AWS Partner Network (APN) Blog
Unlocking the Value of Your Contact Center Data with TrueVoice Speech Analytics from Deloitte
By Daniele Barchiesi, Head of Data Science at TrueVoice
By William Ying, Sr. Partner Solutions Architect at AWS
![]() What are the main reasons customers are contacting your call center? What makes them happy about your products, and what’s driving their complaints?
What are the main reasons customers are contacting your call center? What makes them happy about your products, and what’s driving their complaints?
These are questions we are tackling for clients with the help of TrueVoice, Deloitte’s speech analytics solution that can improve customer experience and operational efficiency in contact centers.
Machine learning (ML) plays a pivotal role in making this possible by modeling business outcomes such as call resolution, reason for contact, and compliance risk for businesses that operate in heavily regulated areas such as financial services.
Working on speech data in a variety of industries with clients at different levels of technological maturity presents specific challenges. In this post, I will open the lid on what constitutes TrueVoice’s machine learning engine, and relate the data science to the business objectives our clients are pursuing.
Deloitte’s TrueVoice is powered by Amazon Web Services (AWS) infrastructure and is available via AWS Quick Start so you can quickly deploy the solution to your organization.
Deloitte is an AWS Partner Network (APN) Premier Consulting Partner and Managed Services Provider (MSP) with multiple AWS Competencies and AWS Service Delivery designations.
Modeling Principles: Multi-Modal Indicators and Explainable Predictions
It’s not just what you say, but how you say it that matters. Evolution has given us a subtle, kaleidoscopic variety of ways to express emotions, opinions, concerns, and requests.
In the age of social media and recommendation engines, companies are striving to build personal relationships with their customers. While people are naturally attuned to the complexity of human communications, understanding patterns of behavior at scale is impossible without the use of the right technology.
Whether we’re modeling emotions, complaints, or agents pressuring their clients into buying a product, we generally choose to employ multi-modal indicators derived from the audio signal (how you say it) and its speech to text transcription (what you say).
These two streams are processed in different ways to derive complementary features for our ML models. This includes audio-based indicators like pitch, intensity, pauses, speech rate and the output of an audio-based ML emotion model; text-based indicators like text search queries and latent semantic analysis; and metadata such as call position and duration or operational meta-data.
Audio-based indicators are particularly useful to capture non-verbal cues that express heightened emotional content in a conversation, hesitation, or interruption. Text-based indicators are all about what’s said during the call (search queries) and the context in which things are said (latent semantic analysis).
Finally, metadata adds a rule-based layer to a model’s decision; for instance, some outcomes tend to appear at the beginning or at the end of a call, or are more likely to appear in outbound calls compared to inbound calls.
Having extracted fairly complex features, some of which are themselves the outputs of ML models, our estimators tend to be relatively simple and interpretable models, such as logistic regression or support vector machines.
This gives us the advantage of quickly diagnosing why a model is making certain decisions and why a model may generalize or not across different datasets.
In the table below, you see a partial example extracted from the complaint model explanations. Here, type describes the category of the indicator, value is the name or label of the feature, and variable contribution indicates whether the feature contributes positively or negatively to the model’s complaint identification and by how much.
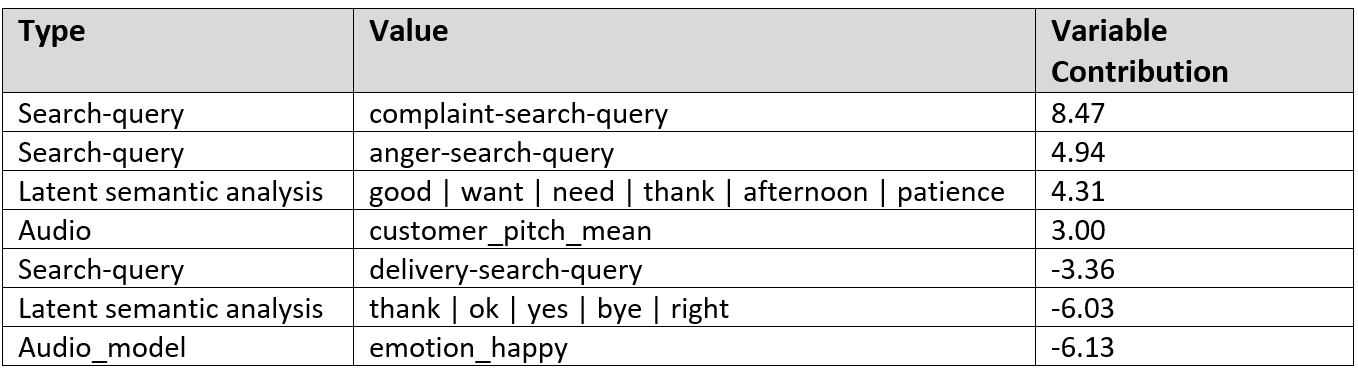
Figure 1 – Partial example extracted from the complaint model explanations.
Complaint and anger search queries feature as the top contributors to a complaint prediction, while audio-based happiness is the top contributor against a complaint prediction.
The two latent semantic analysis features exemplify the impact of different contexts to the prediction—the positive one refers to a situation where an agent greets a customer after they’ve been put on hold, while the negative one refers to a customer thanking an operator and closing the conversation.
Pitch is also positively associated with a complaint prediction, which is consistent with a raised level of emotional arousal.
Outcomes, Technological Maturity, and Modeling Choices
At TrueVoice, we endeavor to serve clients that are at different stages of technological maturity. Some are just starting to leverage voice data while others are well on their way to building a complex omni-channel view of their customers.
Moreover, some outcomes are inherently easier to model than others. For this reason, each of the ML models we build can be seen in light of the following criteria.
Outcome Complexity
Some contact center conversations need to include mandatory disclosures aimed at satisfying regulatory or quality assurance requirements. These are an example of outcomes that tend to be relatively easy to model provided an adequate audio quality, and do not typically rely on multi-modal indicators.
Other modeling outcomes, such as emotions or complaints, are more subtle and require all of the tools at our disposal to be properly addressed.
Model Footprint
Some models, such as specific disclosures, may only be applicable to individual TrueVoice clients, while others are generic enough to be applicable across different industries.
Model Maturity
As a result of outcome complexity and model footprint, our models typically follow a maturity path consisting of:
- Initial rule-based models: Generated using search queries in collaboration with our industry experts, these constitute baselines for models that require less complexity or are less generalizable across clients and industries.
- Initial ML-based models: Usually provided as an output following a proof of value phase, these are created by tagging and modeling specific outcomes and may use a variety of indicators including audio and text-based features.
- ML feedback loop: Once our models are in production, they enter their most mature phase where performance is periodically monitored based on new tags, and where models are continuously improved according to a framework comprising five levels of model refinement from simple re-training to complete re-engineering.
Machine Learning vs. Business Performance
Our tech stack includes auto-scalable dockerized microservices on Amazon Elastic Container Service (Amazon ECS) to process data, and the ability to train machine learning models using Amazon SageMaker.
Our training protocols follow typical ML best practices such as cross-validation, hyperparameter tuning, model diagnostics, and performance evaluation reports. This is crucial to ensure we build the best possible models from a technical point of view.
At TrueVoice, we work with clients to understand how using our models will impact their business operations, and help them move forward in their journey towards building data-centric organizations.
In the context of binary classification models, which feature in the majority of our use cases, this often means carefully handling the balance between precision and recall to address the following scenarios.
Risk-Based Sampling
Many of our clients are interested in reviewing phone conversations and identifying outcomes of interest to better understand their customers, or to ensure they comply with regulations.
Many organizations review less than 1 percent of their calls and select them at random, meaning that rare events almost never appear in front of a reviewer. For instance, a bank may review calls to spot irregularities in the way they sell mortgages. But if those irregularities only appear in a small proportion of situations, its reviewers will be unable to identify the issue and remediate it.
TrueVoice selects a risk-based sample of calls to review that are most likely to contain irregularities based on ML models. Our solution ranks models’ decisions from the most confident to least confident, prioritizing precision over recall.
Figure 2 below shows an example of risk-based sampling on a small subset of 70 calls selected at random. The baseline incidence of the outcome of interest is around 50 percent, as highlighted by the median risk-based sampling when rank=70 (referring to the whole random sample).
On the other hand, selecting the top 10 calls from this sample according to our model’s scores results in 90 percent median incidence of the outcome of interest. Violin plots display distributions across different cross-validation folds.
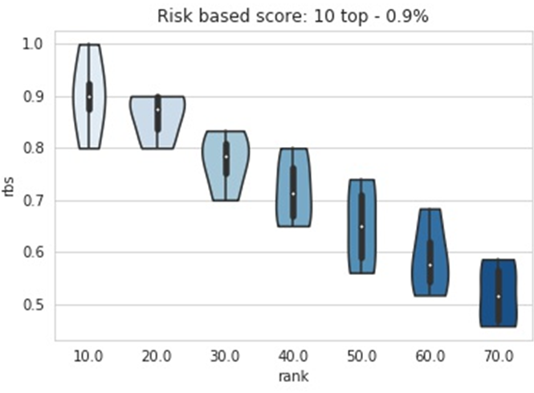
Figure 2 – Risk-based sampling results.
Benchmarking
Another common scenario is benchmarking, which provides an unbiased estimate of the occurrence of a certain event.
A retailer offering products from different brands, for instance, may want to know the percentage of complaints each brand receives from customers, or what percentage of calls result in issues being resolved.
In this situation, our models that identify different outcome—such as call resolution and complaints—cannot favor precision over recall. This would under-estimate the overall occurrence of that outcome by selecting only the cases where the model provides a very confident prediction.
On the other hand, our models cannot favor recall over precision or the opposite effect would take place, and the overall occurrence of that outcome would be over-estimated. Instead, we need to set models’ thresholds at a value that minimizes the difference between precision and recall to ensure an unbiased estimate of that outcome.
Moreover, we find that when models with a large footprint are applied across different customers or industries, thresholds need to be tuned to maintain this balance of precision versus recall.
In Figure 3 below, you see an example of threshold tuning. The current threshold results in poor recall and an underestimation of the overall occurrence of this outcome. Moving the threshold to circa -0.65 balances the trade-off between precision and recall.
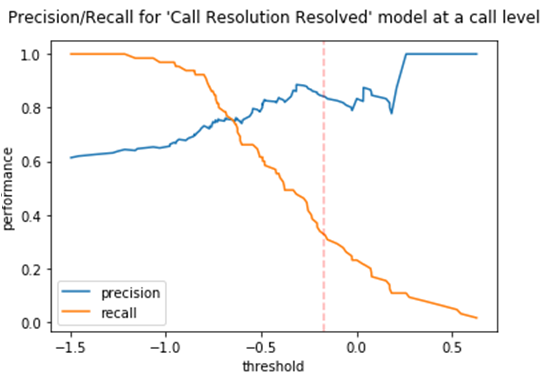
Figure 3 – Precision/recall trade-off and threshold tuning.
Leveraging AWS for the Analysis of Voice Data
Model development and management, which are at the core of the TrueVoice technology, are carried out by leveraging a variety of AWS services that allow us to build robust, scalable services deployed in multiple geographic zones to serve clients across different jurisdictions.
AWS services powering TrueVoice include:
- Amazon SageMaker for the training and refinement of ML models.
- Amazon Simple Storage Service (Amazon S3) for data storage across our data lake.
- AWS Lambda and AWS Glue for extract, transform, load (ETL) tasks.
- AWS Simple Queue Service (SQS) to manage task queues.
- Amazon Athena to create a data aggregation layer fed by the output of ETL tasks.
Figure 4 displays some of the main cloud computing services used by TrueVoice. Audio files are transcribed and processed by the TrueVoice machine learning scoring service.
The features driving ML predictions are saved to a data lake for model management, along with model scores and tags used for supervised learning. Model training and refinement is carried out using AWS Glue to perform ETL tasks and AWS SageMaker for running ML algorithms. Results and reports are produced using AWS Athena.

Figure 4 – The AWS-TrueVoice model management architecture.
Deployment
As part of the TrueVoice Registration and Integration on AWS Quick Start, you will provide information about your business and the TrueVoice services you want to use.
Next, Deloitte will share an AWS Service Catalog product for launching TrueVoice proof of value integration resources. The final step is for Deloitte to run a two-hour workshop with you to review target use cases and outcomes in order to establish success metrics.
In Figure 5 below, you see how a registration stack consisting of a Custom Resource Lambda function will invoke the TrueVoice proof of value registration API and return a registration ID as an AWS CloudFormation output.
An AWS Service Catalog product will be made available to the account from where the Quick Start will be launched. This provides a template that sets up an Amazon S3 bucket intended for integration with customer-dedicated resources in the TrueVoice AWS account. It’s also used as a staging area for audio files sourced from on-premises telephony systems or Amazon Connect.
An AWS Lambda function will be tasked with transferring files from the customer’s integration bucket to the TrueVoice AWS account.

Figure 5 – Architecture for the TrueVoice proof of value integration on AWS.
Summary
Voice data represents a rich and relatively untapped source of information that can help organizations gaining precious insights into their customers and operations.
By leveraging a number of AWS services, TrueVoice can process voice data at scale, apply machine learning models to extract valuable information for this unstructured data, and continuously refine and enrich such models, tailoring them to specific industries and business needs.
From a data science standpoint, processing audio and building multi-modal models on noisy datasets presents great challenges. It’s also an opportunity to push the boundaries of what technology can do when married with deep business expertise.
By working closely with clients, understanding and advising on how knowledge extracted from voice data can improve customer experience and operational efficiency, machine learning and technology are employed at the service of measurable business outcomes.
To learn more about TrueVoice, see the TrueVoice Registration and Integration on AWS Quick Start.
.

.
Deloitte – APN Partner Spotlight
Deloitte is an APN Premier Consulting Partner. Through a network of professionals, industry specialists, and an ecosystem of alliances, they assist clients in turning complex business issues into opportunities for growth, helping organizations transform in the digital era.
Contact Deloitte | Solution Overview | AWS Quick Start
*Already worked with Deloitte? Rate this Partner
*To review an APN Partner, you must be an AWS customer that has worked with them directly on a project.