AWS Big Data Blog
Category: Technical How-to

How Wallapop improved performance of analytics workloads with Amazon Redshift Serverless and data sharing
Amazon Redshift is a fast, fully managed cloud data warehouse that makes it straightforward and cost-effective to analyze all your data at petabyte scale, using standard SQL and your existing business intelligence (BI) tools. Today, tens of thousands of customers run business-critical workloads on Amazon Redshift. Amazon Redshift Serverless makes it effortless to run and […]

Simplifying data processing at Capitec with Amazon Redshift integration for Apache Spark
This post is co-written with Preshen Goobiah and Johan Olivier from Capitec. Apache Spark is a widely-used open source distributed processing system renowned for handling large-scale data workloads. It finds frequent application among Spark developers working with Amazon EMR, Amazon SageMaker, AWS Glue and custom Spark applications. Amazon Redshift offers seamless integration with Apache Spark, […]

Create a modern data platform using the Data Build Tool (dbt) in the AWS Cloud
Building a data platform involves various approaches, each with its unique blend of complexities and solutions. A modern data platform entails maintaining data across multiple layers, targeting diverse platform capabilities like high performance, ease of development, cost-effectiveness, and DataOps features such as CI/CD, lineage, and unit testing. In this post, we delve into a case […]
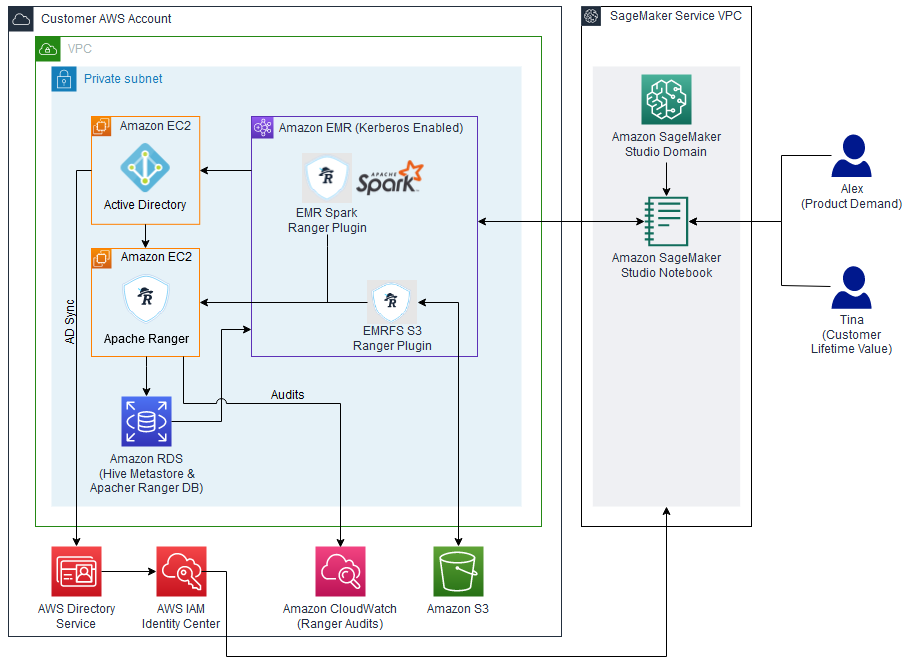
Implement fine-grained access control in Amazon SageMaker Studio and Amazon EMR using Apache Ranger and Microsoft Active Directory
In this post, we show how you can authenticate into SageMaker Studio using an existing Active Directory (AD), with authorized access to both Amazon S3 and Hive cataloged data using AD entitlements via Apache Ranger integration and AWS IAM Identity Center (successor to AWS Single Sign-On). With this solution, you can manage access to multiple SageMaker environments and SageMaker Studio notebooks using a single set of credentials. Subsequently, Apache Spark jobs created from SageMaker Studio notebooks will access only the data and resources permitted by Apache Ranger policies attached to the AD credentials, inclusive of table and column-level access.

Use IAM runtime roles with Amazon EMR Studio Workspaces and AWS Lake Formation for cross-account fine-grained access control
Amazon EMR Studio is an integrated development environment (IDE) that makes it straightforward for data scientists and data engineers to develop, visualize, and debug data engineering and data science applications written in R, Python, Scala, and PySpark. EMR Studio provides fully managed Jupyter notebooks and tools such as Spark UI and YARN Timeline Server via […]

An automated approach to perform an in-place engine upgrade in Amazon OpenSearch Service
Software upgrades bring new features and better performance, and keep you current with the software provider. However, upgrades for software services can be difficult to complete successfully, especially when you can’t tolerate downtime and when the new version’s APIs introduce breaking changes and deprecation that you must remediate. This post shows you how to upgrade […]

Create, train, and deploy Amazon Redshift ML model integrating features from Amazon SageMaker Feature Store
Amazon Redshift is a fast, petabyte-scale, cloud data warehouse that tens of thousands of customers rely on to power their analytics workloads. Data analysts and database developers want to use this data to train machine learning (ML) models, which can then be used to generate insights on new data for use cases such as forecasting […]

Enable cost-efficient operational analytics with Amazon OpenSearch Ingestion
As the scale and complexity of microservices and distributed applications continues to expand, customers are seeking guidance for building cost-efficient infrastructure supporting operational analytics use cases. Operational analytics is a popular use case with Amazon OpenSearch Service. A few of the defining characteristics of these use cases are ingesting a high volume of time series […]

Unstructured data management and governance using AWS AI/ML and analytics services
In this post, we discuss how AWS can help you successfully address the challenges of extracting insights from unstructured data. We discuss various design patterns and architectures for extracting and cataloging valuable insights from unstructured data using AWS. Additionally, we show how to use AWS AI/ML services for analyzing unstructured data.

Run Spark SQL on Amazon Athena Spark
At AWS re:Invent 2022, Amazon Athena launched support for Apache Spark. With this launch, Amazon Athena supports two open-source query engines: Apache Spark and Trino. Athena Spark allows you to build Apache Spark applications using a simplified notebook experience on the Athena console or through Athena APIs. Athena Spark notebooks support PySpark and notebook magics […]