AWS Big Data Blog
How a blockchain startup built a prototype solution to solve the need of analytics for decentralized applications with AWS Data Lab
February 9, 2024: Amazon Kinesis Data Firehose has been renamed to Amazon Data Firehose. Read the AWS What’s New post to learn more.
This post is co-written with Dr. Quan Hoang Nguyen, CTO at Fantom Foundation.
Here at Fantom Foundation (Fantom), we have developed a high performance, highly scalable, and secure smart contract platform. It’s designed to overcome limitations of the previous generation of blockchain platforms. The Fantom platform is permissionless, decentralized, and open source. The majority of decentralized applications (dApps) hosted on the Fantom platform lack an analytics page that provides information to the users. Therefore, we would like to build a data platform that supports a web interface that will be made public. This will allow users to search for a smart contract address. The application then displays key metrics for that smart contract. Such an analytics platform can give insights and trends for applications deployed on the platform to the users, while the developers can continue to focus on improving their dApps.
AWS Data Lab offers accelerated, joint-engineering engagements between customers and AWS technical resources to create tangible deliverables that accelerate data and analytics modernization initiatives. Data Lab has three offerings: the Build Lab, the Design Lab, and a Resident Architect. The Build Lab is a 2–5 day intensive build with a technical customer team. The Design Lab is a half-day to 2-day engagement for customers who need a real-world architecture recommendation based on AWS expertise, but aren’t yet ready to build. Both engagements are hosted either online or at an in-person AWS Data Lab hub. The Resident Architect provides AWS customers with technical and strategic guidance in refining, implementing, and accelerating their data strategy and solutions over a 6-month engagement.
In this post, we share the experience of our engagement with AWS Data Lab to accelerate the initiative of developing a data pipeline from an idea to a solution. Over 4 weeks, we conducted technical design sessions, reviewed architecture options, and built the proof of concept data pipeline.
Use case review
The process started with us engaging with our AWS Account team to submit a nomination for the data lab. This followed by a call with the AWS Data Lab team to assess the suitability of requirements against the program. After the Build Lab was scheduled, an AWS Data Lab Architect engaged with us to conduct a series of pre-lab calls to finalize the scope, architecture, goals, and success criteria for the lab. The scope was to design a data pipeline that would ingest and store historical and real-time on-chain transactions data, and build a data pipeline to generate key metrics. Once ingested, data should be transformed, stored, and exposed via REST-based APIs and consumed by a web UI to display key metrics. For this Build Lab, we choose to ingest data for Spooky, which is a decentralized exchange (DEX) deployed on the Fantom platform and had the largest Total Value Locked (TVL) at that time. Key metrics such number of wallets that have interacted with the dApp over time, number of tokens and their value exchanged for the dApp over time, and number of transactions for the dApp over time were selected to visualize through a web-based UI.
We explored several architecture options and picked one for the lab that aligned closely with our end goal. The total historical data for the selected smart contract was approximately 1 GB since deployment of dApp on the Fantom platform. We used FTMScan, which allows us to explore and search on the Fantom platform for transactions, to estimate the rate of transfer transactions to be approximately three to four per minute. This allowed us to design an architecture for the lab that can handle this data ingestion rate. We agreed to use an existing application known as the data producer that was developed internally by the Fantom team to ingest on-chain transactions in real time. On checking transactions’ payload size, it was found to not exceed 100 kb for each transaction, which gave us the measure of number of files that will be created once ingested through the data producer application. A decision was made to ingest the past 45 days of historic transactions to populate the platform with enough data to visualize key metrics. Because the feature of backdating exists within the data producer application, we agreed to use that. The Data Lab Architect also advised us to consider using AWS Database Migration Service (AWS DMS) to ingest historic transactions data post lab. As a last step, we decided to build a React-based webpage with Material-UI that allows users to enter a smart contract address and choose the time interval, and the app fetches the necessary data to show the metrics value.
Solution overview
We collectively agreed to incorporate the following design principles for the data lab architecture:
- Simplified data pipelines
- Decentralized data architecture
- Minimize latency as much as possible
The following diagram illustrates the architecture that we built in the lab.
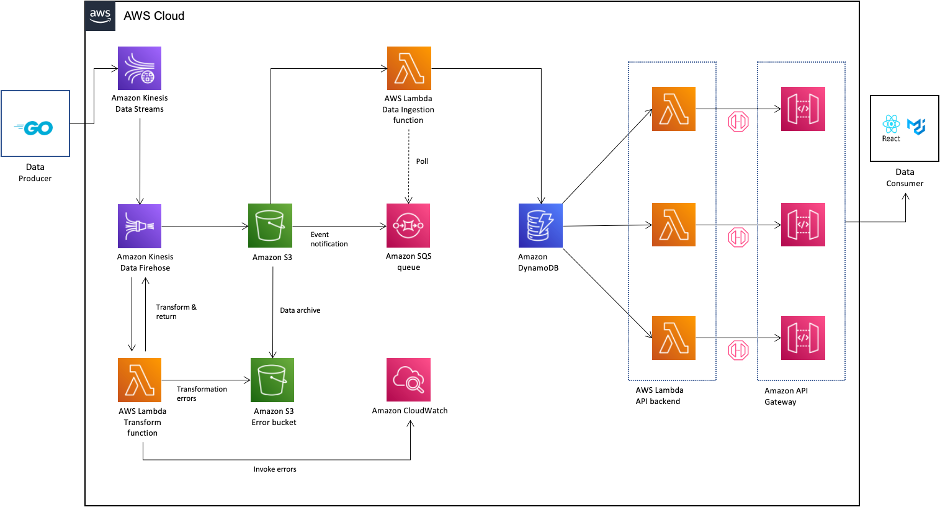
We collectively defined the following success criteria for the Build Lab:
- End-to-end data streaming pipeline to ingest on-chain transactions
- Historical data ingestion of the selected smart contract
- Data storage and processing of on-chain transactions
- REST-based APIs to provide time-based metrics for the three defined use cases
- A sample web UI to display aggregated metrics for the smart contract
Prior to the Build Lab
As a prerequisite for the lab, we configured the data producer application to use the AWS Software Development Kit (AWS SDK) and PUTRecords API operation to send transactions data to an Amazon Simple Storage Service (Amazon S3) bucket. For the Build Lab, we built additional logic within the application to ingest historic transactions data together with real-time transactions data. As a last step, we verified that transactions data was captured and ingested into a test S3 bucket.
AWS services used in the lab
We used the following AWS services as part of the lab:
- AWS Identity and Access Management (IAM) – We created multiple IAM roles with appropriate trust relationships and necessary permissions that can be used by multiple services to read and write on-chain transactions data and generated logs.
- Amazon S3 – We created an S3 bucket to store the incoming transactions data as JSON-based files. We created a separate S3 bucket to store incoming transaction data that failed to be transformed and will be reprocessed later.
- Amazon Kinesis Data Streams – We created a new Kinesis data stream in on-demand mode, which automatically scales based on data ingestion patterns and provides hands-free capacity management. This stream was used by the data producer application to ingest historical and real-time on-chain transactions. We discussed having the ability to manage and predict cost, and therefore were advised to use the provisioned mode when reliable estimates were available for throughput requirements. We were also advised to continue to use on-demand mode until the data traffic patterns were unpredictable.
- Amazon Kinesis Data Firehose – We created a Firehose delivery stream to transform the incoming data and writes it to the S3 bucket. To minimize latency, we set the delivery stream buffer size to 1 MiB and buffer interval to 60 seconds. This would ensure a file is written to the S3 bucket when either of the two conditions are satisfied regardless of the order. Transactions data written to the S3 bucket was in JSON Lines format.
- Amazon Simple Queue Service (Amazon SQS) – We set up an SQS queue of the type Standard and an access policy for that SQS queue to allow incoming messages generated from S3 bucket event notifications.
- Amazon DynamoDB – In order to pick a data store for on-chain transactions, we needed a service that can store transactions payload of unstructured data with varying schemas, provides the ability to cache query results, and is a managed service. We picked DynamoDB for those reasons. We created a single DynamoDB table that holds the incoming transactions data. After analyzing the access query patterns, we decided to use the address field of the smart contract as the partition key and the timestamp field as the sort key. The table was created with auto scaling of read and write capacity modes because the actual usage requirements would be hard to predict at that time.
- AWS Lambda – We created the following functions:
- A Python-based Lambda function to perform transformations on the incoming data from the data producer application to flatten the JSON structure, convert the Unix-based epoch timestamp to a date/time value, and convert hex-based string values to a decimal value representing the number of tokens.
- A second Lambda function to parse incoming SQS queue messages. This message contained values for
bucket_nameandobject_key, which holds the reference to a newly created object within the S3 bucket. The Lambda function logic included parsing of this value to obtain the reference to the S3 object, get the contents of the object, read it into a data frame object using the AWS SDK for pandas (awswrangler) library, convert it into a Pandas data frame object, and use the put_df API call to write a Pandas data frame object as an item into a DynamoDB table. We choose to use Pandas due to familiarity with the library and functions required to perform data transform operations. - Three separate Lambda functions that contains the logic to query the DynamoDB table and retrieve items to aggregate and calculate metrics values. This calculated metrics value within the Lambda function was formatted as an HTTP response to expose as REST-based APIs.
- Amazon API Gateway – We created a REST based API endpoint that uses Lambda proxy integration to pass a smart contract address and time-based interval in minutes as a query string parameter to the backend Lambda function. The response from the Lambda function was a metrics value. We also enabled cross-origin resource sharing (CORS) support within API Gateway to successfully query from the web UI that resides in a different domain.
- Amazon CloudWatch – We used a Lambda function in-built mechanism to send function metrics to CloudWatch. Lambda functions come with a CloudWatch Logs log group and a log stream for each instance of your function. The Lambda runtime environment sends details of each invocation to the log stream, and relays logs and other output from your function’s code.
Iterative development approach
Across 4 days of the Build Lab, we undertook iterative development. We started by developing the foundational layer and iteratively added extra features through testing and data validation. This allowed us to develop confidence of the solution being built as we tested the output of the metrics through a web-based UI and verified with the actual data. As errors got discovered, we deleted the entire dataset and reran all the jobs to verify results and resolve those errors.
Lab outcomes
In 4 days, we built an end-to-end streaming pipeline ingesting 45 days of historical data and real-time on-chain transactions data for the selected Spooky smart contract. We also developed three REST-based APIs for the selected metrics and a sample web UI that allows users to insert a smart contract address, choose a time frequency, and visualize the metrics values. In a follow-up call, our AWS Data Lab Architect shared post-lab guidance around the next steps required to productionize the solution:
- Scaling of the proof of concept to handle larger data volumes
- Security best practices to protect the data while at rest and in transit
- Best practices for data modeling and storage
- Building an automated resilience technique to handle failed processing of the transactions data
- Incorporating high availability and disaster recovery solutions to handle incoming data requests, including adding of the caching layer
Conclusion
Through a short engagement and small team, we accelerated this project from an idea to a solution. This experience gave us the opportunity to explore AWS services and their analytical capabilities in-depth. As a next step, we will continue to take advantage of AWS teams to enhance the solution built during this lab to make it ready for the production deployment.
Learn more about how the AWS Data Lab can help your data and analytics on the cloud journey.
About the Authors
 Dr. Quan Hoang Nguyen is currently a CTO at Fantom Foundation. His interests include DLT, blockchain technologies, visual analytics, compiler optimization, and transactional memory. He has experience in R&D at the University of Sydney, IBM, Capital Markets CRC, Smarts – NASDAQ, and National ICT Australia (NICTA).
Dr. Quan Hoang Nguyen is currently a CTO at Fantom Foundation. His interests include DLT, blockchain technologies, visual analytics, compiler optimization, and transactional memory. He has experience in R&D at the University of Sydney, IBM, Capital Markets CRC, Smarts – NASDAQ, and National ICT Australia (NICTA).
 Ankit Patira is a Data Lab Architect at AWS based in Melbourne, Australia.
Ankit Patira is a Data Lab Architect at AWS based in Melbourne, Australia.