AWS Big Data Blog
Category: AWS Glue

Dive deep into AWS Glue 4.0 for Apache Spark
Jul 2023: This post was reviewed and updated with Glue 4.0 support in AWS Glue Studio notebook and interactive sessions. Deriving insight from data is hard. It’s even harder when your organization is dealing with silos that impede data access across different data stores. Seamless data integration is a key requirement in a modern data […]

Ten new visual transforms in AWS Glue Studio
AWS Glue Studio is a graphical interface that makes it easy to create, run, and monitor extract, transform, and load (ETL) jobs in AWS Glue. It allows you to visually compose data transformation workflows using nodes that represent different data handling steps, which later are converted automatically into code to run. AWS Glue Studio recently […]

Scale your AWS Glue for Apache Spark jobs with larger worker types G.4X and G.8X
Hundreds of thousands of customers use AWS Glue, a serverless data integration service, to discover, prepare, and combine data for analytics, machine learning (ML), and application development. AWS Glue for Apache Spark jobs work with your code and configuration of the number of data processing units (DPU). Each DPU provides 4 vCPU, 16 GB memory, […]
Process price transparency data using AWS Glue
The Transparency in Coverage rule is a federal regulation in the United States that was finalized by the Center for Medicare and Medicaid Services (CMS) in October 2020. The rule requires health insurers to provide clear and concise information to consumers about their health plan benefits, including costs and coverage details. Under the rule, health […]

Compose your ETL jobs for MongoDB Atlas with AWS Glue
In today’s data-driven business environment, organizations face the challenge of efficiently preparing and transforming large amounts of data for analytics and data science purposes. Businesses need to build data warehouses and data lakes based on operational data. This is driven by the need to centralize and integrate data coming from disparate sources. At the same […]

Monitor and optimize cost on AWS Glue for Apache Spark
AWS Glue is a serverless data integration service that makes it simple to discover, prepare, and combine data for analytics, machine learning (ML), and application development. You can use AWS Glue to create, run, and monitor data integration and ETL (extract, transform, and load) pipelines and catalog your assets across multiple data stores. One of […]

How the BMW Group analyses semiconductor demand with AWS Glue
This is a guest post co-written by Maik Leuthold and Nick Harmening from BMW Group. The BMW Group is headquartered in Munich, Germany, where the company oversees 149,000 employees and manufactures cars and motorcycles in over 30 production sites across 15 countries. This multinational production strategy follows an even more international and extensive supplier network. Like many automobile companies across the world, the […]

Cross-account integration between SaaS platforms using Amazon AppFlow
Implementing an effective data sharing strategy that satisfies compliance and regulatory requirements is complex. Customers often need to share data between disparate software as a service (SaaS) platforms within their organization or across organizations. On many occasions, they need to apply business logic to the data received from the source SaaS platform before pushing it […]
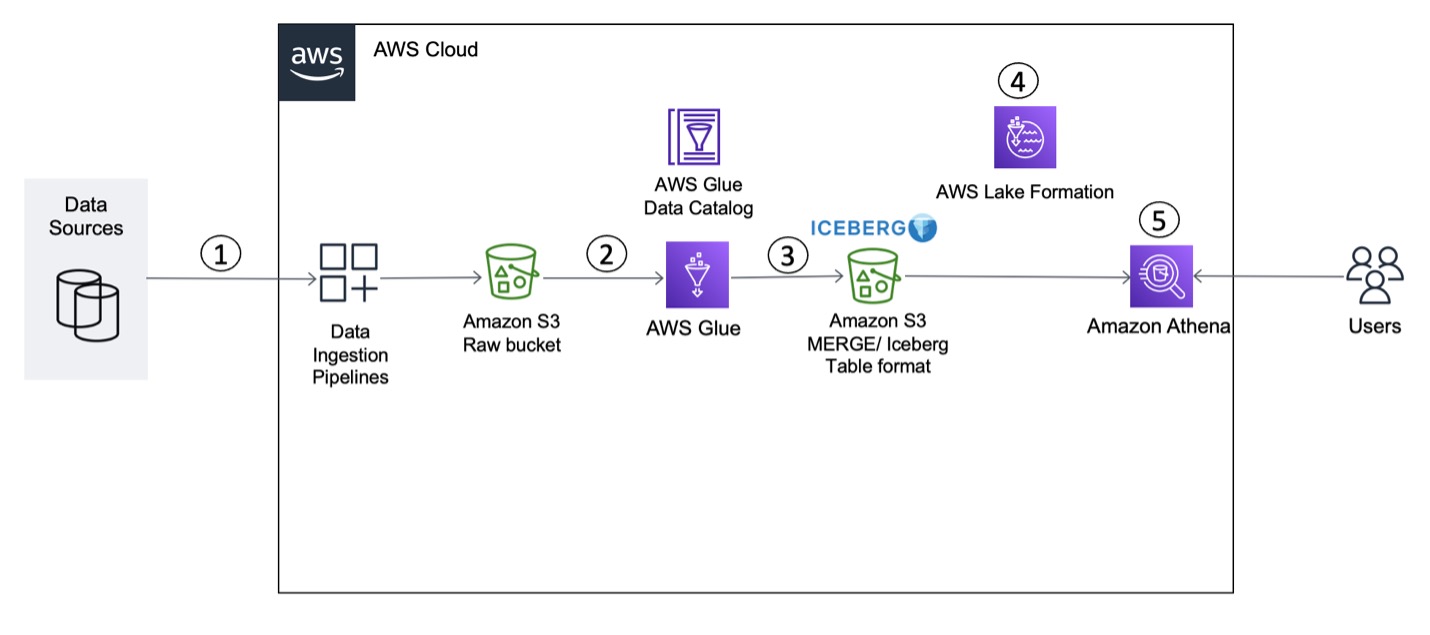
Build a transactional data lake using Apache Iceberg, AWS Glue, and cross-account data shares using AWS Lake Formation and Amazon Athena
Building a data lake on Amazon Simple Storage Service (Amazon S3) provides numerous benefits for an organization. It allows you to access diverse data sources, build business intelligence dashboards, build AI and machine learning (ML) models to provide customized customer experiences, and accelerate the curation of new datasets for consumption by adopting a modern data […]

Exploring new ETL and ELT capabilities for Amazon Redshift from the AWS Glue Studio visual editor
In a modern data architecture, unified analytics enable you to access the data you need, whether it’s stored in a data lake or a data warehouse. In particular, we have observed an increasing number of customers who combine and integrate their data into an Amazon Redshift data warehouse to analyze huge data at scale and […]