AWS Big Data Blog
Category: Technical How-to
Process price transparency data using AWS Glue
The Transparency in Coverage rule is a federal regulation in the United States that was finalized by the Center for Medicare and Medicaid Services (CMS) in October 2020. The rule requires health insurers to provide clear and concise information to consumers about their health plan benefits, including costs and coverage details. Under the rule, health […]

Compose your ETL jobs for MongoDB Atlas with AWS Glue
In today’s data-driven business environment, organizations face the challenge of efficiently preparing and transforming large amounts of data for analytics and data science purposes. Businesses need to build data warehouses and data lakes based on operational data. This is driven by the need to centralize and integrate data coming from disparate sources. At the same […]

Build an analytics pipeline for a multi-account support case dashboard
As organizations mature in their cloud journey, they have many accounts (even hundreds) that they need to manage. Imagine having to manage support cases for these accounts without a unified dashboard. Administrators have to access each account either by switching roles or with single sign-on (SSO) in order to view and manage support cases. This […]

Real-time anomaly detection via Random Cut Forest in Amazon Managed Service for Apache Flink
August 30, 2023: Amazon Kinesis Data Analytics has been renamed to Amazon Managed Service for Apache Flink. Read the announcement in the AWS News Blog and learn more. Real-time anomaly detection describes a use case to detect and flag unexpected behavior in streaming data as it occurs. Online machine learning (ML) algorithms are popular for […]

Monitor and optimize cost on AWS Glue for Apache Spark
AWS Glue is a serverless data integration service that makes it simple to discover, prepare, and combine data for analytics, machine learning (ML), and application development. You can use AWS Glue to create, run, and monitor data integration and ETL (extract, transform, and load) pipelines and catalog your assets across multiple data stores. One of […]

Perform upserts in a data lake using Amazon Athena and Apache Iceberg
Amazon Athena supports the MERGE command on Apache Iceberg tables, which allows you to perform inserts, updates, and deletes in your data lake at scale using familiar SQL statements that are compliant with ACID (Atomic, Consistent, Isolated, Durable). Apache Iceberg is an open table format for data lakes that manages large collections of files as […]

Working with percolators in Amazon OpenSearch Service
Amazon OpenSearch Service is a managed service that makes it easy to secure, deploy, and operate OpenSearch and legacy Elasticsearch clusters at scale in the AWS Cloud. Amazon OpenSearch Service provisions all the resources for your cluster, launches it, and automatically detects and replaces failed nodes, reducing the overhead of self-managed infrastructures. The service makes it […]

How Dafiti made Amazon QuickSight its primary data visualization tool
This is a guest post by Valdiney Gomes, Hélio Leal, and Flávia Lima from Dafiti. Data and its various uses is increasingly evident in companies, and each professional has their preferences about which technologies to use to visualize data, which isn’t necessarily in line with the technological needs and infrastructure of a company. At Dafiti, […]
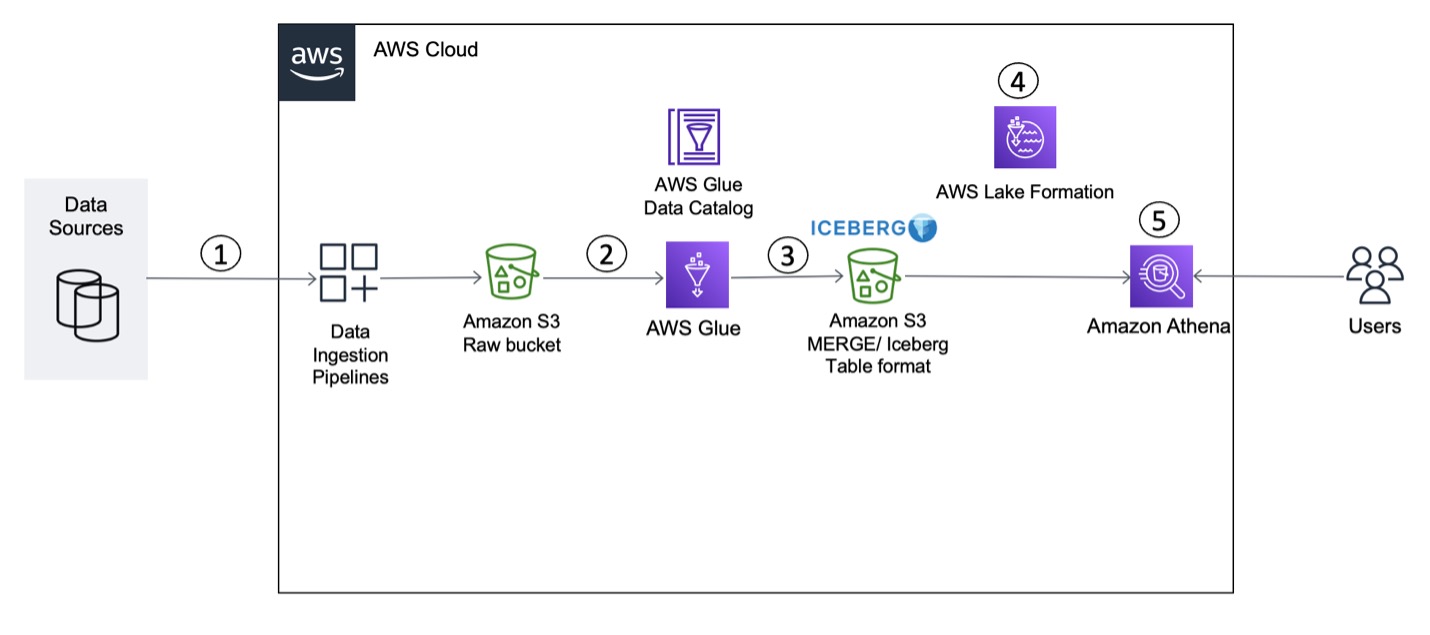
Build a transactional data lake using Apache Iceberg, AWS Glue, and cross-account data shares using AWS Lake Formation and Amazon Athena
Building a data lake on Amazon Simple Storage Service (Amazon S3) provides numerous benefits for an organization. It allows you to access diverse data sources, build business intelligence dashboards, build AI and machine learning (ML) models to provide customized customer experiences, and accelerate the curation of new datasets for consumption by adopting a modern data […]

Automate discovery of data relationships using ML and Amazon Neptune graph technology
Data mesh is a new approach to data management. Companies across industries are using a data mesh to decentralize data management to improve data agility and get value from data. However, when a data producer shares data products on a data mesh self-serve web portal, it’s neither intuitive nor easy for a data consumer to […]