AWS Public Sector Blog
Getting started with healthcare data lakes: Using microservices

Data lakes can help hospitals and healthcare organizations turn data into insights and maintain business continuity, while preserving patient privacy. A data lake is a centralized, curated, and secured repository that stores all your data, both in its original form and prepared for analysis. A data lake enables you to break down data silos and combine different types of analytics to gain insights and guide better business decisions.
This blog post is part of a larger series about getting started with setting up a healthcare data lake. In my last blog post in the series, “Getting started with healthcare data lakes: A deeper dive on Amazon Cognito,” I focused on the specifics of using Amazon Cognito and Attribute Based Access Control (ABAC) for user authentication and authorization in the healthcare data lake solution. In this blog post, I detail how the solution has evolved at a foundational level, including the design decisions I’ve made and the additional features used. You can access code samples for this solution through this GitHub repo for reference.
Architecture walkthrough
The primary change since the last presentation of the overall architecture is the splitting of the singular service into a collection of microservices to improve maintainability and agility. Integrating large amounts of disparate healthcare data typically requires specialized connecters for each format; by keeping these separately encapsulated with microservices, we can add, remove, and modify each connector without impacting the others. The microservices are loosely connected through centralized publish/subscribe messaging in what I refer to as a “pub/sub hub”.
This solution represents what I would consider another reasonable sprint-iteration from my last post. The scope remains limited to simple ingestion and parsing of Encoding Rules 7 (ER7) formatted HL7v2 messages via REST interface.
The solution architecture is now as follows:
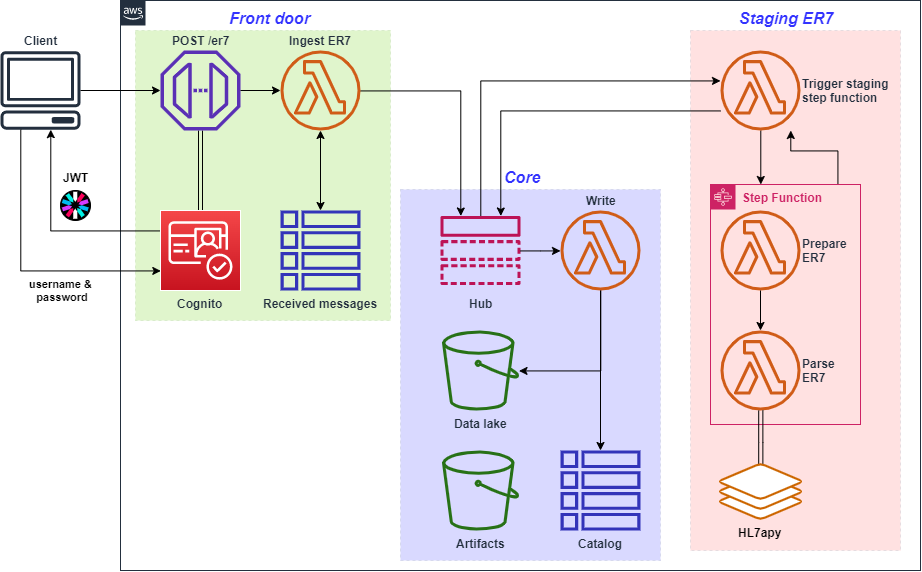
Figure 1. Overall solution architecture; colored boxes labelled “Front door,” “Core,” and “Staging ER7” represent now-distinct services.
While the term microservices has some inherent ambiguity, some characteristics are universal: they’re small, autonomous, loosely coupled, reusable, communicate through a well-defined interface, specialized to solve one thing, and are commonly deployed in event-driven architecture.
When determining where to draw boundaries between microservices, consideration should be made for intrinsic factors such as the technologies utilized and features like performance, reliability, and scalability; extrinsic factors such as functional dependencies, the frequency of change, and reusability; and human factors such as team ownership and managing cognitive load.
When selecting technologies and patterns to define microservices and the interface between them, you can reference the following communication scope to consider your options:
| Communication scope | Technologies / patterns to consider |
| Within a microservice | |
| Between microservices within a service | |
| Between services |
The pub/sub hub
The use of a hub-and-spoke style architecture (also known as a message broker) works well with a small number of closely related microservices. It helps keep functional dependencies to a minimum as each microservice is only reliant on the existence of the hub and coupling between microservices is limited to the content of messages published. As pub/sub is a unidirectional asynchronous ‘push’ style of communication, it minimizes synchronous calls.
Flexibility comes at a trade-off of structure. Subscribers to the ‘hub’ use message attributes and filtering to determine which messages to act on and which to ignore. Coordination and monitoring are thus still needed to avoid a microservice operating on a message it was not intended to.
Core microservice
The core microservice provides the foundational data and communication layer. It includes the following components:
- The Amazon Simple Storage Service (Amazon S3) data lake bucket
- The Amazon DynamoDB based data catalog, currently used for tracking data provenance
- An AWS Lambda function to write incoming messages to the data lake and catalog
- The Amazon SNS topic used as the ‘hub’ for microservice communication.
- An Amazon S3 bucket for artifacts such as code for Lambda functions
In this microservice, I chose to allow only indirect write access to the data lake and catalog through a self-contained function. This supports consistency and reduces the burden on other microservices, allowing them to focus on the ‘what’ to write and not on ‘how’ to write it.
Front door microservice
The front door microservice provides the API Gateway for external REST interaction and OpenID Connect (OIDC) based authentication and authorization through Amazon Cognito. The front door provides a mechanism for external users and services to communicate with this service and make sure that incoming messages are authenticated, authorized, and unique.
I focused on the technical details of how the OIDC uses Amazon Cognito in a prior blog post in this series and explained how the solution uses API Gateway in the post prior to that; you can refer to those posts for a walkthrough on those components.
For this microservice solution, I decided to use a self-managed message deduplication by keeping hashes of the incoming messages in a DynamoDB table instead of using native deduplication within Amazon SNS. I used self-managed for three reasons:
- Amazon SNS deduplication has a window of five minutes; working with HL7v2 can often be quirky, so I wanted a longer-term validation;
- Amazon SNS deduplication requires using First-In-First-Out (FIFO) topics and must be routed to FIFO Amazon SQS queues;
- By doing the deduplication upfront, the submitter can be notified that the message is a duplicate.
Staging ER7 microservice
This microservice provides the following:
- A “trigger” Lambda function is subscribed to the pub/sub hub and filters for messages which meet defined message attributes.
- A Step Functions Express Workflow is called to transform the messages from ER7 to JSON.
- The Step Function itself is comprised of two Lambda functions: the first applies common ER7 format corrections around newlines and carriage returns, and the second contains the parsing logic that’s largely remained the same since the first post in this series.
- If successful, the JSON result is passed back to the “trigger”; otherwise, the error message is passed back.
- Both successes and errors are pushed to the pub/sub hub with defining message attributes.
In the architecture I presented in a prior post, “Adding an ingress point and data management to your healthcare data lake,” I included the parsing functionality within the single Lambda function, and in that post, I noted that readers should consider breaking that function up. This is because it better adheres to the microservice principle of being highly specialized; encapsulates complicated logic away from the rest of the application; allows for reuse within the service (and potentially with other services); and allows for independent updating as additional corner cases arise or newer parsing libraries become available.
At larger scale—such as bulk ingests, multiple sources, and/or custom field mapping—the cleaning and parsing logic could grow into a full service unto itself. You could enhance it at that time by adding a private HTTP API integration.
New features used in the data lake solution
Managing dependencies with AWS CloudFormation cross-stack references
Each microservice is defined within its own CloudFormation stack and the dependencies between them, specifically with the ‘core’ microservice, are implemented through cross-stack references.
For example, within the CloudFormation template for the core microservice, the following outputs are included:
Within a dependent microservice, CloudFormation can import these output values when a reference is needed. For example, within the front door microservice template, the name of the core stack is passed in as a parameter when creating or updating the stack:
I find this—for now—to be the right balance of autonomy and simplicity, as most modifications can be performed without interfering with other microservices.
Amazon SNS message filtering
The solution is using a single Amazon SNS message topic for the “pub/sub hub”, where each microservice sends to a central topic and other microservices subscribe based on their message filtering policy.
An example of the filtering from the staging microservice is as follows:
Deploying and testing
Prerequisites
To deploy this project, you need:
- An AWS account with adequate permissions. If you do not have an AWS account, create and activate one
- The AWS Command Line Interface (CLI)
- Basic knowledge of Python scripting. The scripts used for both coding and deployment are in Python and we use “boto3“, the AWS SDK for Python.
Environment setup
Use AWS Cloud9 as the development environment:
1. Setup Cloud9 as per the “Creating an EC2 Environment” instructions.
2. Clone the Git repository:
git clone -b blog_4 https://github.com/aws-samples/hcls-data-lake.git
3. Switch to the new ‘hcls-data-lake’ directory and then configure the Cloud9 environment:
sh cloud9_init.sh
4. Deploy the services. Replace “$MY_STACK_NAME” with a name of your choice. This takes several minutes to complete.
python deploy_services.py -s $MY_STACK_NAME
Improvements have been made to the deployment script so that after the core microservice is deployed, the front door and staging microservices are deployed in parallel instead of in series. Because this operation is asynchronous, the simplest way to check the deployment status is to check the CloudFormation service in the console.
Testing
Within the code cloned from the Git repo is a script which contains code to create a few sample users with differing access and attempts to send several HL7v2 messages to the front door microservice.
python test_services.py -s $MY_STACK_NAME
After running this client script, results are returned by the service indicating which messages were successfully ingested and stored, which were denied due to inadequate authorization, and which were denied for being duplicates.
Being an asynchronous call, to find the results of the staging microservice, go through the console and view objects in the Amazon S3 bucket that was created.
Clean up
As deploying this project creates multiple CloudFormation stacks, the scripts also include convenience functionality to delete them. Note that they also delete any objects placed in the buckets that were created as part of the stacks.
python deploy_services.py -s $MY_STACK_NAME -d
Like the initial deployment, the deletion also takes better advantage of parallelism. The front door and staging microservices are deployed in parallel before the core microservice is then deleted.
Summary and next steps
In this blog, I went over the architecture of the data lake as it currently stands, covered several of the technologies used to provided greater decoupling, and provided my rationale for the design decisions that have been made.
Do you have any questions about how to set up a healthcare data lake? Reach out to the AWS Public Sector Team for help.
Read more about AWS for healthcare:
- Getting started with a healthcare data lake
- Adding an ingress point and data management to your healthcare data lake
- Getting started with healthcare data lakes: A deeper dive on Amazon Cognito
- Wellforce announces migration of the health system’s digital healthcare ecosystem to AWS
- Delivering secure and operational telemedicine for military combat training with AWS
- AWS launches next AWS Healthcare Accelerator to propel startup innovation in health equity
Subscribe to the AWS Public Sector Blog newsletter to get the latest in AWS tools, solutions, and innovations from the public sector delivered to your inbox, or contact us.
Please take a few minutes to share insights regarding your experience with the AWS Public Sector Blog in this survey, and we’ll use feedback from the survey to create more content aligned with the preferences of our readers.