AWS Partner Network (APN) Blog
Provisioning a Virtual Private Cloud at Scale with AWS CDK
By Francois Rouxel, Solution Principal and APN Ambassador at Slalom
 Infrastructure as code (IaC) is one of the most important concepts used with cloud solutions. It provides a way to treat your infrastructure as if it were a coded application. The resulting code is stored in a repository and can be part of any CI/CD pipeline.
Infrastructure as code (IaC) is one of the most important concepts used with cloud solutions. It provides a way to treat your infrastructure as if it were a coded application. The resulting code is stored in a repository and can be part of any CI/CD pipeline.
Amazon Web Services (AWS) provides a tool to enable infrastructure as code, AWS CloudFormation, which deploys stacks and provisions your resources on AWS using JSON or YAML files called templates.
In this post, I will show you how to create 100 virtual private clouds (VPCs) in one AWS region without providing any parameters; the default limit is five VPCs per region. More, you will see how to easily establish a peering connection between two of them within a single line of code.
I am a Cloud Solutions Architect at Slalom and have been an APN Ambassador since early 2020. APN Ambassadors work closely with AWS Solutions Architects to migrate, design, implement, and monitor AWS workloads. I have been working in IT for 20 years and have oriented my interest and expertise in the cloud. My role at Slalom is focused on helping companies migrate to AWS.
Slalom is an AWS Premier Consulting Partner with multiple AWS Competency and Service Delivery designations. Slalom is a modern consulting firm focused on strategy, technology, and business transformation.
Here Comes the CDK
Writing an AWS CloudFormation template can be challenging sometimes, as it does not have a dynamic nature. For instance, it’s not possible to create a loop in the template to provision the same infrastructure (subnets and Network Access Control lists, for example) over many AWS Availability Zones.
The AWS Cloud Development Kit (CDK) is a tool that helps you create and deploy CloudFormation templates. CDK was released in October 2019 and offers valuable features like loops. In this post, you will see how to use some of those features to create and deploy VPCs at scale.
 VPC Peering
VPC Peering
A virtual private cloud (VPC) is an isolated private network in which you can provision resources. It can be peered or connected to another VPC or network on-premises.
Once your VPC is peered with another one, instances from the peered VPC can see all of the instances in your VPC. This, of course, depends on the security groups you may have configured, but if your peering connection is well set in your route tables, the connectivity is here.
Things to Consider When Creating a VPC
One main attribute of the VPC is its CIDR range (basically, it’s size). AWS recommends provisioning the biggest VPC you can, which is /16. For instance, you can create a VPC using 10.0.0.0/16, which means you can have up to 65,536 IPs from 10.0.0.0 to 10.0.255.255.
Things get complicated when you want to peer your VPCs with others that have overlapping CIDR ranges. In this case, the peering connection won’t succeed. This post shows you how to create VPCs without having to worry about this detail.
Solution Overview
In an IT project, it’s common to see many teams working on different features. A typical pattern is for each team to have a dedicated Git branch created from the main branch of the project. The CI/CD pipeline will build and deploy the solution for each branch.
In a case where there are two development teams, we could have two branches (dev1 and dev2), and the main branch (staging) would be the integration branch, where you will merge the feature of each team.
So, we are going to create three VPCs in the same account, in the same region:
- 2 dev VPCs (vpc[BD3] -dev-1 and vpc-dev-2)
- 1 staging VPC (vpc-staging)
- vpc-dev1 and vpc-dev2 will be peered to vpc-staging, but not between each other
Note that we could have chosen different accounts and regions. As an example, we could have deployed vpc-dev-1 and vpc-dev-2 in ca-central-1 in a development account, and vpc-staging in us-east-1, in a test account. Even with this setup, VPC peering is possible.
A custom resource (such as an AWS Lambda function) is used to know when all stacks are complete. This function will update the Amazon DynamoDB table to list all the VPC and subnets deployed during the process.
In the architecture diagram below, you see three stacks created from the CloudFormation templates:
- One stack for the custom resource to create the Lambda function that’s called when the deployment is complete.
- One stack to create the VPCs.
- One stack to peer vpc-dev-1 and vpc-dev-2 with vpc-staging; it means that an instance deployed in vpc-dev-1 (or vpc-dev-2) will be able to communicate with an instance in vpc-staging.
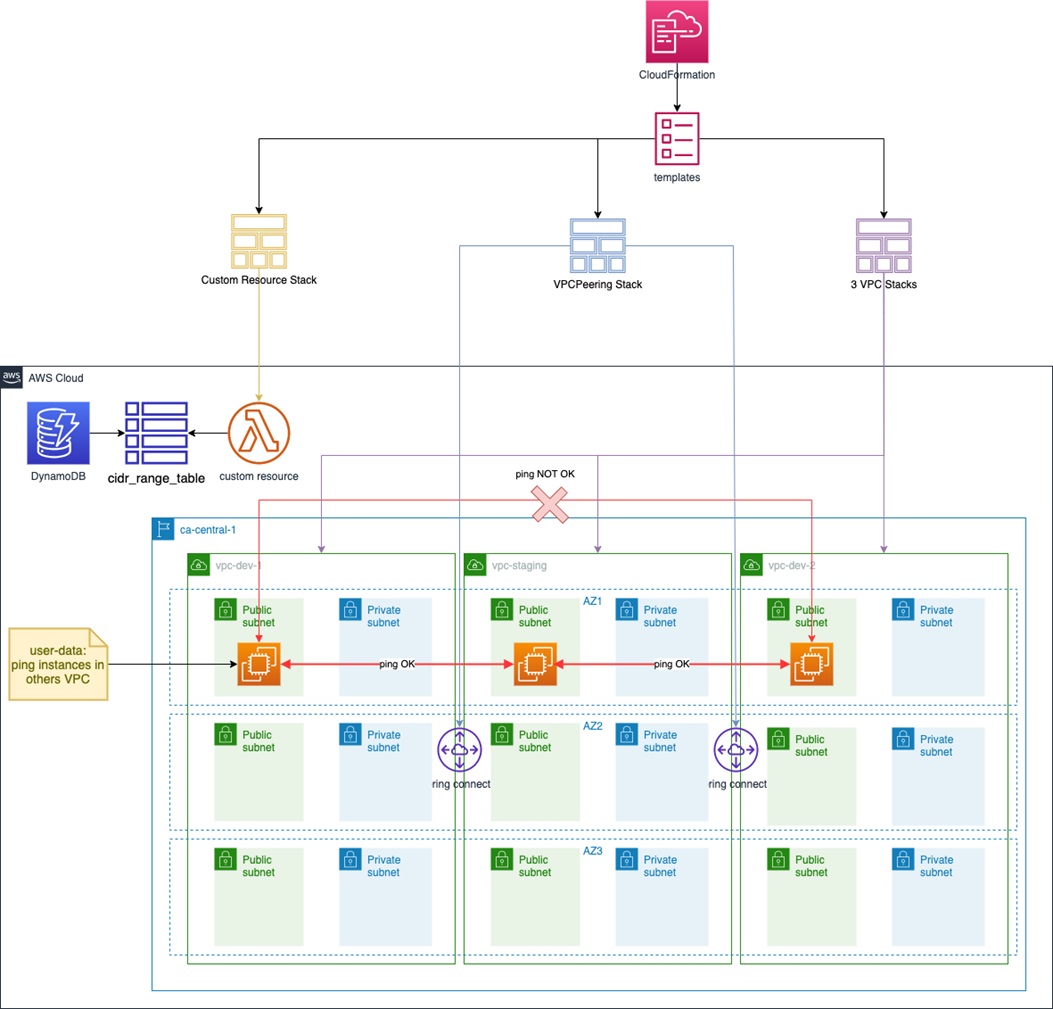
Figure 1 – Solution overview diagram.
Note that in the solution, the private subnets creation has been commented on purpose to get the solution deployed faster. Just uncomment the following lines to provision the private subnets (it will also provision Nat gateways):
VPC Peering Transitivity is Not Allowed
One important concept with AWS and peered VPCs is the non-transitivity of VPC peering. Take our three VPCs, for instance:
- vpc-dev-1 is peered with vpc-staging, which means connectivity between vpc-dev-1 and vpc-staging is possible.
- vpc-dev-2 is peered with vpc-staging, which means connectivity between vpc-dev-2 and vpc-staging is possible.
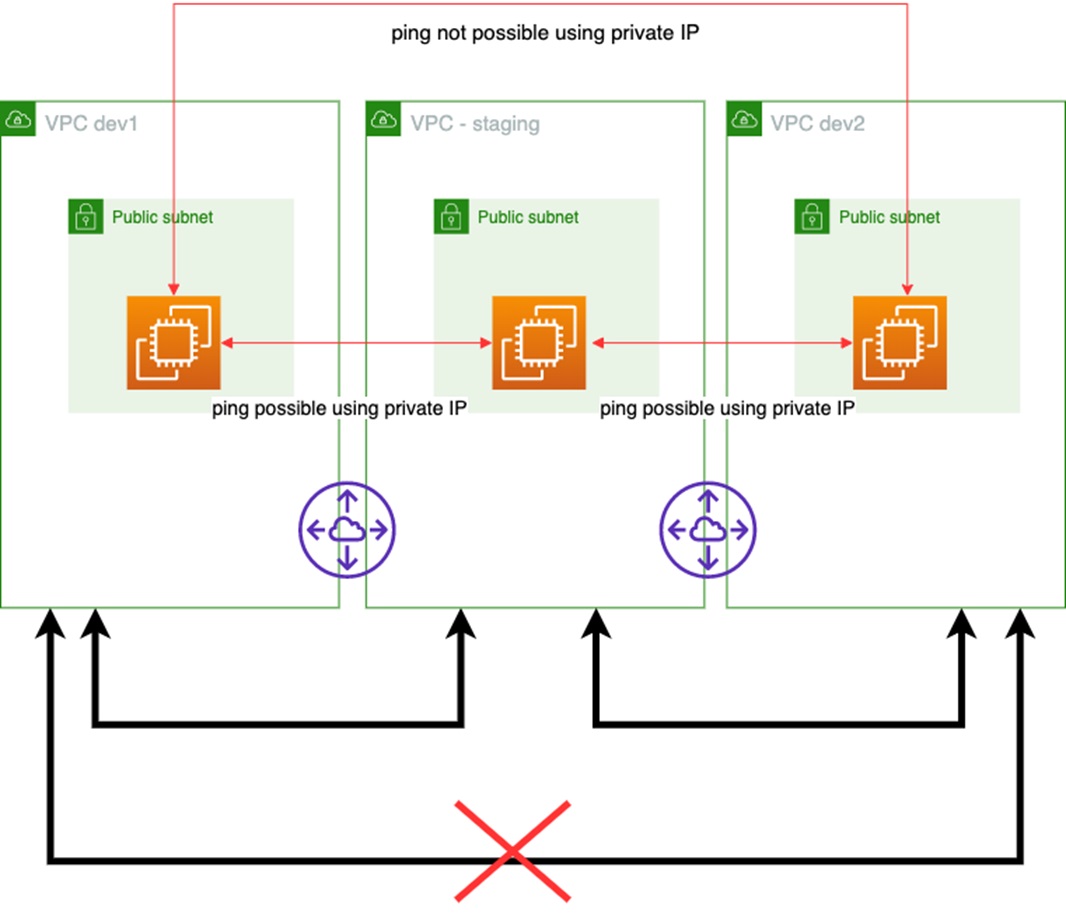
Figure 2 – Non-transitivity.
To verify this statement, the solution will deploy an Amazon Elastic Compute Cloud (Amazon EC2) instance in each VPC. Each EC2 instance will try to ping every minute the other instances, using their private IPs, and will output the result into one of our DynamoDB table.
Note that peering two VPCs together is not enough to make the ping possible. The solution makes sure the security group attached to each EC2 instance allows ICMP traffic within the three VPCs, and that each route table has a route that allows the networking connectivity.
What About CIDR Ranges?
Amazon DynamoDB is a very powerful NoSQL database and a perfect place to store key/value pairs. I will use it to store the VPC CIDR ranges and their subnets.
Two DynamoDB tables are created using CDK:
- cidr_range_table – Stores all the VPC info.
- last_cidr_range_table – Stores the last CIDR range used.
Getting Started
This post is a good opportunity to introduce AWS Cloud9, an Integrated Development Environment (IDE). AWS Cloud9 runs on either Amazon EC2 or your locale machine. One nice feature is that it comes with useful pre-installed tools like Git, Python, AWS Command Line Interface (CLI), or CDK.
Here are the steps to use AWS Cloud9:
- First, you need an AWS Identity and Access Management (IAM) user with admin permissions, as you cannot use your root account.
- Log in into your AWS account using your newly-created IAM user.
- Clone the repo (git clone https://github.com/rouxelec/cdk).
- Run this command:
source .env/bin/activate - Install dependencies :
pip install -r requirements.txt - Check if CDK is installed:
cdk –version
What Does Our CDK Project Look Like?
Once the repository is cloned, our file structure should look this:
Figure 3 – Project structure.
Amazon DynamoDB Tables
The first project “cdk-blog-dynamodb” is to provision the Amazon DynamoDB tables we are going to use to implement the solution. It will create two tables to store information about the three VPCs and their subnets we are going to provision later on.
DynamoDB is a NoSQL database, meaning there is no specific table schema pre-defined. This is useful when you want to describe in the same table different kinds of entities like VPCs or subnets.
Figure 4 – Amazon DynamoDB tables provisioning.
Two important files for the tables creation are:
- app.py – Declares the stack you want to build.
- setup.py – Adds required dependencies.
To launch the stack, just run cdk deploy.
Note that app.py only uses one stack, so you don’t have to specify the stack to deploy.
Let’s have a look at the stack:
This stack is supposed to create two DynamoDB tables:
- cidr_range_table – Used to keep tracks on used CIDR ranges for subnets and VPCs.
- last_cidr_range_table – Used to store the last used CIRDR range.
Let’s deploy the stack by running the following command:
cdk deploy cdk-blog-dynamodb --require-approval never
Once the stack status is complete, you should be able to see it through the console.

Figure 5 – Amazon DynamoDB tables in the AWS console.
Virtual Private Clouds
The goal here is to provision VPCs without worrying about CIDR ranges.
Let’s have a look at the stack:
Figure 6 – VPC project structure.
Now, let’s dig deeper in app.py where the VPC stacks are created.
Stack Creation
We can see three stacks:
- CdkBlogVpcStack – VPC stack used to provision VPCs.
- CdkBlogVpcPeeringStack – VPC peering stack used to peer two VPCs together.
- CdkBlogMyCustomResourceStack – Custom resource stack used to know when the stack is complete.
- EC2InstanceStack – Provision Amazon EC2 instance.
If we take a closer look the Custom Resource stack, we can see that we are provisioning a Lambda function:
The code associated with this Lambda function is available in the AWS Lambda folder. In this example, I might have given too much permission to simplify the overall solution, but you may want to restrict a little bit the resources for each different possible action.
The following IAM role shows the permissions used to execute the Lambda function:
This Lambda function needs permissions to describe the newly created VPCs and their peering connections.
Note that in this example, the Lambda function created the required routes in the route tables associated of each public subnet when a VPC peering connection is active. Even if the CDK can create routes, this option has not been applied as it would create a circular dependency (the VPC peering stack has a dependency on the VPC stacks).
Adding the routes in the route tables would have made the VPC stacks creation conditional to the VPC peering stack creation, which results on a circular dependency.
Creating the VPCs
In the cdk-blog-vpc folder, enter the following command:
cdk deploy cdk-blog* --require-approval never
Once the provisioning is complete, you should see this in the output:
cdk-blog-custom-resource2.ResponseMessage = You said "CustomResource is done"
After about one minute, the DynamoDB table should show the ping results between EC2 instances.
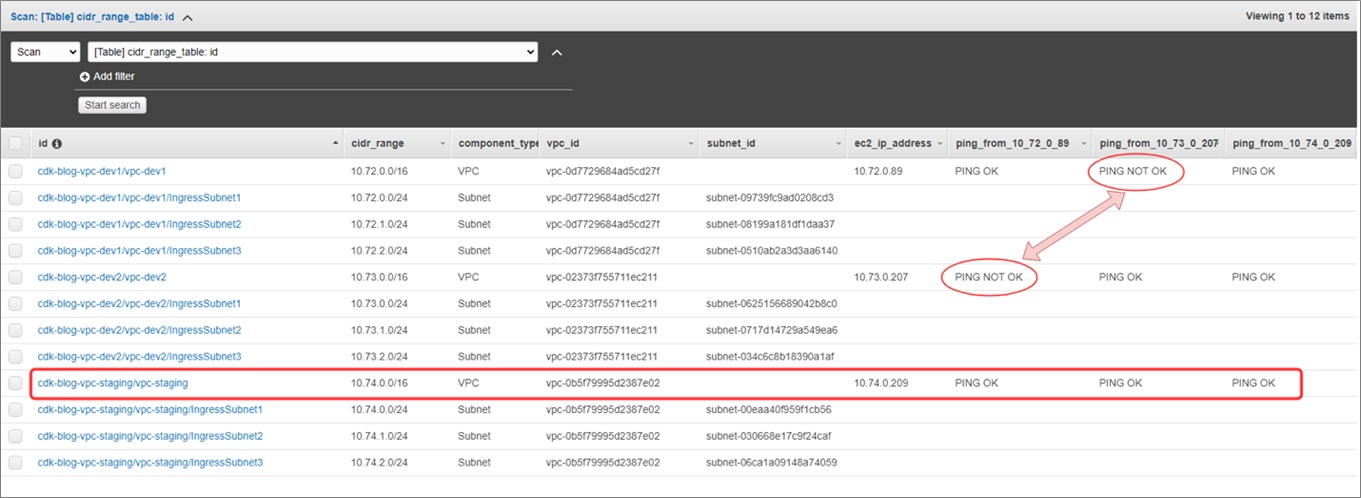
Figure 7 – Ping between Amazon EC2 instances.
We can see the EC2 instance deployed in the vpc-staging can ping the two instances deployed in vpc-dev-1 and vpc-dev-2. However, the instance deployed in vpc-dev-1 cannot ping the EC2 instance deployed in vpc-dev-2, and vice-versa, which proves that the non-transitivity with VPC peering.
About Non-Transitivity with VPC Peerings
To be able to prove the non-transitivity with VPC peering, I had to add specific routes to the route tables. Since it’s optional (demonstration purpose), I added comments surrounding the code that should be removed.
The following snippet creates the specific route:
In the image below, you can see that a specific route (with a /32) has been added by the code above.

Figure 8 – VPC route table.
Conclusion
In this post, you saw how easy it can be to deploy virtual private clouds using the AWS Cloud Development Kit (CDK). This solution proposes an elegant way to avoid overlapping CIDR ranges that prevent you from peering VPCs together.
This post was also a good opportunity to introduce AWS Cloud9, a powerful integrated development environment (IDE) that comes with the CDK and the AWS CLI already installed.
Moreover, this post could be used as a workshop to demonstrate the non-transitivity of VPC peering.
The content and opinions in this blog are those of the third party author and AWS is not responsible for the content or accuracy of this post.
.

.
Slalom – AWS Partner Spotlight
Slalom is an AWS Premier Consulting Partner. A modern consulting firm focused on strategy, technology, and business transformation, Slalom’s teams are backed by regional innovation hubs, a global culture of collaboration, and partnerships with the world’s top technology providers.
Contact Slalom | Practice Overview
*Already worked with Slalom? Rate the Partner
*To review an APN Partner, you must be an AWS customer that has worked with them directly on a project.