AWS Partner Network (APN) Blog
Accelerate Data Warehousing by Streaming Data with Confluent Cloud into Amazon Redshift
By Jobin George, Sr. Partner Solutions Architect at AWS
By Michael Coughlin, Director, Global Partner Solutions at Confluent
By Joseph Morais, AWS Evangelist, Global Partner Solutions at Confluent
 |
| Confluent |
 |
There has been tremendous adoption of Apache Kafka throughout the years, and developers are increasingly using Kafka as the foundation for their event streaming applications.
Today, developers of cloud applications need access to a fully managed Apache Kafka service that frees them from operational complexities so they don’t need expertise to use the technology.
Built as a cloud-native service, Confluent Cloud offers developers a serverless experience with elastic scaling and pricing that charges only for what they stream. Adoption of Confluent Cloud is increasing by developers who want simpler ways of building event-driven applications that demand real- and near real-time data ingestion into cloud data warehouses.
To help meet those demands, Kafka Connect Amazon Redshift Sink Connector from Confluent Cloud exports Avro, JSON Schema, or Protobuf data from Apache Kafka topics to Amazon Redshift. The connector polls data from Kafka and writes this data to an Amazon Redshift database. Polling data is based on subscribed topics.
Confluent is an AWS ISV Partner with Amazon Redshift Service Ready and AWS Outposts Service Ready designations. Founded by the team that originally created Apache Kafka, Confluent builds an event streaming platform that enables companies to easily access data as real-time streams.
In this post, we provide an overview of Confluent Cloud, and step-by-step instructions to stream data with Confluent Cloud Kafka into an Amazon Redshift table.
About Confluent Cloud
Confluent Cloud is a scalable, resilient, and secure event streaming platform powered by Apache Kafka. On top of fully managed Kafka, Confluent Cloud provides a number of other services that allow both operators and developers to focus on building applications instead of managing clusters.
Confluent offers a complete ecosystem that includes:
- Apache Kafka – An open-source distributed event streaming platform capable of handling trillions of events a day. Initially conceived as a messaging queue, Kafka is based on an abstraction of a distributed commit log. Since being created and open sourced by LinkedIn in 2011, Kafka has evolved into a full-fledged event streaming platform.
. - Confluent Replicator – Allows you to easily and reliably replicate topics from one Kafka cluster to another across different environments and regions. It continuously copies the messages in multiple topics and, when necessary, creates the topics in the destination cluster using the same topic configuration as the source cluster.
. - Connect/Connectors – Allows users to instantly connect popular data sources and sinks. Confluent has a catalog of 100+ fully supported connectors, including JDBC, Amazon Redshift, Amazon Simple Storage Service (Amazon S3), Amazon OpenSearch Service (successor to Amazon Elasticsearch Service), MongoDB, Salesforce, Debezium, MQTT, and more.
. - Schema Registry – A central repository with a RESTful interface for developers to increase data integrity by enforcing a consistent data structure on your events in Kafka as a way to prevent application incompatibility that can disrupt consumers.
. - ksqlDB – A new kind of database, purpose-built for stream processing apps. It allows you to build stream processing applications against data in Kafka, enhancing developer productivity. ksqlDB makes it easy to develop real-time ETL pipelines by providing a lightweight SQL syntax to join, transform, and enrich streaming data. It also simplifies maintenance, and provides a smaller but powerful code base that can add serious rocket fuel to event-driven architectures.
. - Metrics API – Provides actionable operational metrics about your Confluent Cloud deployment. This is a queryable HTTP API in which the user
POSTs a query written in JSON and gets back a time-series of metrics specified by the query.

Figure 1 − Services within Confluent Cloud.
These services turn event streaming into the central nervous system of your business. With a single platform, you can simplify the integration between data streams from web or IoT, event-driven applications, AWS services, and complex data analytics with Amazon Redshift.
You can even migrate workloads to the cloud and modernize your application architecture without lifting and shifting applications. Whether your on-premises infrastructure includes mainframes, relational databases, or monolithic applications, you can capture all the events of your complex ecosystem locally.
You can then replicate to Confluent Cloud to build out new event-driven applications with cloud-native design principles across the suite of AWS services.
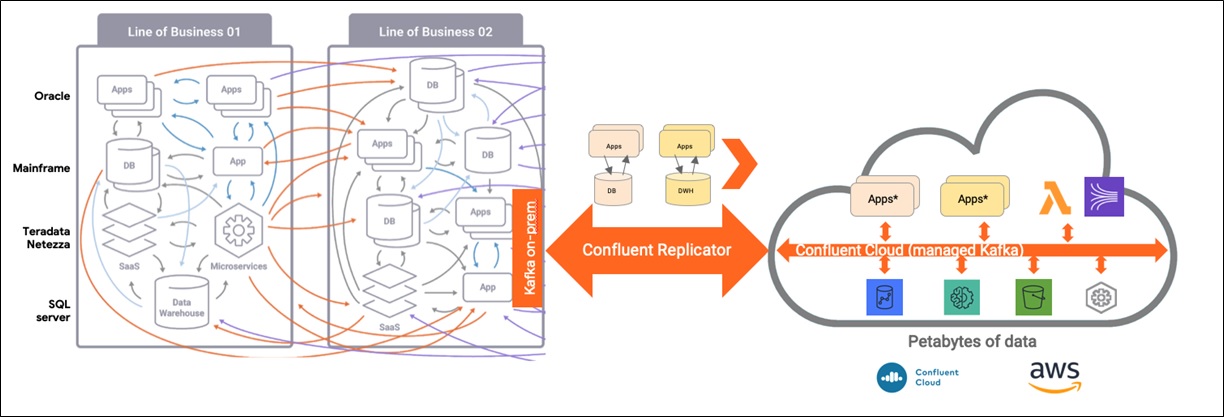
Figure 2 − Migration architecture of legacy applications and databases without lift and shift
Kafka Connect
The Kafka Connect Amazon Redshift Sink connector allows you to stream data from Apache Kafka topics to Amazon Redshift. The connector polls data from Kafka and writes this data to an Amazon Redshift database. Polling data is based on subscribed topics. Auto-creation of tables and limited auto-evolution are supported.
Following, we’ll show you how to create a Kafka cluster in Confluent Cloud, stream data from an AWS Lambda streaming function, and ingest data into Amazon Redshift via the connector provided by Confluent Cloud.
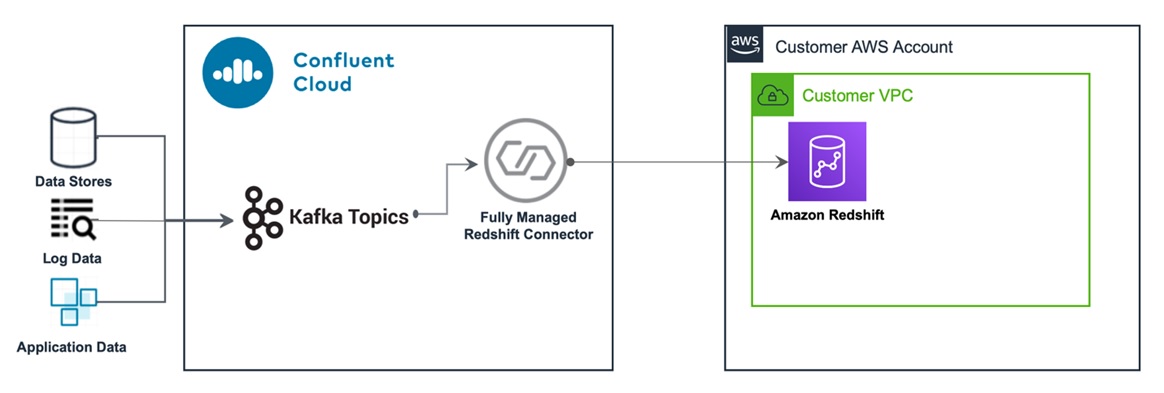
Figure 3 − How data is streamed from Confluent Cloud to Amazon Redshift
How to Set Up Data Streaming
The procedure consists of six steps:
- Create the AWS resources.
- Create the Confluence Cloud resources.
- Enable the Schema Registry for Confluent Cloud, and create API keys.
- Configure the Confluent Cloud Amazon Redshift Sink Connector.
- Launch the AWS Lambda streaming function to ingest data into the Kafka topic.
- Preview data ingested into Amazon Redshift table.
Prerequisites
- An active AWS account. If you don’t have one, create and activate a new AWS account.
- An active Confluent Cloud account. To get one, subscribe and sign up using Confluent Cloud on AWS Marketplace.
Creating a Confluent Cloud Account on AWS Marketplace
If you don’t already have an active Confluence Cloud account, navigate to AWS Marketplace and find Apache Kafka on Confluent Cloud – Pay As You Go. Select the Continue to Subscribe button.
On the next page, review the pricing details and select the Subscribe button.
Next, to create an account, select the Set Up Your Account button on the pop-up window.
You are redirected to a Confluent Cloud page. Provide the required details and create your account. Once created, you can use this account to carry out the remainder of this procedure.
Note that when you sign up, you get a monthly $200.00 USD credit for the first three months.
Step 1: Create the AWS Resources
Spin up the AWS resources you need with the following AWS CloudFormation script. It deploys:
- A new virtual private cloud (VPC).
. - An Amazon Redshift cluster. If you are just experimenting with this procedure, configure it to be publicly accessible. In a production scenario, you would use VPC Peering or AWS PrivateLink for secure connectivity.
. - An AWS Lambda function that simulates streaming data, converts JSON records read from an Amazon S3 bucket to Avro format, and publishes into the Kafka cluster running on Confluent Cloud.
To launch that AWS CloudFormation script, select this Launch Stack image:

On the Quick Create Stack page that appears, acknowledge the resource creations and select Create Stack. It may take a few minutes to complete the stack creation. The stack name is already populated as Confluent-Redshift-Connector.
Once the stack is created, navigate to the Stack Output tab and write down the values of RedshiftEndPoint and StreamingFunctionName. You’ll need them in subsequent steps.

Figure 4 – Write down the values of RedShiftEndpoint and StreamingFunctionName.
Step 2: Create Confluent Cloud Resources
To create the Confluent Cloud resources, follow these instructions:
a. Create a Kafka cluster
b. Create a Kafka topic
c. Create Kafka API keys
2a. Create a Kafka Cluster
Open another tab or window on your browser and launch Confluent Cloud Console.
Log in, and then select the Create Cluster icon on the screen to create a new Kafka cluster. If you already have a cluster, you can simply create a new topic to use in this procedure.
On the page that appears, provide a name for the cluster. We used Data2Redshift.
Select Amazon Web Service as the provider, us-east-1 as the Region, and then select Continue.

Figure 5 – Enter cluster particulars.
In a few minutes, your cluster is ready to use. Once the cluster is created, navigate to Cluster Settings and write down the Bootstrap Server address. You need it for subsequent steps.
2b. Create a Kafka Topic
To create a Kafka topic, select the cluster, and then Topics on the left navigation bar. Enter a name; we used redtopic.
Select the number of partitions required; the default is 6.
Finally, select Create with Defaults.
2c. Creat Kafka API Keys
Once the topic is created, select Kafka API Keys in the left navigation bar. Then, select Create Key. If you are not a first time Confluent Cloud user, and you already have a key, you can use the same key or create a special key one for this procedure.

Figure 6 – Create Kafka API key.
When the Create an API Key pop-up appears, note down the Key and Secret before selecting Continue, as you will not be able to view the secret once the pop-up closes. You need it for later steps.

Figure 7 – Write down the Key and Secret before selecting Continue.
Step 3: Enable Schema Registry for Confluent Cloud and Create API Keys
Select Schemas on the navigation bar, choose AWS as the cloud provider, US as the region, and then select Enable Schema Registry.
Write down the Schema Registry endpoint URL. You need it for later steps.
Select Manage API Keys as shown in Figure 8. If you are not a first time Confluent Cloud user, and you already have a key, you can use the same key or create a new key for this procedure.

Figure 8 – Write down the Schema Registry Endpoint URL.
On the API Access tab, select Create Key.
When the Create a new Schema Registry API Key window appears, note down the Key and Secret. You will not be able to view the secret once the pop-up closes, and you need both in later steps.
After writing down the key and secret, select Continue.
Step 4: Configure Confluent Cloud Amazon Redshift Sink Connector
Navigate back to the cluster and select Connectors on the left navigation bar. From the options, select Amazon Redshift Sink.

Figure 9 – Select Amazon Redshift Sink.
The screen for the Amazon Redshift Sink Connector Sink appears next.
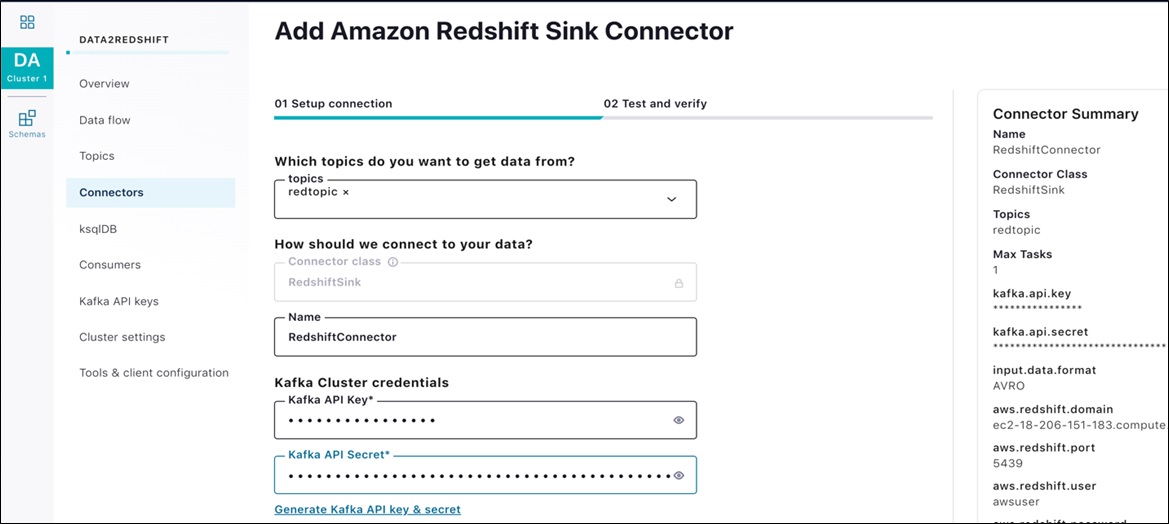
Figure 10 – Amazon Redshift Sink Connector screen.
Configure the Sink Connector with the following values. You can leave rest of the fields on the page at their default values.
| Topics | redtopic |
| Name | RedshiftConnector |
| Kafka API key | <kafka_key> |
| Kafka API secret | <kafka_secret> |
| Input Message Format | Avro |
| Amazon Redshift Domain | <redshift host from AWS CloudFormation output> |
| Amazon Redshift Port | 5439 |
| Connection User | awsuser |
| Connection Password | Awsuser01 |
| Database Name | streaming-data |
| Database Timezone | <select your timezone> |
| Auto Create Table | True |
| Auto Add Columns | True |
| Tasks | 1 |
Select Continue to proceed. On the test and verify page, select Launch to deploy the connector.

Figure 11 – Launch Amazon Redshift Sink Connector.
In a few minutes, the connector indicates it is running. You can now begin streaming.
Step 5: Launch AWS Lambda Streaming Function to Ingest Data into Kafka Topic
Navigate back to the AWS CloudFormation Resources page, select Confluent-Redshift-Blog, and go to the Resources tab.
Under the Physical ID column, select ConfluentStreamingFunction to launch the AWS Lambda console.

Figure 12 – Select ConfluentStreamingFunction link.
While in the AWS Lambda console, select the Test button on the top right corner to simulate streaming data.
On the configure test event pop-up window, enter the following JSON record:
{
"BOOTSTRAP_SERVERS": "<YOUR_KAFKA_BOOTSTRAP_SERVER>",
"API_KEY": "<YOUR_KAFKA_API_KEY>",
"API_SECRET": "<YOUR_KAFKA_API_SECRET>",
"SR_URL": " <YOUR_SCHEMA_REGISTRY_URL>",
"SR_AUTH_KEY": "<YOUR_SCHEMA_REGISTRY_KEY>",
"SR_AUTH_SECRET": "<YOUR_SCHEMA_REGISTRY_SECRET>",
"BUCKET": "streaming-data-repo",
"TOPIC": "[12] redtopic"
}
Provide a name for the test event, and select Save to create the test event.

Figure 13 – Enter a name for the test event.
Once saved, select Test again to launch the function to stream data into the Kafka topic provided in the configuration. The function runs for two minutes, then stops. Timeout is set at two minutes to make sure streaming is stopped to avoid consuming excess resources. You can change it in Lambda console.
Step 6: Preview the Data Ingested into the Amazon Redshift Table
To verify the data loaded into the Amazon Redshift table, from the AWS console, navigate to Amazon Redshift Query Editor. If you left the Amazon Redshift Connector configurations to default, the table will have the same name as the topic.
Use these credentials to connect to the Query Editor:
| Connection User | awsuser |
| Connection password | Awsuser01 |
| Database name | streaming-data |
Once in the Amazon Redshift Query Editor, select the cluster and log in with the Amazon Redshift cluster credentials you wrote down earlier. Select the Public schema, and choose the redtopic table. Right-select, and choose the Preview Data option.

Figure 14 – Choose the Preview Data option.
You should now be able to view the data streamed by the Amazon Redshift connector. You may simply query the data or connect to Amazon QuickSight to start visualizing it.
Clean Up
- Once you complete the exercise, delete the topic and cluster you created in Confluent Cloud so you don’t incur any additional charges for resources.
. - Remember to clean up all AWS resources that you created using AWS CloudFormation. Use the CloudFormation console or AWS Command Line Interface (CLI) to delete the stack named Confluent-Redshift-Connector.
Conclusion
Confluent Cloud provides a serverless way to help you build event-driven applications that ingest real- or near real-time data into cloud data warehouses. It does this by using Kafka Connect to stream Kafka topics to Amazon Redshift. Confluent Cloud offers elastic scaling and pricing that charges only for what you stream.
If you would like to learn more about Confluent Cloud, sign up for an account and get $200.00 USD off usage, each month for the first three months.
.

.
Confluent – AWS Partner Spotlight
Confluent is an AWS Advanced Technology Partner. Confluent Cloud provides a serverless way to help you build event-driven applications that ingest real- or near real-time data into cloud data warehouses.
Contact Confluent | Solution Overview | AWS Marketplace
*Already worked with Confluent? Rate the Partner
*To review an AWS Partner, you must be a customer that has worked with them directly on a project.