlake is currently available in the U.S. East (N. Virginia), U.S. West (Oregon), and U.S. East (Ohio) regions. Make sure the AWS Cloud9 environment is deployed on an m5.xlarge Amazon Elastic Compute Cloud (Amazon EC2) instance or larger.
Deployment steps
The solution can be divided into three main areas:
- Message ingestion: This layer is in charge of acknowledging the receipt of incoming messages to the source and making them available for the message conversion layer. We outline the steps to configure a container and Amazon SQS-based approach, but the solution supports other methods, such as with Amazon Simple Storage Service (Amazon S3), as long as HL7 messages can be handed over for conversion.
- Message conversion: This layer is the core of the solution, and it’s being made available as an AWS Cloud Development Kit (AWS CDK) deployable package. Its main responsibility is accepting (or fetching) incoming HL7v2 ORU messages and performing a translation into FHIR.
- Message persistence: This layer is represented by the Amazon HealthLake service, responsible for the storage and the durability of translated FHIR resources.
Message ingestion
Assuming that the site-to-site VPN is in place and active, the first thing to stand up is an instance of a Network Load Balancer to handle inbound MLLP connections and distribute them across AWS Fargate container instances registered in the target group.
Once the load balancer and target group are in place, you can define the AWS Fargate task that will run the containers with Apache Camel. In this case, port 17000 was selected as the incoming traffic port. Lastly, an Amazon SQS standard queue will decouple the message ingestion and message conversion layers.
Find detailed instructions for outlining specific configuration steps in the blog post, “How to deploy HL7-based provider notifications on AWS Cloud.”
Message conversion
Next, our parsing and conversion logic is written in Python and NodeJS running on AWS Lambda. It starts triggering as soon as messages arrive in the Amazon SQS queue.
Figure 2. AWS Lambda function configured as an Amazon SQS trigger.
If the hl7receiver function fails to process a message multiple times (maxReceiveCount), Amazon SQS can send it to a previously configured dead-letter queue. These queues are useful for handling the lifecycle of unconsumed messages, determining why their processing didn’t succeed, and avoiding message loss.
To give messages a better chance to be processed before sending them to the dead-letter queue, set the maxReceiveCount on the source queue’s redrive policy to a value high enough to allow for sufficient retries.
As of December 1, 2021, the dead-letter queue management experience for Amazon SQS was enhanced, making it simpler for you to inspect a sample of the failed messages and move them back to the source queue for reprocessing with a click of a button.
As messages get parsed and converted from HL7v2 into HL7 FHIR, they will persist in Amazon HealthLake for durable storage and subsequent retrieval by consumers. As mentioned above, information embedded in the DocumentReference resource will be analyzed, and new insights will be made available as retrieval criteria.
A distribution package has been created so you can programmatically deploy the solution’s message conversion and message persistence layers directly into your AWS account. Source code, instructions, and dependencies are available in a github repository.
Data conversion and mapping is a dynamic process that, given the nature of HL7v2, varies from implementation to implementation. This blog post cannot be detailed enough to address all the potential variables and mappings one must consider when performing a data conversion from HL7v2 ORU messages to FHIR; therefore, thorough testing and validation must take place before deeming a mapping suitable for your specific requirements.
Message persistence
Once FHIR resources are persisted in Amazon HealthLake, they become durable and available for searching and bulk export. For example, take the following HL7v2 ORU radiology report fragment:
“Radiology Report History Cough Findings PA evaluation of the chest demonstrates the lungs to be expanded and clear. Conclusions Normal PA chest X-ray.“
When ingested by Amazon HealthLake, the following medical data is discovered and stored together with the rest of the converted FHIR resources:
- ICD-10 code R05 = Cough
- ICD-10 code R09.81 = Nasal Congestion
- System Organ Site (Anatomy) = Chest
- System Organ Site (Anatomy) = Lungs
- Treatment (procedure) = X-Ray
This medical data can now be used to search across all processed inbound messages, making actionable, traceable, and searchable information that was once lost in unstructured text, improving the quality of care and supporting population health initiatives.
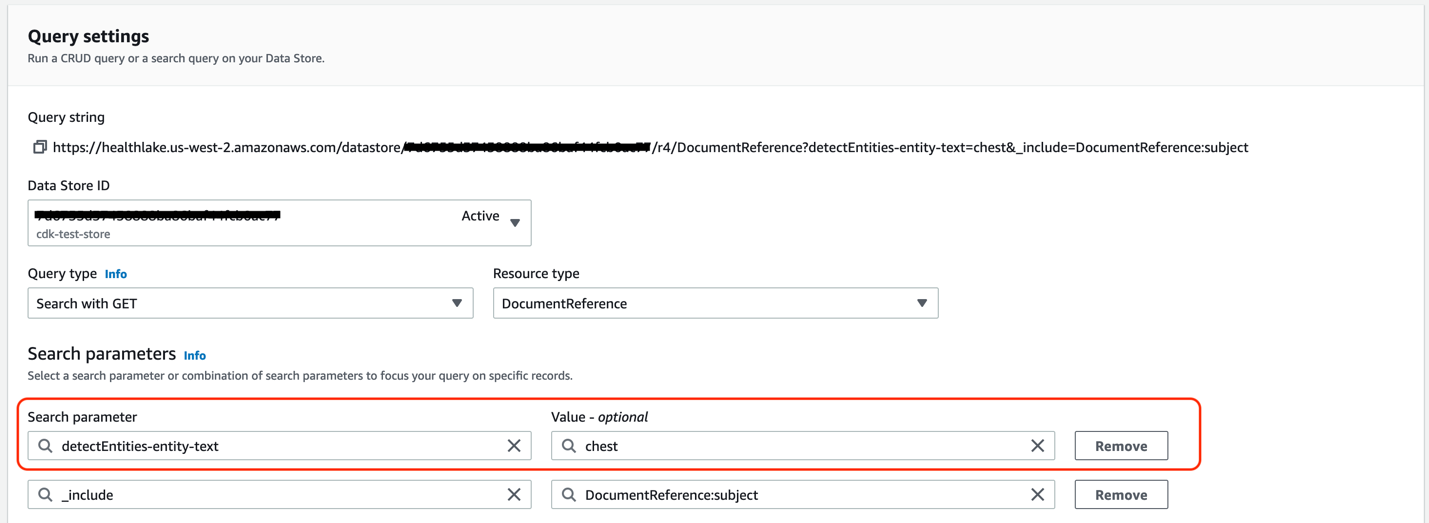
Figure 3. Amazon HealthLake used to query for terms discovered during message persistence. For example: detectedEntities-entity-text = chest.
By using Amazon HealthLake as your durable FHIR data store, you can increase your interoperability capabilities to improve the quality of patient care and take a step forward to meet or exceed interoperability regulations.
Conclusion
AWS serverless technologies and Amazon HealthLake can help modernize legacy HL7v2 messaging feeds into HL7 FHIR. Then, the AI and ML capabilities of Amazon Healthlake can help you discover meaningful and actionable healthcare information currently embedded in unstructured text.
The proposed solution does not require the deployment and maintenance of server infrastructure. All services are either managed by AWS or serverless. With AWS’s pay-as-you-go billing model and its depth and breadth of services, the cost and effort of initial setup and experimentation is significantly lower than traditional on-premises alternatives. You can review this pricing estimate based on a monthly analysis of 10 million report characters.
Begin your HL7 FHIR journey today. Explore the reusable artifacts available in this blog post and discover information embedded in your HL7v2 ORU messages. If you are a Center for Medicare and Medicaid Services (CMS)-regulated payer, you can help further your compliance efforts and adopt HL7 FHIR.
To learn more about the work AWS is doing in healthcare and life sciences across the globe, visit AWS for Health and AWS Healthcare Solutions. Interested in discussing your HL7 modernization project with AWS? Contact your AWS account manager, or send an inquiry to the AWS Public Sector Sales Team to learn more.
Read more about AWS for healthcare:
- How to deploy HL7-based provider notifications on AWS Cloud
- How to create a task-generating voicemail solution with Amazon Connect
- Getting started with healthcare data lakes: Using microservices
- Building a resilient and scalable clinical genomics analysis pipeline with AWS
- How KHUH built a long-term storage solution for medical image data with AWS
- Breaking down patient data silos in UK healthcare with serverless cloud technology
Subscribe to the AWS Public Sector Blog newsletter to get the latest in AWS tools, solutions, and innovations from the public sector delivered to your inbox, or contact us.
Please take a few minutes to share insights regarding your experience with the AWS Public Sector Blog in this survey, and we’ll use feedback from the survey to create more content aligned with the preferences of our readers.