Amazon Web Services ブログ
Category: Analytics

[開催報告]AWS Summit Japan 2025 生成AIエージェントハッカソン
はじめに 6月25日~26日に開催されたAWS Summit Japan 2025において、「生成AIエージェ […]

IAM Identity Center を使用した Amazon OpenSearch Service の信頼されたアイデンティティ伝播
この記事では、IAM Identity Center の信頼されたアイデンティティ伝播を使用して Amazon OpenSearch Service のデータに安全にアクセスする方法を説明します。この新しいアクセス方法により、SAML ベースのアプローチと比較して認証フローが簡素化され、OpenSearch UI を通じたシームレスなデータアクセスと堅牢なロールベースのアクセス制御を実現できます。
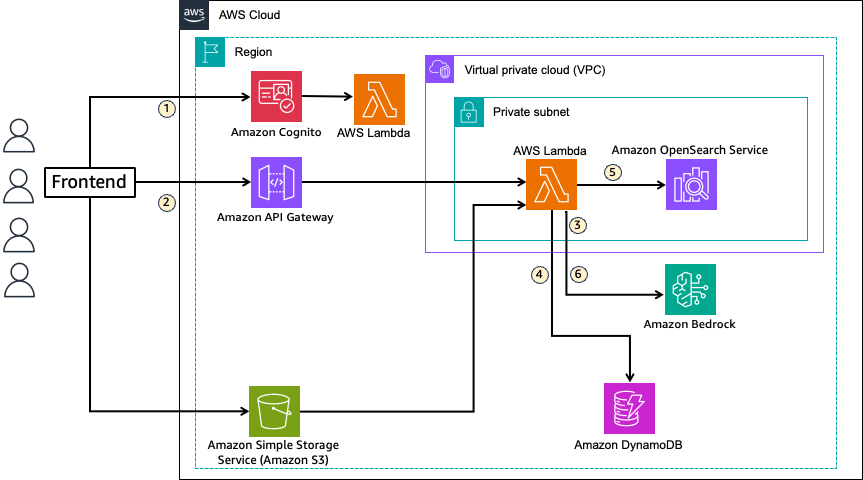
JWT を使用した Amazon Bedrock と Amazon OpenSearch Service による SaaS 向けマルチテナント RAG 実装
本ブログでは、RAG 実装で使用される Vector DB の一つである Amazon OpenSearch Service を例に、JSON Web Token(JWT)と FGAC を組み合わせたテナント分離パターンとテナントリソースへのルーティング方法を紹介します。

Amazon S3 Vectors と Amazon OpenSearch Service によるベクトル検索の最適化
ベクトル埋め込みと類似度検索機能の進歩に伴い、データの保存と検索方法が急速に進化しています。ベクトル検索は、生成 AI やエージェント AI などの最新のアプリケーションにとって不可欠なものとなっています。しかし、大規模なベクトルデータを管理することは大きな課題があります。組織は、数百万または数十億ものベクトル埋め込みを保存して検索する際、レイテンシー、コスト、精度のトレードオフに悩まされることが多くあります。従来のソリューションでは、大規模なインフラストラクチャの管理が必要になるか、データ量が増えるにつれて非常に高額なコストがかかります。
私たちは、Amazon Simple Storage Service (Amazon S3) Vectors と Amazon OpenSearch Service の 2 つの統合機能のパブリックプレビューを公開しました。これにより、ベクトル埋め込みをより柔軟に格納および検索することができるようになります。

AWS AI League: 新しい究極の AI 対決で学習し、イノベーションを起こし、競い合う
2018 年以来、AWS DeepRacer は世界中で 560,000 人超のビルダーを魅了し、デベロッパー […]

新しい Amazon EventBridge のログ記録を使用して、イベントドリブンのアプリケーションをモニタリングおよびデバッグする
7 月 15 日より、Amazon EventBridge の拡張ログ記録機能を使用して、包括的なログでイベン […]

Amazon SageMaker Catalog の新機能を使用して、データからインサイトを得るプロセスを効率化
現代の組織は、構造化データベース、非構造化ファイル、個別のビジュアライゼーションツールなど、複数の分断されたシ […]

OpenSearch ベースのマルチテナント集中ログプラットフォームにおけるワークロード管理
この記事では、OpenSearch ベースのマルチテナント集中ログプラットフォームにおけるワークロード管理について説明します。ルールベースのプロキシと OpenSearch ワークロード管理を使用した多層フレームワークにより、多様なテナントワークロードに対する効率的なリソース割り当てとパフォーマンス分離を実現する方法を紹介します。
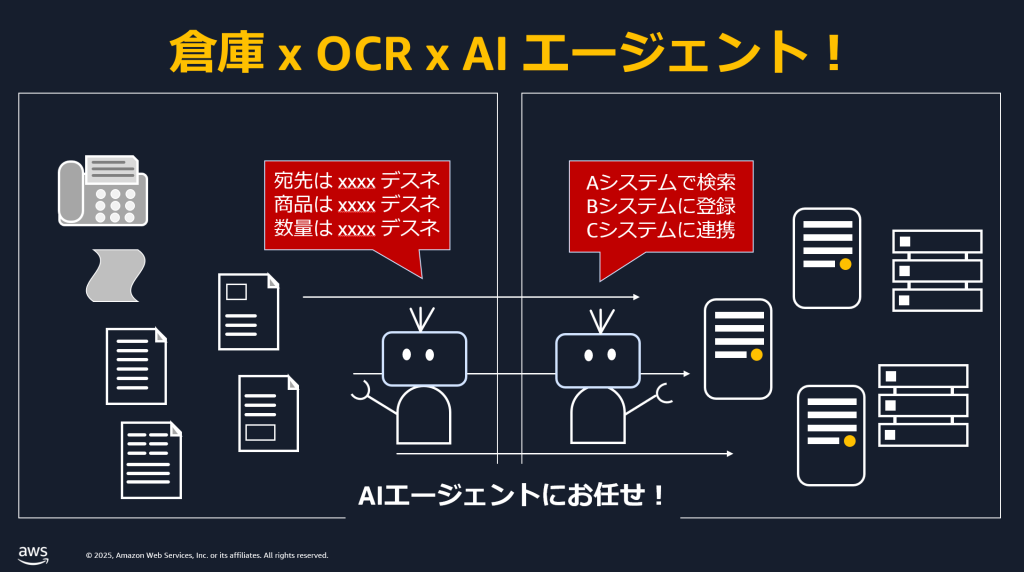
【開催報告】AWS Summit Japan 2025 物流業界向けブース展示 「倉庫 x OCR x 生成 AI エージェント」
6月 24 日と 25 日の 2 日間にわたり、幕張メッセにおいて 14 回目となる AWS Summit J […]

通信事業者が提供するSmart-Xのための協調AIエージェントによる分散推論
本稿は、2025年3月20日に AWS for industriesで公開された “Distributed i […]